




Ksenia Se
@kseniase.bsky.social
Writing TuringPost.com, learning and educating about machine learning and AI.
Working on a book about Citizen Diplomacy.
Living in the woods.
Also - being mom to four boys and one baby girl 🤘🏻
Working on a book about Citizen Diplomacy.
Living in the woods.
Also - being mom to four boys and one baby girl 🤘🏻
If you're building with agents, or planning to, this is the protocol to watch.
In our deep dive into A2A you'll learn how it works and how to start with it, whether MCP and A2A are competitors, and if Google might use it to index every agent on the internet 👇
Enjoy and leave your feedback!
In our deep dive into A2A you'll learn how it works and how to start with it, whether MCP and A2A are competitors, and if Google might use it to index every agent on the internet 👇
Enjoy and leave your feedback!

🦸🏻#17: What is A2A and why is it – still! – underappreciated?
A Blog post by Ksenia Se on Hugging Face
huggingface.co
May 10, 2025 at 8:45 AM
If you're building with agents, or planning to, this is the protocol to watch.
In our deep dive into A2A you'll learn how it works and how to start with it, whether MCP and A2A are competitors, and if Google might use it to index every agent on the internet 👇
Enjoy and leave your feedback!
In our deep dive into A2A you'll learn how it works and how to start with it, whether MCP and A2A are competitors, and if Google might use it to index every agent on the internet 👇
Enjoy and leave your feedback!
• Specialist agents working together like modular teams
• Easy cross-enterprise workflows
• Standardized human-in-the-loop collaboration between AI and people
• And even a searchable, internet-scale agents directory
• Easy cross-enterprise workflows
• Standardized human-in-the-loop collaboration between AI and people
• And even a searchable, internet-scale agents directory
May 10, 2025 at 8:45 AM
• Specialist agents working together like modular teams
• Easy cross-enterprise workflows
• Standardized human-in-the-loop collaboration between AI and people
• And even a searchable, internet-scale agents directory
• Easy cross-enterprise workflows
• Standardized human-in-the-loop collaboration between AI and people
• And even a searchable, internet-scale agents directory
Why is A2A important?
Most AI agents today live in silos. @Google’s A2A protocol aims to be the “common language” that lets them to collaborate.
A2A could unlock many possibilities:
Most AI agents today live in silos. @Google’s A2A protocol aims to be the “common language” that lets them to collaborate.
A2A could unlock many possibilities:
May 10, 2025 at 8:45 AM
Why is A2A important?
Most AI agents today live in silos. @Google’s A2A protocol aims to be the “common language” that lets them to collaborate.
A2A could unlock many possibilities:
Most AI agents today live in silos. @Google’s A2A protocol aims to be the “common language” that lets them to collaborate.
A2A could unlock many possibilities:
Hyena Edge is an experimental convolutional multi-hybrid model, It runs efficiently on smaller devices like your phone. At its core, it replaces 2/3 of attention with fast convolutions and gating
And Liquid AI are working on something even more interesting
How can their models beat Transformers? 👇
And Liquid AI are working on something even more interesting
How can their models beat Transformers? 👇

Can Liquid Models Beat Transformers? Meet Hyena Edge – the Newest Member of the LFM Family
we discuss a new wave of architecture from Liquid AI – built from first principles, optimized for real hardware, and challenging the Transformer playbook with smarter, leaner models
www.turingpost.com
May 5, 2025 at 8:33 AM
Hyena Edge is an experimental convolutional multi-hybrid model, It runs efficiently on smaller devices like your phone. At its core, it replaces 2/3 of attention with fast convolutions and gating
And Liquid AI are working on something even more interesting
How can their models beat Transformers? 👇
And Liquid AI are working on something even more interesting
How can their models beat Transformers? 👇
Podcasts:
YouTube www.youtube.com/@RealTuringP...
Spotify open.spotify.com/show/2SQxCUR...
Apple podcasts.apple.com/us/podcast/i...
YouTube www.youtube.com/@RealTuringP...
Spotify open.spotify.com/show/2SQxCUR...
Apple podcasts.apple.com/us/podcast/i...

Turing Post
"When Will We…"
A thought-provoking interview series with today’s leading AI innovators. We connect the dots between cutting-edge research, key concepts, and the moment when future technologies become...
www.youtube.com
May 4, 2025 at 11:13 PM
Podcasts:
YouTube www.youtube.com/@RealTuringP...
Spotify open.spotify.com/show/2SQxCUR...
Apple podcasts.apple.com/us/podcast/i...
YouTube www.youtube.com/@RealTuringP...
Spotify open.spotify.com/show/2SQxCUR...
Apple podcasts.apple.com/us/podcast/i...
If you like it, please, subscribe to the Turing Post's YouTube channel – Inference, and listen to our podcasts on all major platforms.
YouTube channel - 'Inference'-> www.youtube.com/@RealTuringP...
YouTube channel - 'Inference'-> www.youtube.com/@RealTuringP...
Turing Post
"When Will We…"
A thought-provoking interview series with today’s leading AI innovators. We connect the dots between cutting-edge research, key concepts, and the moment when future technologies become...
www.youtube.com
May 4, 2025 at 11:13 PM
If you like it, please, subscribe to the Turing Post's YouTube channel – Inference, and listen to our podcasts on all major platforms.
YouTube channel - 'Inference'-> www.youtube.com/@RealTuringP...
YouTube channel - 'Inference'-> www.youtube.com/@RealTuringP...
See the full list of the freshest research and other important news of the week in our free newsletter: www.turingpost.com/p/fod98

FOD#98: Coding Is Where AI’s Economy Starts
we discuss the coding as AI-first economic function, real meaning of vibe coding, AI’s takeover of software development, and the week’s biggest moves across research, startups, and politics.
www.turingpost.com
April 30, 2025 at 11:44 PM
See the full list of the freshest research and other important news of the week in our free newsletter: www.turingpost.com/p/fod98
7. Values in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions, @anthropicai.bsky.social
Maps AI value expressions across real-world interactions to inform grounded AI value alignment
arxiv.org/abs/2504.15236
Maps AI value expressions across real-world interactions to inform grounded AI value alignment
arxiv.org/abs/2504.15236

April 30, 2025 at 11:44 PM
7. Values in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions, @anthropicai.bsky.social
Maps AI value expressions across real-world interactions to inform grounded AI value alignment
arxiv.org/abs/2504.15236
Maps AI value expressions across real-world interactions to inform grounded AI value alignment
arxiv.org/abs/2504.15236
6. Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction
Highlights limitations of next-token prediction and proposes noise-injection strategies for open-ended creativity
arxiv.org/abs/2504.15266
GitHub: github.com/chenwu98/alg...
Highlights limitations of next-token prediction and proposes noise-injection strategies for open-ended creativity
arxiv.org/abs/2504.15266
GitHub: github.com/chenwu98/alg...

April 30, 2025 at 11:44 PM
6. Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction
Highlights limitations of next-token prediction and proposes noise-injection strategies for open-ended creativity
arxiv.org/abs/2504.15266
GitHub: github.com/chenwu98/alg...
Highlights limitations of next-token prediction and proposes noise-injection strategies for open-ended creativity
arxiv.org/abs/2504.15266
GitHub: github.com/chenwu98/alg...
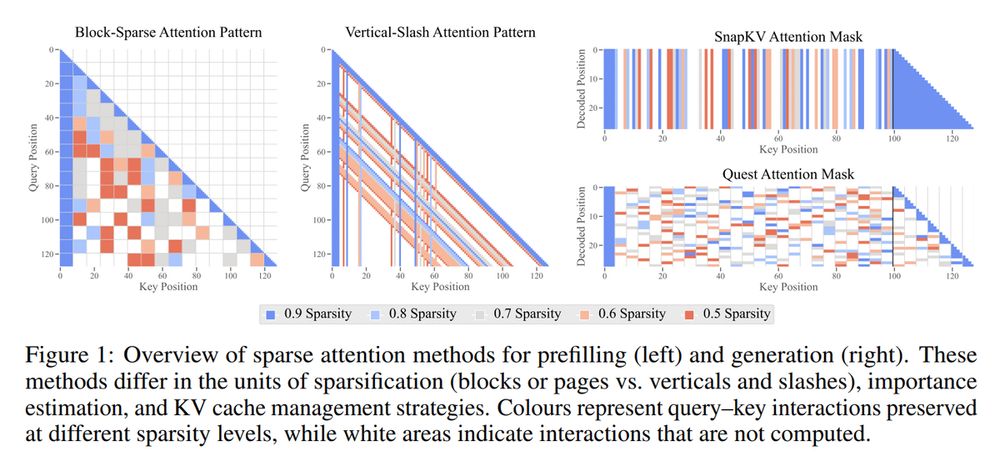
5. The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
Investigates sparse attention trade-offs and proposes scaling laws for long-context LLMs
arxiv.org/abs/2504.17768
Investigates sparse attention trade-offs and proposes scaling laws for long-context LLMs
arxiv.org/abs/2504.17768
April 30, 2025 at 11:44 PM
5. The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
Investigates sparse attention trade-offs and proposes scaling laws for long-context LLMs
arxiv.org/abs/2504.17768
Investigates sparse attention trade-offs and proposes scaling laws for long-context LLMs
arxiv.org/abs/2504.17768
4. Efficient Pretraining Length Scaling
Presents PHD-Transformer to enable efficient long-context pretraining without inflating memory costs
arxiv.org/abs/2504.14992
Presents PHD-Transformer to enable efficient long-context pretraining without inflating memory costs
arxiv.org/abs/2504.14992

April 30, 2025 at 11:44 PM
4. Efficient Pretraining Length Scaling
Presents PHD-Transformer to enable efficient long-context pretraining without inflating memory costs
arxiv.org/abs/2504.14992
Presents PHD-Transformer to enable efficient long-context pretraining without inflating memory costs
arxiv.org/abs/2504.14992
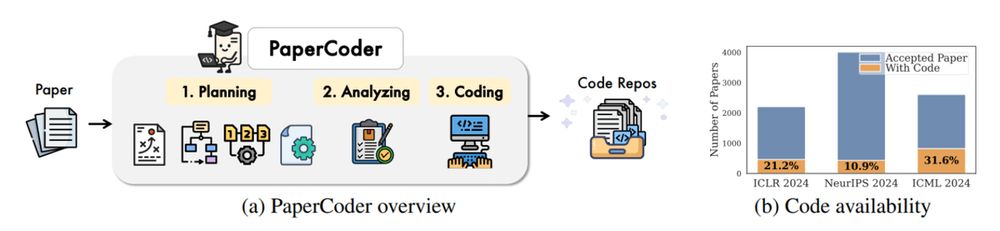
3. Paper2Code
Automates end-to-end ML paper-to-code translation with a multi-agent framework
arxiv.org/abs/2504.17192
Code: github.com/going-doer/P...
Automates end-to-end ML paper-to-code translation with a multi-agent framework
arxiv.org/abs/2504.17192
Code: github.com/going-doer/P...
April 30, 2025 at 11:44 PM
3. Paper2Code
Automates end-to-end ML paper-to-code translation with a multi-agent framework
arxiv.org/abs/2504.17192
Code: github.com/going-doer/P...
Automates end-to-end ML paper-to-code translation with a multi-agent framework
arxiv.org/abs/2504.17192
Code: github.com/going-doer/P...
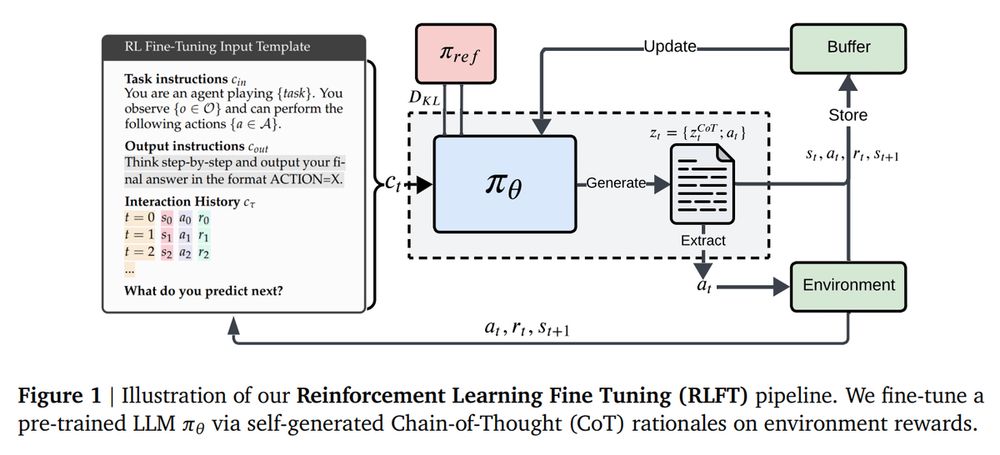
2. LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities
Analyzes how RL fine-tuning improves exploration and decision-making abilities of LLMs
arxiv.org/abs/2504.16078
Analyzes how RL fine-tuning improves exploration and decision-making abilities of LLMs
arxiv.org/abs/2504.16078
April 30, 2025 at 11:44 PM
2. LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities
Analyzes how RL fine-tuning improves exploration and decision-making abilities of LLMs
arxiv.org/abs/2504.16078
Analyzes how RL fine-tuning improves exploration and decision-making abilities of LLMs
arxiv.org/abs/2504.16078
1. TTRL: Test-Time Reinforcement Learning
Introduces a method for self-evolving LLMs at test-time using reward signals without labeled data
arxiv.org/abs/2504.16084
GitHub: github.com/PRIME-RL/TTRL
Introduces a method for self-evolving LLMs at test-time using reward signals without labeled data
arxiv.org/abs/2504.16084
GitHub: github.com/PRIME-RL/TTRL

April 30, 2025 at 11:44 PM
1. TTRL: Test-Time Reinforcement Learning
Introduces a method for self-evolving LLMs at test-time using reward signals without labeled data
arxiv.org/abs/2504.16084
GitHub: github.com/PRIME-RL/TTRL
Introduces a method for self-evolving LLMs at test-time using reward signals without labeled data
arxiv.org/abs/2504.16084
GitHub: github.com/PRIME-RL/TTRL
Read other interesting AI/ML news of the week in our free newsletter:
www.turingpost.com/p/fod98
www.turingpost.com/p/fod98
FOD#98: Coding Is Where AI’s Economy Starts
we discuss the coding as AI-first economic function, real meaning of vibe coding, AI’s takeover of software development, and the week’s biggest moves across research, startups, and politics.
www.turingpost.com
April 29, 2025 at 11:12 AM
Read other interesting AI/ML news of the week in our free newsletter:
www.turingpost.com/p/fod98
www.turingpost.com/p/fod98
9. Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Advances multimodal reasoning with a hybrid RL paradigm balancing reward guidance and rule-based strategies.
arxiv.org/abs/2504.16656
Model: huggingface.co/Skywork/Skyw...
Advances multimodal reasoning with a hybrid RL paradigm balancing reward guidance and rule-based strategies.
arxiv.org/abs/2504.16656
Model: huggingface.co/Skywork/Skyw...

April 29, 2025 at 11:12 AM
9. Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Advances multimodal reasoning with a hybrid RL paradigm balancing reward guidance and rule-based strategies.
arxiv.org/abs/2504.16656
Model: huggingface.co/Skywork/Skyw...
Advances multimodal reasoning with a hybrid RL paradigm balancing reward guidance and rule-based strategies.
arxiv.org/abs/2504.16656
Model: huggingface.co/Skywork/Skyw...
8. Process Reward Models That Think introduces ThinkPRM
It's a generative verifier that scales step-wise reward modeling with minimal supervision.
arxiv.org/abs/2504.16828
GitHub: github.com/mukhal/think...
It's a generative verifier that scales step-wise reward modeling with minimal supervision.
arxiv.org/abs/2504.16828
GitHub: github.com/mukhal/think...

April 29, 2025 at 11:12 AM
8. Process Reward Models That Think introduces ThinkPRM
It's a generative verifier that scales step-wise reward modeling with minimal supervision.
arxiv.org/abs/2504.16828
GitHub: github.com/mukhal/think...
It's a generative verifier that scales step-wise reward modeling with minimal supervision.
arxiv.org/abs/2504.16828
GitHub: github.com/mukhal/think...
7. Surya OCR:
Release an open-source, high-speed OCR model supporting 90+ languages with LaTeX formatting and structured output for real-world document processing.
x.com/VikParuchuri...
Release an open-source, high-speed OCR model supporting 90+ languages with LaTeX formatting and structured output for real-world document processing.
x.com/VikParuchuri...
x.com
April 29, 2025 at 11:12 AM
7. Surya OCR:
Release an open-source, high-speed OCR model supporting 90+ languages with LaTeX formatting and structured output for real-world document processing.
x.com/VikParuchuri...
Release an open-source, high-speed OCR model supporting 90+ languages with LaTeX formatting and structured output for real-world document processing.
x.com/VikParuchuri...
6. Trillion-7B:
Develops a highly token-efficient multilingual LLM using specialized cross-lingual techniques for Korean, Japanese, and more.
huggingface.co/papers/2504....
Model:
huggingface.co/trillionlabs...
Develops a highly token-efficient multilingual LLM using specialized cross-lingual techniques for Korean, Japanese, and more.
huggingface.co/papers/2504....
Model:
huggingface.co/trillionlabs...

Paper page - Trillion 7B Technical Report
Join the discussion on this paper page
huggingface.co
April 29, 2025 at 11:12 AM
6. Trillion-7B:
Develops a highly token-efficient multilingual LLM using specialized cross-lingual techniques for Korean, Japanese, and more.
huggingface.co/papers/2504....
Model:
huggingface.co/trillionlabs...
Develops a highly token-efficient multilingual LLM using specialized cross-lingual techniques for Korean, Japanese, and more.
huggingface.co/papers/2504....
Model:
huggingface.co/trillionlabs...
5. Eagle 2.5 by NVIDIA
Expands vision-language models to handle long-context video and image comprehension with specialized training tricks and efficient scaling.
arxiv.org/abs/2504.15271
Project page: nvlabs.github.io/EAGLE/
Expands vision-language models to handle long-context video and image comprehension with specialized training tricks and efficient scaling.
arxiv.org/abs/2504.15271
Project page: nvlabs.github.io/EAGLE/

April 29, 2025 at 11:12 AM
5. Eagle 2.5 by NVIDIA
Expands vision-language models to handle long-context video and image comprehension with specialized training tricks and efficient scaling.
arxiv.org/abs/2504.15271
Project page: nvlabs.github.io/EAGLE/
Expands vision-language models to handle long-context video and image comprehension with specialized training tricks and efficient scaling.
arxiv.org/abs/2504.15271
Project page: nvlabs.github.io/EAGLE/
4. Aimo-2 winning solution by Nvidia
Builds state-of-the-art mathematical reasoning models with OpenMathReasoning dataset.
arxiv.org/abs/2504.16891
Builds state-of-the-art mathematical reasoning models with OpenMathReasoning dataset.
arxiv.org/abs/2504.16891

April 29, 2025 at 11:12 AM
4. Aimo-2 winning solution by Nvidia
Builds state-of-the-art mathematical reasoning models with OpenMathReasoning dataset.
arxiv.org/abs/2504.16891
Builds state-of-the-art mathematical reasoning models with OpenMathReasoning dataset.
arxiv.org/abs/2504.16891