




Jordi Pons
@jordiponsdotme.bsky.social
Music, audio, and deep learning research at Stability AI ~ Building bridges between audio signal processing wisdom and deep learning.
artintech.substack.com
www.jordipons.me
artintech.substack.com
www.jordipons.me

November 3, 2025 at 3:31 AM
Meet our AI Song Contest 2025 entry!
We submitted an interactive & generative AI music piece.
We used AI for:
- Sound design
- Interactive playback
More details about..
- Human-AI co-creation process
- Name of the song
- Videoclip
- Live performance
👉 artintech.substack.com/p/our-ai-son...
We submitted an interactive & generative AI music piece.
We used AI for:
- Sound design
- Interactive playback
More details about..
- Human-AI co-creation process
- Name of the song
- Videoclip
- Live performance
👉 artintech.substack.com/p/our-ai-son...
September 2, 2025 at 12:50 PM
Meet our AI Song Contest 2025 entry!
We submitted an interactive & generative AI music piece.
We used AI for:
- Sound design
- Interactive playback
More details about..
- Human-AI co-creation process
- Name of the song
- Videoclip
- Live performance
👉 artintech.substack.com/p/our-ai-son...
We submitted an interactive & generative AI music piece.
We used AI for:
- Sound design
- Interactive playback
More details about..
- Human-AI co-creation process
- Name of the song
- Videoclip
- Live performance
👉 artintech.substack.com/p/our-ai-son...
And we study how musicians use AI across formats:
- Singles
- Albums
- Performances
- Installations
- AI voices
- Operas
- Soundtracks
- Singles
- Albums
- Performances
- Installations
- AI voices
- Operas
- Soundtracks

August 19, 2025 at 2:47 PM
And we study how musicians use AI across formats:
- Singles
- Albums
- Performances
- Installations
- AI voices
- Operas
- Soundtracks
- Singles
- Albums
- Performances
- Installations
- AI voices
- Operas
- Soundtracks
We categorize them based on AI usage:
- AI composition
- Co-composition
- Sound design
- Lyrics generation
- Translation
- AI composition
- Co-composition
- Sound design
- Lyrics generation
- Translation

August 19, 2025 at 2:47 PM
We categorize them based on AI usage:
- AI composition
- Co-composition
- Sound design
- Lyrics generation
- Translation
- AI composition
- Co-composition
- Sound design
- Lyrics generation
- Translation
We analyzed 337 AI music artworks (2017–2024) to uncover how artists are creating with AI.
📄 Paper (arXiv)
📂 Database (GitHub)
🎥 Video
👉 artintech.substack.com/p/report-art...
📄 Paper (arXiv)
📂 Database (GitHub)
🎥 Video
👉 artintech.substack.com/p/report-art...

August 19, 2025 at 2:47 PM
We analyzed 337 AI music artworks (2017–2024) to uncover how artists are creating with AI.
📄 Paper (arXiv)
📂 Database (GitHub)
🎥 Video
👉 artintech.substack.com/p/report-art...
📄 Paper (arXiv)
📂 Database (GitHub)
🎥 Video
👉 artintech.substack.com/p/report-art...
Today we release Stable Audio Open Small 🫂
Based on adversarial post-training, it does not rely on distillation or CFG
Runtime is reduced to milliseconds with GPUs or seconds with CPUs
Weights huggingface.co/stabilityai/...
Blog stability.ai/news/stabili...
Paper arxiv.org/abs/2505.08175
Based on adversarial post-training, it does not rely on distillation or CFG
Runtime is reduced to milliseconds with GPUs or seconds with CPUs
Weights huggingface.co/stabilityai/...
Blog stability.ai/news/stabili...
Paper arxiv.org/abs/2505.08175
May 14, 2025 at 3:51 PM
Today we release Stable Audio Open Small 🫂
Based on adversarial post-training, it does not rely on distillation or CFG
Runtime is reduced to milliseconds with GPUs or seconds with CPUs
Weights huggingface.co/stabilityai/...
Blog stability.ai/news/stabili...
Paper arxiv.org/abs/2505.08175
Based on adversarial post-training, it does not rely on distillation or CFG
Runtime is reduced to milliseconds with GPUs or seconds with CPUs
Weights huggingface.co/stabilityai/...
Blog stability.ai/news/stabili...
Paper arxiv.org/abs/2505.08175
Making AI music without knowing Xenakis' work is like playing jazz without having heard Coltrane.
In the language of their time, 'indeterminacy' is akin to what we now call 'generative'—where some aspects of the composition are left to chance (not determined).
rohandrape.net/ut/rttcc-tex...
In the language of their time, 'indeterminacy' is akin to what we now call 'generative'—where some aspects of the composition are left to chance (not determined).
rohandrape.net/ut/rttcc-tex...

May 9, 2025 at 2:04 PM
Making AI music without knowing Xenakis' work is like playing jazz without having heard Coltrane.
In the language of their time, 'indeterminacy' is akin to what we now call 'generative'—where some aspects of the composition are left to chance (not determined).
rohandrape.net/ut/rttcc-tex...
In the language of their time, 'indeterminacy' is akin to what we now call 'generative'—where some aspects of the composition are left to chance (not determined).
rohandrape.net/ut/rttcc-tex...
What is the mindset of an AI artist?
Thinking of art more as 'seeds' than 'artifacts' — and AI not as a 'tool', but as a 'mirror'.
And also to be aware that the line between audience and author blurs.
More ideas in the full article here 👇
artintech.substack.com/p/the-ai-art...
Thinking of art more as 'seeds' than 'artifacts' — and AI not as a 'tool', but as a 'mirror'.
And also to be aware that the line between audience and author blurs.
More ideas in the full article here 👇
artintech.substack.com/p/the-ai-art...

April 7, 2025 at 12:58 PM
What is the mindset of an AI artist?
Thinking of art more as 'seeds' than 'artifacts' — and AI not as a 'tool', but as a 'mirror'.
And also to be aware that the line between audience and author blurs.
More ideas in the full article here 👇
artintech.substack.com/p/the-ai-art...
Thinking of art more as 'seeds' than 'artifacts' — and AI not as a 'tool', but as a 'mirror'.
And also to be aware that the line between audience and author blurs.
More ideas in the full article here 👇
artintech.substack.com/p/the-ai-art...
Last year, copyright drama dominated the conversation. This year, let’s focus on AI art.
Beyond Copyright Battles—AI Art 👉 artintech.substack.com/p/ai-art-bey...
Beyond Copyright Battles—AI Art 👉 artintech.substack.com/p/ai-art-bey...

April 2, 2025 at 4:57 PM
Last year, copyright drama dominated the conversation. This year, let’s focus on AI art.
Beyond Copyright Battles—AI Art 👉 artintech.substack.com/p/ai-art-bey...
Beyond Copyright Battles—AI Art 👉 artintech.substack.com/p/ai-art-bey...
I listened to all 165 AI Song Contest entries
and found 5 trends that are shaping current AI music
🐝 Embrace the uncanny
🐝 Multi-genre AI music
🐝 AI music that reflects your culture
🐝 Lazy artwork
🐝 Not much Chinese and African AI music
👉https://artintech.substack.com/p/my-top-5-ai-music-picks
and found 5 trends that are shaping current AI music
🐝 Embrace the uncanny
🐝 Multi-genre AI music
🐝 AI music that reflects your culture
🐝 Lazy artwork
🐝 Not much Chinese and African AI music
👉https://artintech.substack.com/p/my-top-5-ai-music-picks

March 31, 2025 at 10:07 AM
I listened to all 165 AI Song Contest entries
and found 5 trends that are shaping current AI music
🐝 Embrace the uncanny
🐝 Multi-genre AI music
🐝 AI music that reflects your culture
🐝 Lazy artwork
🐝 Not much Chinese and African AI music
👉https://artintech.substack.com/p/my-top-5-ai-music-picks
and found 5 trends that are shaping current AI music
🐝 Embrace the uncanny
🐝 Multi-genre AI music
🐝 AI music that reflects your culture
🐝 Lazy artwork
🐝 Not much Chinese and African AI music
👉https://artintech.substack.com/p/my-top-5-ai-music-picks
Stable Audio API is now up!
platform.stability.ai/docs/api-ref...
platform.stability.ai/docs/api-ref...
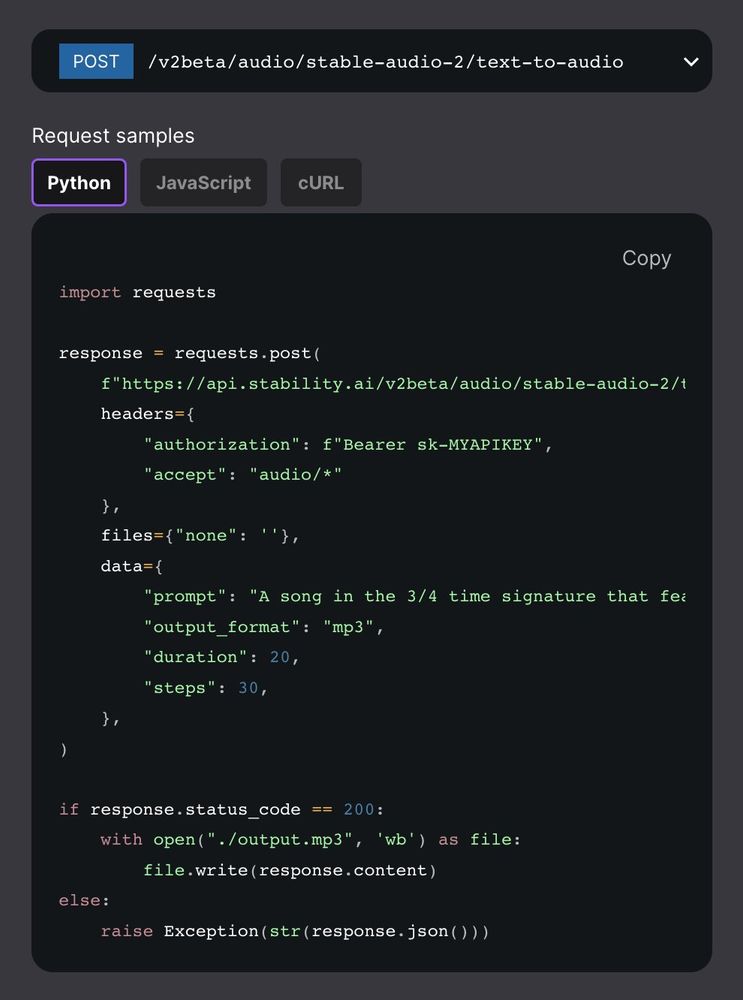
March 26, 2025 at 5:06 AM
Stable Audio API is now up!
platform.stability.ai/docs/api-ref...
platform.stability.ai/docs/api-ref...
Stable Audio Open now runs on your phone!
CPUs go brrrrrrr
CPUs go brrrrrrr
March 3, 2025 at 11:31 AM
Stable Audio Open now runs on your phone!
CPUs go brrrrrrr
CPUs go brrrrrrr
Use 3-stage training scheme
- Stage 1 (semantic tokens): dual-tokens language modeling from audio and text conditioning
- Stage 2 (acoustic tokens): vocal and instrumental language modeling from semantic tokens (using residual vector quantizers?)
- Stage 3 (audio): detokenization and upsampling
- Stage 1 (semantic tokens): dual-tokens language modeling from audio and text conditioning
- Stage 2 (acoustic tokens): vocal and instrumental language modeling from semantic tokens (using residual vector quantizers?)
- Stage 3 (audio): detokenization and upsampling

January 28, 2025 at 8:17 AM
Use 3-stage training scheme
- Stage 1 (semantic tokens): dual-tokens language modeling from audio and text conditioning
- Stage 2 (acoustic tokens): vocal and instrumental language modeling from semantic tokens (using residual vector quantizers?)
- Stage 3 (audio): detokenization and upsampling
- Stage 1 (semantic tokens): dual-tokens language modeling from audio and text conditioning
- Stage 2 (acoustic tokens): vocal and instrumental language modeling from semantic tokens (using residual vector quantizers?)
- Stage 3 (audio): detokenization and upsampling
No paper available, but use:
- Semantic audio tokens, to reduce training cost
- Dual-tokens (vocal-instrumental) for track-synced vocal-instrumental modeling
- Lyrics-chain-of-thoughts to progressively generate the whole song in a single context following lyrics condition (I don't know what this is)
- Semantic audio tokens, to reduce training cost
- Dual-tokens (vocal-instrumental) for track-synced vocal-instrumental modeling
- Lyrics-chain-of-thoughts to progressively generate the whole song in a single context following lyrics condition (I don't know what this is)

January 28, 2025 at 8:17 AM
No paper available, but use:
- Semantic audio tokens, to reduce training cost
- Dual-tokens (vocal-instrumental) for track-synced vocal-instrumental modeling
- Lyrics-chain-of-thoughts to progressively generate the whole song in a single context following lyrics condition (I don't know what this is)
- Semantic audio tokens, to reduce training cost
- Dual-tokens (vocal-instrumental) for track-synced vocal-instrumental modeling
- Lyrics-chain-of-thoughts to progressively generate the whole song in a single context following lyrics condition (I don't know what this is)
Weights are out! 🤗
Tokenizing 16kHz speech at very low bitrates.
Inference code: github.com/Stability-AI...
Model code: github.com/Stability-AI...
Model weights: huggingface.co/stabilityai/...
arXiv: arxiv.org/abs/2411.19842
Audio demos: stability-ai.github.io/stable-codec...
Tokenizing 16kHz speech at very low bitrates.
Inference code: github.com/Stability-AI...
Model code: github.com/Stability-AI...
Model weights: huggingface.co/stabilityai/...
arXiv: arxiv.org/abs/2411.19842
Audio demos: stability-ai.github.io/stable-codec...

January 10, 2025 at 5:12 PM
Weights are out! 🤗
Tokenizing 16kHz speech at very low bitrates.
Inference code: github.com/Stability-AI...
Model code: github.com/Stability-AI...
Model weights: huggingface.co/stabilityai/...
arXiv: arxiv.org/abs/2411.19842
Audio demos: stability-ai.github.io/stable-codec...
Tokenizing 16kHz speech at very low bitrates.
Inference code: github.com/Stability-AI...
Model code: github.com/Stability-AI...
Model weights: huggingface.co/stabilityai/...
arXiv: arxiv.org/abs/2411.19842
Audio demos: stability-ai.github.io/stable-codec...
AI- or Jordi-generated?
December 29, 2024 at 9:40 PM
AI- or Jordi-generated?
🎅 🎄 NEW CHRISTMAS AI drum packs 🎄 🎅
Time to cook up some Christmas bangers!
🔗 jordipons.me/apps/samples/
Time to cook up some Christmas bangers!
🔗 jordipons.me/apps/samples/
December 8, 2024 at 6:43 PM
🎅 🎄 NEW CHRISTMAS AI drum packs 🎄 🎅
Time to cook up some Christmas bangers!
🔗 jordipons.me/apps/samples/
Time to cook up some Christmas bangers!
🔗 jordipons.me/apps/samples/