




Finally releasing the first iteration of our MCP Router project. Pure Python implementation using Flask + htmx, FastMCP 2.x, llm-sandbox, SQLite. Supports stdio, HTTP, and sse transports.

June 27, 2025 at 8:30 PM
Finally releasing the first iteration of our MCP Router project. Pure Python implementation using Flask + htmx, FastMCP 2.x, llm-sandbox, SQLite. Supports stdio, HTTP, and sse transports.
Getting to hear @dawnieando.bsky.social at #seoweek is an absolute treat.

April 29, 2025 at 8:47 PM
Getting to hear @dawnieando.bsky.social at #seoweek is an absolute treat.
Instant pot butter chicken from Milk Street. Looks gross, hope it tastes amazing?

December 27, 2024 at 12:30 AM
Instant pot butter chicken from Milk Street. Looks gross, hope it tastes amazing?
Improved the Daily SEO Feed:
✅Uses more efficient Jetstream service
✅Improved ranking algorithm with decay, quorum, and freshness boost scoring.
✅ Added 50 more users to improve trust-rank style approach.
Get the feed --> bsky.app/profile/did:...
Improve the feed -->
github.com/jroakes/Dail...
✅Uses more efficient Jetstream service
✅Improved ranking algorithm with decay, quorum, and freshness boost scoring.
✅ Added 50 more users to improve trust-rank style approach.
Get the feed --> bsky.app/profile/did:...
Improve the feed -->
github.com/jroakes/Dail...


December 12, 2024 at 1:05 PM
Improved the Daily SEO Feed:
✅Uses more efficient Jetstream service
✅Improved ranking algorithm with decay, quorum, and freshness boost scoring.
✅ Added 50 more users to improve trust-rank style approach.
Get the feed --> bsky.app/profile/did:...
Improve the feed -->
github.com/jroakes/Dail...
✅Uses more efficient Jetstream service
✅Improved ranking algorithm with decay, quorum, and freshness boost scoring.
✅ Added 50 more users to improve trust-rank style approach.
Get the feed --> bsky.app/profile/did:...
Improve the feed -->
github.com/jroakes/Dail...
I resurrected and improved my quotation unscrambling game, Quamble, this weekend. A good little diversion to get your brain active for a few minutes.
quamble.app
quamble.app

December 9, 2024 at 1:49 PM
I resurrected and improved my quotation unscrambling game, Quamble, this weekend. A good little diversion to get your brain active for a few minutes.
quamble.app
quamble.app
Here are a couple that I have in my phone. One is a modern piece with. Local architetect that I loved working with. The other is a more traditional peacock desigh with imported mouth blown glass and mahogany frames.


November 28, 2024 at 8:01 PM
Here are a couple that I have in my phone. One is a modern piece with. Local architetect that I loved working with. The other is a more traditional peacock desigh with imported mouth blown glass and mahogany frames.
How good is a 100% AI-generated schema analysis tool? 🤷♂️
Try it out ---> schema-analyzer-jroakes1.replit.app
Try it out ---> schema-analyzer-jroakes1.replit.app

November 24, 2024 at 7:35 PM
How good is a 100% AI-generated schema analysis tool? 🤷♂️
Try it out ---> schema-analyzer-jroakes1.replit.app
Try it out ---> schema-analyzer-jroakes1.replit.app
Working on my own **clean/minimalist** version of Hacker News at hkrne.ws. Working with @netlify.com for UX + Firebase for post curation, storage, and API. #WeekendProject

November 24, 2024 at 6:53 PM
Working on my own **clean/minimalist** version of Hacker News at hkrne.ws. Working with @netlify.com for UX + Firebase for post curation, storage, and API. #WeekendProject
Onboard and ready to take off for brightonSEO San Diego. Anyone going to be in town today?

November 17, 2024 at 2:36 PM
Onboard and ready to take off for brightonSEO San Diego. Anyone going to be in town today?
I've been experimenting with the Gemini Nano model in Google Chrome Canary. Google has implemented clear model governance restrictions to prevent the model from performing malicious actions, such as generating harmful code or stealing banking data. I wanted to test its ability to do NER.

November 13, 2024 at 4:28 PM
I've been experimenting with the Gemini Nano model in Google Chrome Canary. Google has implemented clear model governance restrictions to prevent the model from performing malicious actions, such as generating harmful code or stealing banking data. I wanted to test its ability to do NER.
Need to get clean content from a bunch of URLs quickly? E.g. API docs for a language model. Built a tool using Replit's AI where you can enter an XML Sitemap or a bunch of URLs, and it will grab the clean content and allow you to copy, or download as text, markdown, or JSON. Neat!
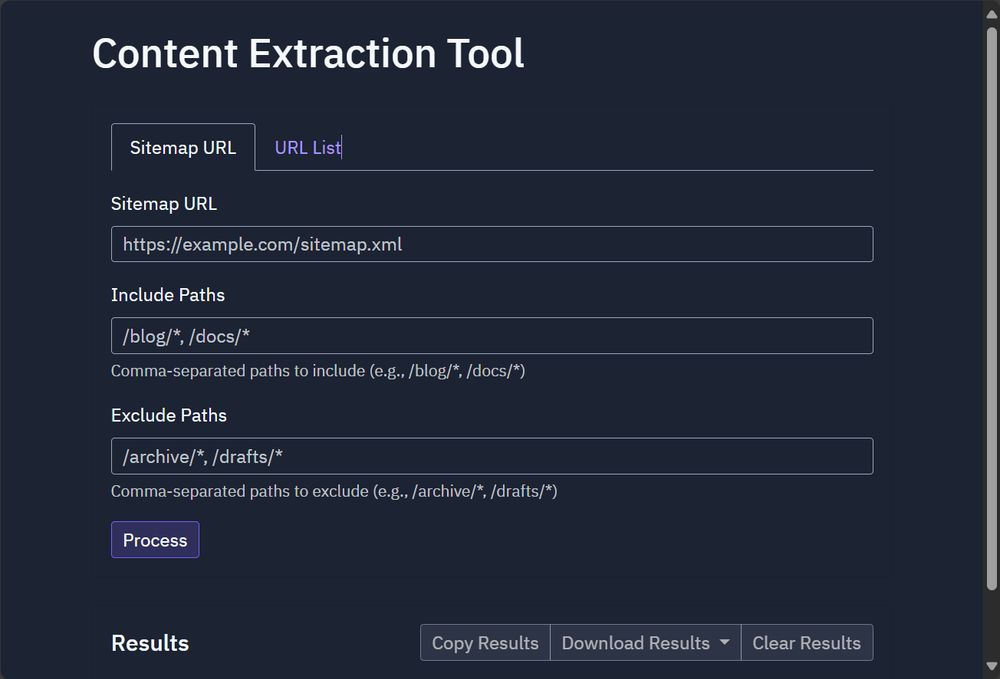
November 11, 2024 at 5:34 PM
Need to get clean content from a bunch of URLs quickly? E.g. API docs for a language model. Built a tool using Replit's AI where you can enter an XML Sitemap or a bunch of URLs, and it will grab the clean content and allow you to copy, or download as text, markdown, or JSON. Neat!
Halloween full-size God mode activated.

October 29, 2023 at 10:34 PM
Halloween full-size God mode activated.
Created a fun project over the weekend. I have always wanted to write a program that can write itself. You supply it with an objective, and an expected result, and it will write and rewrite itself until it achieves the result.
github.com/jroakes/gene...
github.com/jroakes/gene...

August 29, 2023 at 12:57 PM
Created a fun project over the weekend. I have always wanted to write a program that can write itself. You supply it with an objective, and an expected result, and it will write and rewrite itself until it achieves the result.
github.com/jroakes/gene...
github.com/jroakes/gene...
Anyone have a clue as to why Safari would be sending so much more traffic from Google to a site with fragment text targets (feature snippet or SGE links) compared to Chrome. @rustybrick.com Have you seen this?
e.g. landing page urls like
domain.com/page/#:~:tex... are the requirements
e.g. landing page urls like
domain.com/page/#:~:tex... are the requirements

August 24, 2023 at 4:05 PM
Anyone have a clue as to why Safari would be sending so much more traffic from Google to a site with fragment text targets (feature snippet or SGE links) compared to Chrome. @rustybrick.com Have you seen this?
e.g. landing page urls like
domain.com/page/#:~:tex... are the requirements
e.g. landing page urls like
domain.com/page/#:~:tex... are the requirements
Tracking 20 years of search
2003 - 2023 through the eyes of as covered by @rustybrick.com on seroundtable.com. This article is an exploration of Barry's work and the industry as a whole.
Read here: ➡️ https://searchengineland.com/tracking-20-years-search-430573
2003 - 2023 through the eyes of as covered by @rustybrick.com on seroundtable.com. This article is an exploration of Barry's work and the industry as a whole.
Read here: ➡️ https://searchengineland.com/tracking-20-years-search-430573

August 11, 2023 at 2:19 PM
Tracking 20 years of search
2003 - 2023 through the eyes of as covered by @rustybrick.com on seroundtable.com. This article is an exploration of Barry's work and the industry as a whole.
Read here: ➡️ https://searchengineland.com/tracking-20-years-search-430573
2003 - 2023 through the eyes of as covered by @rustybrick.com on seroundtable.com. This article is an exploration of Barry's work and the industry as a whole.
Read here: ➡️ https://searchengineland.com/tracking-20-years-search-430573
Made ramen from scratch for the first time. Quite the undertaking.

August 7, 2023 at 12:38 PM
Made ramen from scratch for the first time. Quite the undertaking.
We have a new open-source tool that we have developed! We are calling it TaxonomyML. It accepts a CSV or a GSC property. Processes the queries into a cogent high-level taxonomy for the website.
Github: https://github.com/locomotive-agency/taxonomyml
Demo: https://locomotive-taxonomy-ml.hf.space/
Github: https://github.com/locomotive-agency/taxonomyml
Demo: https://locomotive-taxonomy-ml.hf.space/

August 3, 2023 at 3:29 PM
We have a new open-source tool that we have developed! We are calling it TaxonomyML. It accepts a CSV or a GSC property. Processes the queries into a cogent high-level taxonomy for the website.
Github: https://github.com/locomotive-agency/taxonomyml
Demo: https://locomotive-taxonomy-ml.hf.space/
Github: https://github.com/locomotive-agency/taxonomyml
Demo: https://locomotive-taxonomy-ml.hf.space/
Currently working on whole site and industry-wide taxonomy building at scale.

July 4, 2023 at 6:22 PM
Currently working on whole site and industry-wide taxonomy building at scale.
