




Jacob Schreiber
@jmschreiber91.bsky.social
Studying genomics, machine learning, and fruit. My code is like our genomes -- most of it is junk.
Assistant Professor UMass Chan, Board of Directors NumFOCUS
Previously IMP Vienna, Stanford Genetics, UW CSE.
Assistant Professor UMass Chan, Board of Directors NumFOCUS
Previously IMP Vienna, Stanford Genetics, UW CSE.
I was delighted to have the unexpected opportunity to give a keynote at MLCB 2025 in NYC last week. I used it to explain how I view deep learning models in genomics not as "uninterpretable black boxes" but as indispensable tools for understanding genomics + designing the next gen of synthetic DNA.

September 19, 2025 at 1:59 PM
I was delighted to have the unexpected opportunity to give a keynote at MLCB 2025 in NYC last week. I used it to explain how I view deep learning models in genomics not as "uninterpretable black boxes" but as indispensable tools for understanding genomics + designing the next gen of synthetic DNA.
stocking up the new apartment with essentials



September 3, 2025 at 2:24 PM
stocking up the new apartment with essentials
Because everything is automatic, we can probe models.
What motifs are driving model predictions? Calculate attributions, call + annotate seqlets, and count the annotations!
BPNet is relying on MYC, whereas Beluga is relying on many more TFs. Easy comparison now.
What motifs are driving model predictions? Calculate attributions, call + annotate seqlets, and count the annotations!
BPNet is relying on MYC, whereas Beluga is relying on many more TFs. Easy comparison now.

August 27, 2025 at 4:43 PM
Because everything is automatic, we can probe models.
What motifs are driving model predictions? Calculate attributions, call + annotate seqlets, and count the annotations!
BPNet is relying on MYC, whereas Beluga is relying on many more TFs. Easy comparison now.
What motifs are driving model predictions? Calculate attributions, call + annotate seqlets, and count the annotations!
BPNet is relying on MYC, whereas Beluga is relying on many more TFs. Easy comparison now.
People *talk* about seqlets a lot but tangermeme is the first package for complete functionality.
Here is a complete example of using tangermeme for attributions, seqlet calling + annotation, and plotting, to visualize what five models think of the same locus
Here is a complete example of using tangermeme for attributions, seqlet calling + annotation, and plotting, to visualize what five models think of the same locus

August 27, 2025 at 4:40 PM
People *talk* about seqlets a lot but tangermeme is the first package for complete functionality.
Here is a complete example of using tangermeme for attributions, seqlet calling + annotation, and plotting, to visualize what five models think of the same locus
Here is a complete example of using tangermeme for attributions, seqlet calling + annotation, and plotting, to visualize what five models think of the same locus
Expanding past these implementations, tangermeme has a large focus on automatic seqlet calling and usage. Seqlets are short contiguous spans of high-attribution characters that usually correspond to the binding of a TF.

August 27, 2025 at 4:39 PM
Expanding past these implementations, tangermeme has a large focus on automatic seqlet calling and usage. Seqlets are short contiguous spans of high-attribution characters that usually correspond to the binding of a TF.
Past simply re-implementing algorithms people use (in a convenient repo), tangermeme offers flexibility not usually offers in other implementations.
As an example, instead of calculating variant effect as predictions before/after a substitution, why not look at attributions?
As an example, instead of calculating variant effect as predictions before/after a substitution, why not look at attributions?

August 27, 2025 at 4:35 PM
Past simply re-implementing algorithms people use (in a convenient repo), tangermeme offers flexibility not usually offers in other implementations.
As an example, instead of calculating variant effect as predictions before/after a substitution, why not look at attributions?
As an example, instead of calculating variant effect as predictions before/after a substitution, why not look at attributions?
This care extends to each of our operations. For example, one-hot encoding the entirety of chr1 takes <2s on a single thread. This is significantly faster than other one-hot encoding methods out there, and is fast enough to enable real-time batch generation from FASTAs.

August 27, 2025 at 4:33 PM
This care extends to each of our operations. For example, one-hot encoding the entirety of chr1 takes <2s on a single thread. This is significantly faster than other one-hot encoding methods out there, and is fast enough to enable real-time batch generation from FASTAs.
By focusing in this manner, we can "delve" deeply into these downstream algorithms. For instance, we found a bug in many DeepLIFT/SHAP implementations that will cause them to silently fail when you don't register your operations. Didn't know you needed to do that? Same!

August 27, 2025 at 4:29 PM
By focusing in this manner, we can "delve" deeply into these downstream algorithms. For instance, we found a bug in many DeepLIFT/SHAP implementations that will cause them to silently fail when you don't register your operations. Didn't know you needed to do that? Same!
tangermeme is a toolkit that implements "everything-but-the-model" for genomic machine learning.
This includes sequence manipulations, batched predictions, attributions, ablations, marginalizations, variant effect prediction, design, etc...
This includes sequence manipulations, batched predictions, attributions, ablations, marginalizations, variant effect prediction, design, etc...

August 27, 2025 at 4:24 PM
tangermeme is a toolkit that implements "everything-but-the-model" for genomic machine learning.
This includes sequence manipulations, batched predictions, attributions, ablations, marginalizations, variant effect prediction, design, etc...
This includes sequence manipulations, batched predictions, attributions, ablations, marginalizations, variant effect prediction, design, etc...
now i get to be happy, right?

August 20, 2025 at 12:25 PM
now i get to be happy, right?



sitting across the train from a very polite customer

August 14, 2025 at 1:15 PM
sitting across the train from a very polite customer
medium demand expected

July 2, 2025 at 11:03 AM
medium demand expected
Thank you, Google Flights, for recommending this 10 hour layover in Athens first by "convenience" when trying to find a Frankfurt -> Vienna flight.

June 30, 2025 at 5:54 PM
Thank you, Google Flights, for recommending this 10 hour layover in Athens first by "convenience" when trying to find a Frankfurt -> Vienna flight.
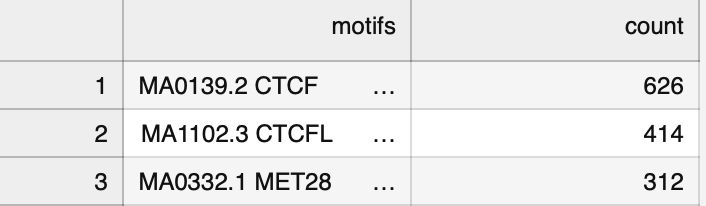
When running the pipleine, the seqlets will be annotated using tomtom-lite + motif database, and counted so you get the top driving motifs. For example, for a CTCF model, here are the seqlet counts when mapped to JASPAR, with MET28 overlapping one of the fingers in CTCF.
June 18, 2025 at 7:46 PM
When running the pipleine, the seqlets will be annotated using tomtom-lite + motif database, and counted so you get the top driving motifs. For example, for a CTCF model, here are the seqlet counts when mapped to JASPAR, with MET28 overlapping one of the fingers in CTCF.
Honestly, one of the nicest stations I've ever been in. I'll even forgive them for having a J in the word.

June 16, 2025 at 9:02 AM
Honestly, one of the nicest stations I've ever been in. I'll even forgive them for having a J in the word.
First, Nikolaus Mandlburger revamped the `plot_logo` function to significantly improve display when there are many overlapping annotations. This happens frequently if you run FIMO to get motif hits and then want to compare those to attributions, for instance.

June 11, 2025 at 5:43 PM
First, Nikolaus Mandlburger revamped the `plot_logo` function to significantly improve display when there are many overlapping annotations. This happens frequently if you run FIMO to get motif hits and then want to compare those to attributions, for instance.
Previously, for me it was a pain to do something as simple as making logo plots for attributions. With tangermeme, it's only a few lines to calculate attributions for several models at the same locus and plot them.
With the boilerplate optimized, it's really easy to dig into loci like this.
With the boilerplate optimized, it's really easy to dig into loci like this.

June 11, 2025 at 5:32 PM
Previously, for me it was a pain to do something as simple as making logo plots for attributions. With tangermeme, it's only a few lines to calculate attributions for several models at the same locus and plot them.
With the boilerplate optimized, it's really easy to dig into loci like this.
With the boilerplate optimized, it's really easy to dig into loci like this.
The first three columns in the BED file are augmented with the motif name they most resemble and also the p-value of that hit. Because only the best match is reported and most target databases are redundant, you may want to be flexible with the results but still useful in practice.

June 9, 2025 at 12:16 PM
The first three columns in the BED file are augmented with the motif name they most resemble and also the p-value of that hit. Because only the best match is reported and most target databases are redundant, you may want to be flexible with the results but still useful in practice.
This is particularly helpful because, instead of going to the Tomtom site, submitting a query, waiting for the job to work its way through the cluster, and then getting the results... I can just almost immediately get results from the command-line.
Also comes with a little alignment visualization.
Also comes with a little alignment visualization.

June 9, 2025 at 12:12 PM
This is particularly helpful because, instead of going to the Tomtom site, submitting a query, waiting for the job to work its way through the cluster, and then getting the results... I can just almost immediately get results from the command-line.
Also comes with a little alignment visualization.
Also comes with a little alignment visualization.
I'm sorry Vienna but this weather needs to be made illegal.

June 3, 2025 at 8:25 PM
I'm sorry Vienna but this weather needs to be made illegal.
Tomtom-lite uses a few approximations to speed up computational bottlenecks, but these approximations do not significantly alter the p-values that one gets. These include an approximate median and hashing target database columns to reduce redundant calculations.

June 3, 2025 at 6:07 PM
Tomtom-lite uses a few approximations to speed up computational bottlenecks, but these approximations do not significantly alter the p-values that one gets. These include an approximate median and hashing target database columns to reduce redundant calculations.
Tomtom solves a simple problem: given two PWMs of variable lengths and information contents, is their similarity statistically significant?
This problem is taking on newfound importance with ML methods where these PWMs can be seqlets derived from feature attributions.
This problem is taking on newfound importance with ML methods where these PWMs can be seqlets derived from feature attributions.

June 3, 2025 at 6:03 PM
Tomtom solves a simple problem: given two PWMs of variable lengths and information contents, is their similarity statistically significant?
This problem is taking on newfound importance with ML methods where these PWMs can be seqlets derived from feature attributions.
This problem is taking on newfound importance with ML methods where these PWMs can be seqlets derived from feature attributions.
why yes I do have a grant under review

June 2, 2025 at 7:05 PM
why yes I do have a grant under review
me reviewing cool grants for a Swiss AI initiative that will provide them with lots of resources that i can't apply for

May 17, 2025 at 8:45 AM
me reviewing cool grants for a Swiss AI initiative that will provide them with lots of resources that i can't apply for