



Kawin Ethayarajh
@kawinethayarajh.bsky.social
Postdoc at Princeton PLI. Formerly PhD at Stanford CS. Working on behavioral machine learning. https://kawine.github.io/
Interesting. Is this because they have govt contracts and those would be jeopardized? Or uncertainty around whether those models will be banned for use in America, which adds a huge risk premium?
May 5, 2025 at 4:51 PM
Interesting. Is this because they have govt contracts and those would be jeopardized? Or uncertainty around whether those models will be banned for use in America, which adds a huge risk premium?
relevant paper: arxiv.org/abs/2410.08847

Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization
Direct Preference Optimization (DPO) and its variants are increasingly used for aligning language models with human preferences. Although these methods are designed to teach a model to generate prefer...
arxiv.org
December 19, 2024 at 8:28 PM
relevant paper: arxiv.org/abs/2410.08847
for all methods, it is better for data to be on-policy and be labelled as good/bad relative to the current state of the policy.
but ultimately this is a learning dynamics problem that transcends how the data is sampled
but ultimately this is a learning dynamics problem that transcends how the data is sampled
December 19, 2024 at 8:27 PM
for all methods, it is better for data to be on-policy and be labelled as good/bad relative to the current state of the policy.
but ultimately this is a learning dynamics problem that transcends how the data is sampled
but ultimately this is a learning dynamics problem that transcends how the data is sampled
unpaired methods work the way we hope paired methods would, simultaneously increasing the relative prob of good outputs and decreasing the relative prob of bad outputs. this allows you to skip SFT entirely
December 19, 2024 at 8:25 PM
unpaired methods work the way we hope paired methods would, simultaneously increasing the relative prob of good outputs and decreasing the relative prob of bad outputs. this allows you to skip SFT entirely
it's not really on vs. off-policy. in theory, paired methods should increase the prob of good outputs, decrease prob of bad outputs. in practice, they decrease *both*. you need to do SFT beforehand so that you can pay this price and hope that relative to the base model, p(good|x) is still higher
December 19, 2024 at 8:23 PM
it's not really on vs. off-policy. in theory, paired methods should increase the prob of good outputs, decrease prob of bad outputs. in practice, they decrease *both*. you need to do SFT beforehand so that you can pay this price and hope that relative to the base model, p(good|x) is still higher
all paired preference methods suffer from this problem while also being more inflexible. unpaired preference methods are always the way to go IME
December 19, 2024 at 6:02 PM
all paired preference methods suffer from this problem while also being more inflexible. unpaired preference methods are always the way to go IME
Source: old.reddit.com/r/LocalLLaMA...
old.reddit.com
November 26, 2024 at 11:36 PM
Source: old.reddit.com/r/LocalLLaMA...
nominating myself @kawinethayarajh.bsky.social
November 21, 2024 at 7:02 PM
nominating myself @kawinethayarajh.bsky.social
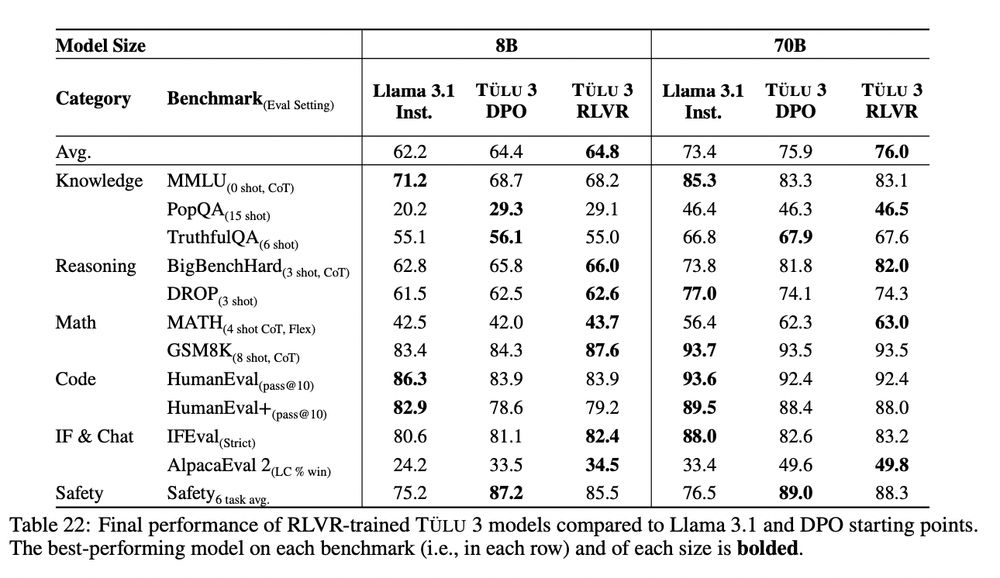
These differences with the DPO version don't seem statistically significant?
November 21, 2024 at 6:39 PM
These differences with the DPO version don't seem statistically significant?
(almost) all good poetry has high perplexity. it's by design something an out-of-the-box llm would be bad at. alignment on one poet would actually help imo.
November 21, 2024 at 5:24 AM
(almost) all good poetry has high perplexity. it's by design something an out-of-the-box llm would be bad at. alignment on one poet would actually help imo.
Moderately grumpy UToronto alumnus nominating myself 🙋
November 18, 2024 at 11:19 PM
Moderately grumpy UToronto alumnus nominating myself 🙋
Could i be added (recent alumnus)? Thank you!
November 18, 2024 at 11:16 PM
Could i be added (recent alumnus)? Thank you!
Would love to be added thanks!
November 17, 2024 at 4:41 PM
Would love to be added thanks!