



Kristen Syme
@kristensyme.bsky.social
Research Fellow, University of Leicester, Psychology, Biocultural/Evolutionary Anthropology, kls52@leicester.ac.uk
This has also happening at Leiden University (much of what is happening in the US has been foreshadowd by events in the Netherlands_
June 6, 2025 at 11:23 AM
This has also happening at Leiden University (much of what is happening in the US has been foreshadowd by events in the Netherlands_
Excellent that you've got a project in mind! We'll be submitting it for pub in the near future. Here's the template for using GPT to annotate ethnographic and other texts by Dubourg, Thouzeau, and Baumard: www.frontiersin.org/journals/art...
April 19, 2025 at 9:04 AM
Excellent that you've got a project in mind! We'll be submitting it for pub in the near future. Here's the template for using GPT to annotate ethnographic and other texts by Dubourg, Thouzeau, and Baumard: www.frontiersin.org/journals/art...
In sum, the innovation of LLMs, in providing low cost and highly accurate annotations, has created the opportunity for human behavioral scientists to investigate the form and function of rituals and other outstanding puzzles of human behavior and culture on an unprecedented scale.
April 18, 2025 at 7:04 PM
In sum, the innovation of LLMs, in providing low cost and highly accurate annotations, has created the opportunity for human behavioral scientists to investigate the form and function of rituals and other outstanding puzzles of human behavior and culture on an unprecedented scale.
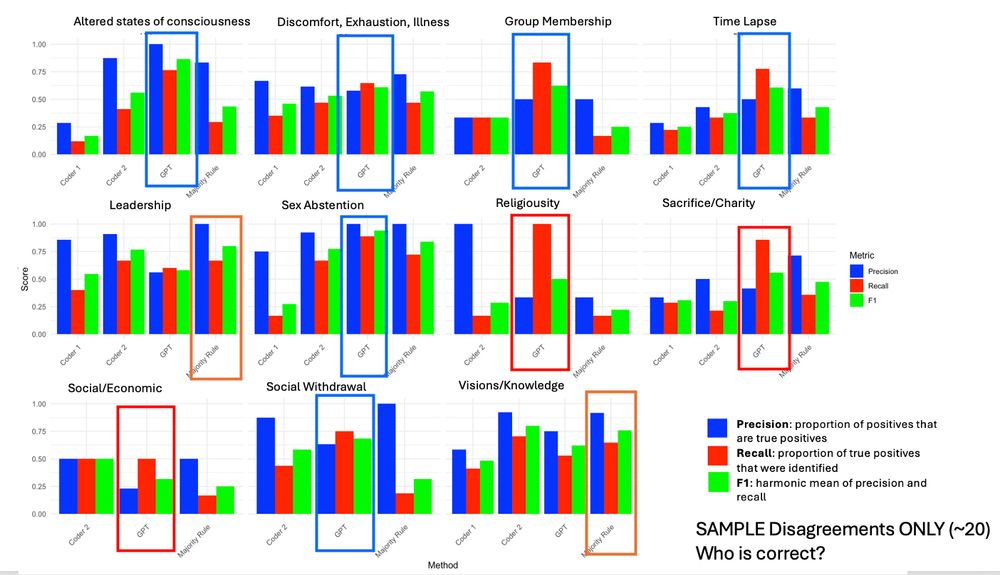
Scrutinizing a sample of disagreements, we found that GPT provided the most accurate responses for 6 vars. For 3 vars, including gender, a 'majority rule' between the two humans and GPT provided the most accurate response. GPT overcoded 3 vars.
April 18, 2025 at 7:01 PM
Scrutinizing a sample of disagreements, we found that GPT provided the most accurate responses for 6 vars. For 3 vars, including gender, a 'majority rule' between the two humans and GPT provided the most accurate response. GPT overcoded 3 vars.
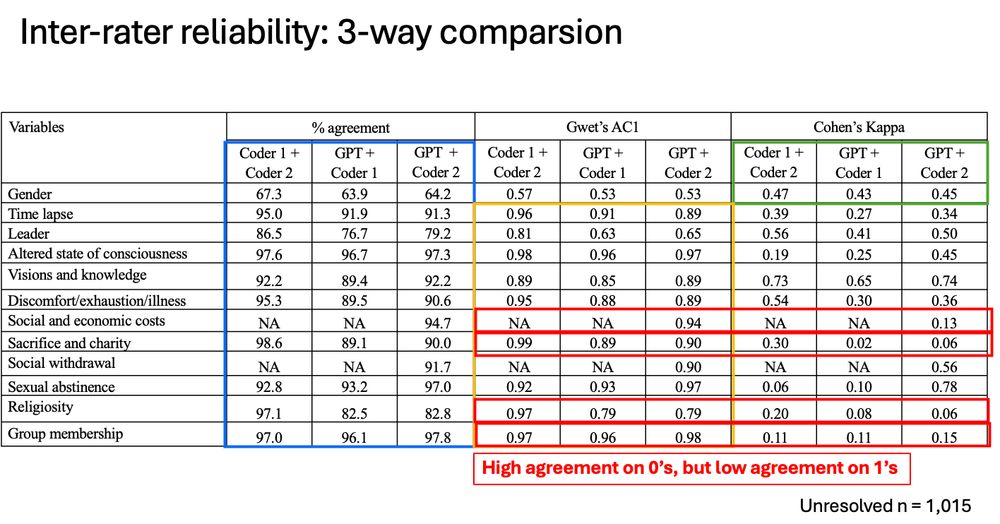
Running GPT across the unresolved 1,015 texts, the human coders had only slightly higher agreement and reliability with each other compared to GPT with each human. Although Gwet's ac1 was high for all vars, Cohen's kappa was much too low on 4, indicating high agreement on 0s but low agreement on 1s.
April 18, 2025 at 6:54 PM
Running GPT across the unresolved 1,015 texts, the human coders had only slightly higher agreement and reliability with each other compared to GPT with each human. Although Gwet's ac1 was high for all vars, Cohen's kappa was much too low on 4, indicating high agreement on 0s but low agreement on 1s.
We had GPT help us come to the 'correct' answers by having it provide a rationale for its response. In some cases GPT was wrong, but in other cases, it helped us identify cases that that we humans mis-coded, as these examples with religiousity demonstrate.

April 18, 2025 at 6:48 PM
We had GPT help us come to the 'correct' answers by having it provide a rationale for its response. In some cases GPT was wrong, but in other cases, it helped us identify cases that that we humans mis-coded, as these examples with religiousity demonstrate.
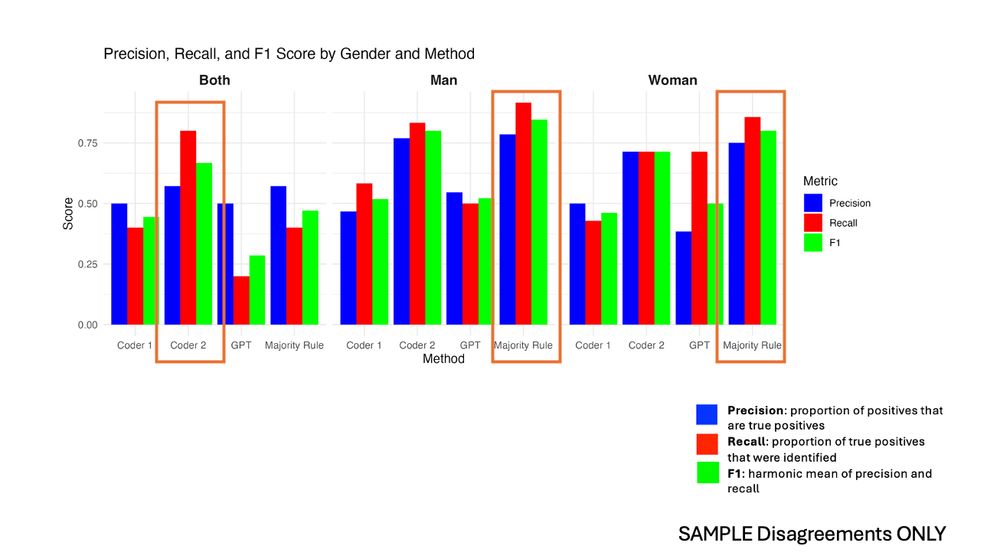
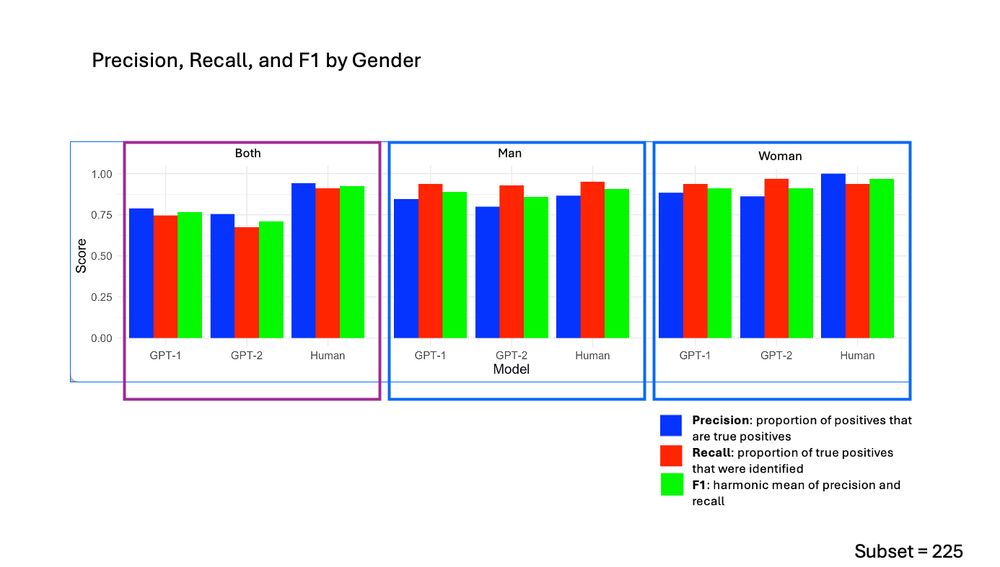
GPT performed nearly as well as humans on identifying whether the gender of the faster was a man or a woman, though it performed somewhat worse for identifying 'Both' due to greater ambiguity in e.g., both vs. unknown.
April 18, 2025 at 6:43 PM
GPT performed nearly as well as humans on identifying whether the gender of the faster was a man or a woman, though it performed somewhat worse for identifying 'Both' due to greater ambiguity in e.g., both vs. unknown.
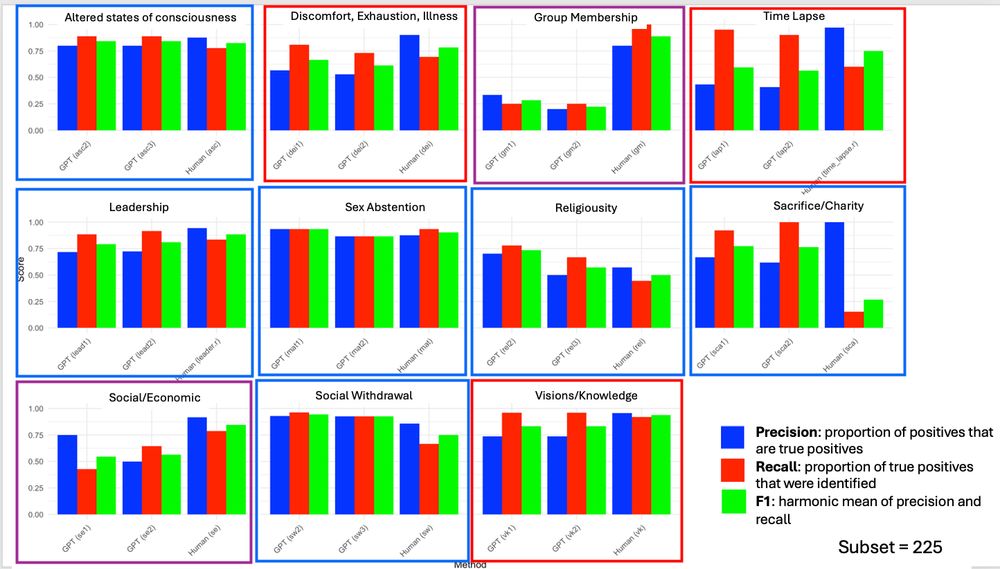
Measuring precision, recall, and f1, we found that GPT annotated as well or better than humans on 5 vars, tended to overcode (i.e., high recall) on 3 vars (tho it performs well on Visions and Knowledge overall), and performed poorly on 2 vars.
April 18, 2025 at 6:40 PM
Measuring precision, recall, and f1, we found that GPT annotated as well or better than humans on 5 vars, tended to overcode (i.e., high recall) on 3 vars (tho it performs well on Visions and Knowledge overall), and performed poorly on 2 vars.
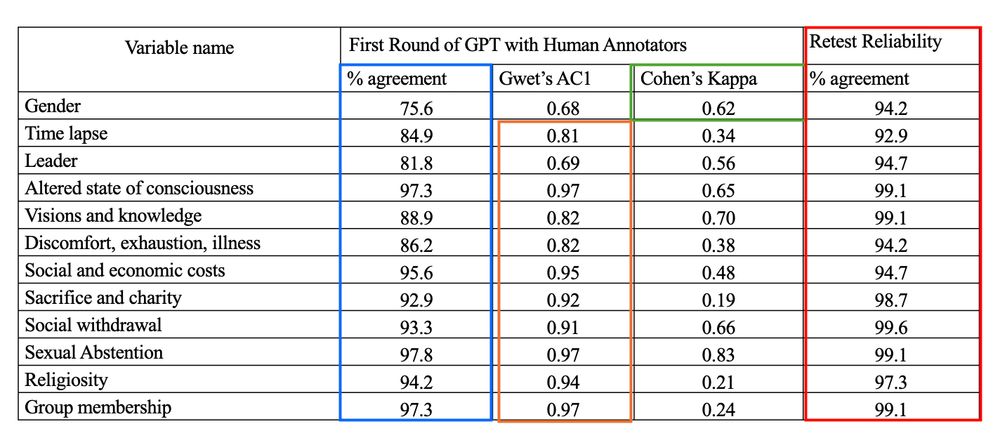
Starting with a sample of 225 texts that we came to a consensus on, we found high % agreement and inter-rater reliability between GPT 4.0 and the human annotators. We also found over 90% agreement of GPT with itself on two rounds.
April 18, 2025 at 6:36 PM
Starting with a sample of 225 texts that we came to a consensus on, we found high % agreement and inter-rater reliability between GPT 4.0 and the human annotators. We also found over 90% agreement of GPT with itself on two rounds.
My co-author Caity Placek and I manually coded 1,240 paragraphs on ritual fasting from the HRAF and tested GPT 4.0's ability to annotate the texts and help us resolve discrepancies on 12 variables incl. gender of fasters, cognitive outcomes, and health and social outcomes.

April 18, 2025 at 6:33 PM
My co-author Caity Placek and I manually coded 1,240 paragraphs on ritual fasting from the HRAF and tested GPT 4.0's ability to annotate the texts and help us resolve discrepancies on 12 variables incl. gender of fasters, cognitive outcomes, and health and social outcomes.
Preprint available here: osf.io/preprints/os...
OSF
osf.io
December 17, 2024 at 10:20 AM
Preprint available here: osf.io/preprints/os...