




James MacGlashan
@jmac-ai.bsky.social
Ask me about Reinforcement Learning
Research @ Sony AI
AI should learn from its experiences, not copy your data.
My website for answering RL questions: https://www.decisionsanddragons.com/
Views and posts are my own.
Research @ Sony AI
AI should learn from its experiences, not copy your data.
My website for answering RL questions: https://www.decisionsanddragons.com/
Views and posts are my own.
Guido's opinion that removing the GIL isn't good for Python on the whole is consistent with my opinion that Python is good, but a bad fit for AI.
Trying to force it to match AI's needs may be a mistake. AI should use another language (fingers crossed for Mojo).
www.odbms.org/blog/2025/10...
Trying to force it to match AI's needs may be a mistake. AI should use another language (fingers crossed for Mojo).
www.odbms.org/blog/2025/10...

October 12, 2025 at 4:11 PM
Guido's opinion that removing the GIL isn't good for Python on the whole is consistent with my opinion that Python is good, but a bad fit for AI.
Trying to force it to match AI's needs may be a mistake. AI should use another language (fingers crossed for Mojo).
www.odbms.org/blog/2025/10...
Trying to force it to match AI's needs may be a mistake. AI should use another language (fingers crossed for Mojo).
www.odbms.org/blog/2025/10...
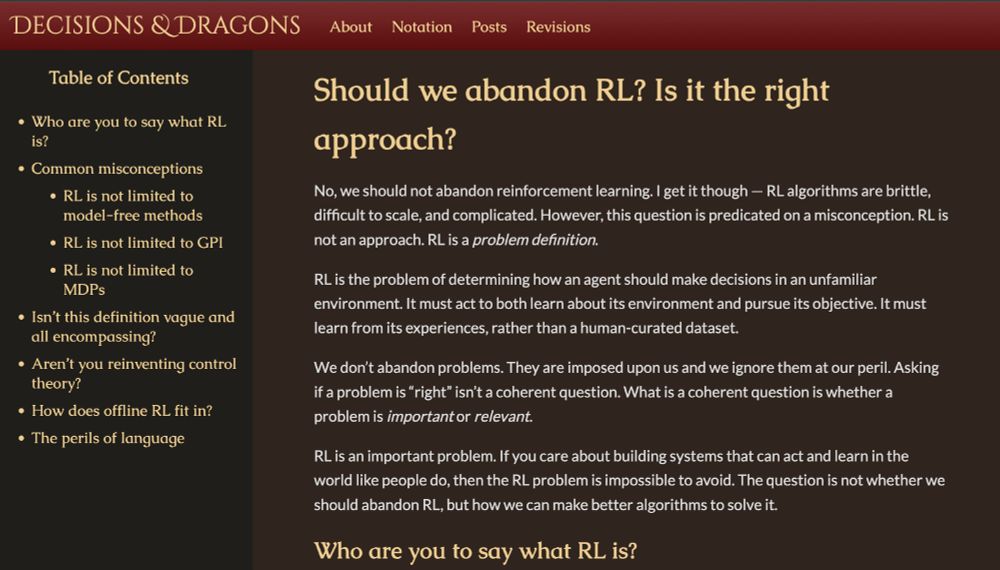
This one's been a long time coming.
In this post on Decisions & Dragons I answer "Should we abandon RL?"
The answer is obviously no, but people ask because they have a fundamental misunderstanding of what RL is.
RL is a problem, not an approach.
www.decisionsanddragons.com/posts/should...
In this post on Decisions & Dragons I answer "Should we abandon RL?"
The answer is obviously no, but people ask because they have a fundamental misunderstanding of what RL is.
RL is a problem, not an approach.
www.decisionsanddragons.com/posts/should...
August 15, 2025 at 11:30 PM
This one's been a long time coming.
In this post on Decisions & Dragons I answer "Should we abandon RL?"
The answer is obviously no, but people ask because they have a fundamental misunderstanding of what RL is.
RL is a problem, not an approach.
www.decisionsanddragons.com/posts/should...
In this post on Decisions & Dragons I answer "Should we abandon RL?"
The answer is obviously no, but people ask because they have a fundamental misunderstanding of what RL is.
RL is a problem, not an approach.
www.decisionsanddragons.com/posts/should...
Something I did a little differently for this answer is write some JAX code to compute various gradients for an example toy problem.
My hope is that will help ground out intutitions about REINFORCE's stochastic gradients and how baselines help reduce their error.
See example in image.
My hope is that will help ground out intutitions about REINFORCE's stochastic gradients and how baselines help reduce their error.
See example in image.

May 9, 2025 at 1:41 PM
Something I did a little differently for this answer is write some JAX code to compute various gradients for an example toy problem.
My hope is that will help ground out intutitions about REINFORCE's stochastic gradients and how baselines help reduce their error.
See example in image.
My hope is that will help ground out intutitions about REINFORCE's stochastic gradients and how baselines help reduce their error.
See example in image.
It's been a minute, but I've added a new Q&A to Decisions and Dragons!
This one answers "Why is it better to subtract a baseline in REINFORCE?"
Preview image attached. See the link for the full text.
1/2
www.decisionsanddragons.com/posts/why_is...
This one answers "Why is it better to subtract a baseline in REINFORCE?"
Preview image attached. See the link for the full text.
1/2
www.decisionsanddragons.com/posts/why_is...

May 9, 2025 at 1:41 PM
It's been a minute, but I've added a new Q&A to Decisions and Dragons!
This one answers "Why is it better to subtract a baseline in REINFORCE?"
Preview image attached. See the link for the full text.
1/2
www.decisionsanddragons.com/posts/why_is...
This one answers "Why is it better to subtract a baseline in REINFORCE?"
Preview image attached. See the link for the full text.
1/2
www.decisionsanddragons.com/posts/why_is...
Given the success of "thinking" in LLMs by using special sections for the thought vs response, it's inevitable that the next version is sections with reactions from different egos before making the response.
At that point, it is required to style the output like Disco Elysium.
At that point, it is required to style the output like Disco Elysium.

April 19, 2025 at 2:33 PM
Given the success of "thinking" in LLMs by using special sections for the thought vs response, it's inevitable that the next version is sections with reactions from different egos before making the response.
At that point, it is required to style the output like Disco Elysium.
At that point, it is required to style the output like Disco Elysium.

This is also working for me. So I tried 26 and it failed.

January 17, 2025 at 6:35 PM
This is also working for me. So I tried 26 and it failed.
I think you're using a more narrow definition of RL than the RL community. Those approaches fit comfortably in it. The DT work even calls itself RL.
In the first few slides of any intro on RL you will see this diagram. It's first because it captures the problem we are trying to solve.
In the first few slides of any intro on RL you will see this diagram. It's first because it captures the problem we are trying to solve.

December 31, 2024 at 11:15 PM
I think you're using a more narrow definition of RL than the RL community. Those approaches fit comfortably in it. The DT work even calls itself RL.
In the first few slides of any intro on RL you will see this diagram. It's first because it captures the problem we are trying to solve.
In the first few slides of any intro on RL you will see this diagram. It's first because it captures the problem we are trying to solve.

I'm referring to comments like the attached one.
It's described like AI is this independent entity that some day wakes up, rather than deliberate engineering process.
We don't need to "discover" things like this -- we know what we built and we chose to build it.
It's described like AI is this independent entity that some day wakes up, rather than deliberate engineering process.
We don't need to "discover" things like this -- we know what we built and we chose to build it.

December 11, 2024 at 5:56 PM
I'm referring to comments like the attached one.
It's described like AI is this independent entity that some day wakes up, rather than deliberate engineering process.
We don't need to "discover" things like this -- we know what we built and we chose to build it.
It's described like AI is this independent entity that some day wakes up, rather than deliberate engineering process.
We don't need to "discover" things like this -- we know what we built and we chose to build it.
Here's a suggestion: stop trying to solve the AI problem solely by fitting curated datasets.
Yes, that means we're not solving the AI problem "soon" since that's current thing we're good at.
Yes, the alternative is harder, but that's the challenge you adopt if you want to solve the AI problem.
Yes, that means we're not solving the AI problem "soon" since that's current thing we're good at.
Yes, the alternative is harder, but that's the challenge you adopt if you want to solve the AI problem.

December 1, 2024 at 5:22 PM
Here's a suggestion: stop trying to solve the AI problem solely by fitting curated datasets.
Yes, that means we're not solving the AI problem "soon" since that's current thing we're good at.
Yes, the alternative is harder, but that's the challenge you adopt if you want to solve the AI problem.
Yes, that means we're not solving the AI problem "soon" since that's current thing we're good at.
Yes, the alternative is harder, but that's the challenge you adopt if you want to solve the AI problem.
Q: What is the difference between model-based and model-free RL?
Full answer: www.decisionsanddragons.com/posts/model_...
Full answer: www.decisionsanddragons.com/posts/model_...

November 10, 2024 at 4:11 PM
Q: What is the difference between model-based and model-free RL?
Full answer: www.decisionsanddragons.com/posts/model_...
Full answer: www.decisionsanddragons.com/posts/model_...
Q: Why does the policy gradient include a log probability term?
Full answer: www.decisionsanddragons.com/posts/why_do...
Full answer: www.decisionsanddragons.com/posts/why_do...

November 10, 2024 at 4:11 PM
Q: Why does the policy gradient include a log probability term?
Full answer: www.decisionsanddragons.com/posts/why_do...
Full answer: www.decisionsanddragons.com/posts/why_do...
Q: What is the difference between V(s) and Q(s,a)?
Full answer: www.decisionsanddragons.com/posts/q_vs_v/
Full answer: www.decisionsanddragons.com/posts/q_vs_v/

November 10, 2024 at 4:11 PM
Q: What is the difference between V(s) and Q(s,a)?
Full answer: www.decisionsanddragons.com/posts/q_vs_v/
Full answer: www.decisionsanddragons.com/posts/q_vs_v/
Q: If Q-learning is off-policy, why doesn't it require importance sampling?
Full answer: www.decisionsanddragons.com/posts/q_lear...
Full answer: www.decisionsanddragons.com/posts/q_lear...

November 10, 2024 at 4:11 PM
Q: If Q-learning is off-policy, why doesn't it require importance sampling?
Full answer: www.decisionsanddragons.com/posts/q_lear...
Full answer: www.decisionsanddragons.com/posts/q_lear...
Q: Why is the DDPG gradient the product of the Q-function gradient and policy gradient?
Full answer: www.decisionsanddragons.com/posts/ddpg_g...
Full answer: www.decisionsanddragons.com/posts/ddpg_g...

November 10, 2024 at 4:11 PM
Q: Why is the DDPG gradient the product of the Q-function gradient and policy gradient?
Full answer: www.decisionsanddragons.com/posts/ddpg_g...
Full answer: www.decisionsanddragons.com/posts/ddpg_g...
Q: Why doesn't Q-learning work with continuous actions?
Full answer: www.decisionsanddragons.com/posts/q_lear...
Full answer: www.decisionsanddragons.com/posts/q_lear...

November 10, 2024 at 4:11 PM
Q: Why doesn't Q-learning work with continuous actions?
Full answer: www.decisionsanddragons.com/posts/q_lear...
Full answer: www.decisionsanddragons.com/posts/q_lear...
Q: What is the "horizon" in reinforcement learning?
Full answer: www.decisionsanddragons.com/posts/horizon/
Full answer: www.decisionsanddragons.com/posts/horizon/

November 10, 2024 at 4:11 PM
Q: What is the "horizon" in reinforcement learning?
Full answer: www.decisionsanddragons.com/posts/horizon/
Full answer: www.decisionsanddragons.com/posts/horizon/
Q: Why does experience replay require off-policy learning and how is it different from on-policy learning?
Full answer: www.decisionsanddragons.com/posts/off_po...
Full answer: www.decisionsanddragons.com/posts/off_po...

November 10, 2024 at 4:11 PM
Q: Why does experience replay require off-policy learning and how is it different from on-policy learning?
Full answer: www.decisionsanddragons.com/posts/off_po...
Full answer: www.decisionsanddragons.com/posts/off_po...
Reinforcement learning in #AI is hard, so I’ve made a website to collect answers I’ve given to common RL questions.
It's named Decisions & Dragons. It’s launching with 8 questions and answers, but I will add to it in the future.
A 🧵 to give a preview with the link below.
It's named Decisions & Dragons. It’s launching with 8 questions and answers, but I will add to it in the future.
A 🧵 to give a preview with the link below.

November 10, 2024 at 4:11 PM
Reinforcement learning in #AI is hard, so I’ve made a website to collect answers I’ve given to common RL questions.
It's named Decisions & Dragons. It’s launching with 8 questions and answers, but I will add to it in the future.
A 🧵 to give a preview with the link below.
It's named Decisions & Dragons. It’s launching with 8 questions and answers, but I will add to it in the future.
A 🧵 to give a preview with the link below.