




Juliette Marrie
@jlt-m.bsky.social
Postdoc at Kyutai
https://juliettemarrie.github.io
https://juliettemarrie.github.io
My experiments are run on a 48GB GPU. A 24GB GPU may be sufficient depending on the application. Feel free to reach out if you have any questions or run into any issues, and we can find a way to make it work within your memory constraints.
February 2, 2025 at 11:12 AM
My experiments are run on a 48GB GPU. A 24GB GPU may be sufficient depending on the application. Feel free to reach out if you have any questions or run into any issues, and we can find a way to make it work within your memory constraints.
Thanks! So far, I have been evaluating on standard datasets for foreground/background segmentation (SPIn-NeRF, NVOS) and open-vocabulary object localization (LERF). The object removal task you introduce in Semantics-Controlled GS could be another interesting application!
February 2, 2025 at 10:30 AM
Thanks! So far, I have been evaluating on standard datasets for foreground/background segmentation (SPIn-NeRF, NVOS) and open-vocabulary object localization (LERF). The object removal task you introduce in Semantics-Controlled GS could be another interesting application!
Uplifting is implemented in the forward rendering process, so it is as fast as forward rendering. Experimentally, it takes around 2ms per image per feature dimension. For example, uplifting 100 DINOv2 feature maps of dimension 40 (PCA-reduced) takes about 9s. See Appendix B.1 for more details.
January 31, 2025 at 4:36 PM
Uplifting is implemented in the forward rendering process, so it is as fast as forward rendering. Experimentally, it takes around 2ms per image per feature dimension. For example, uplifting 100 DINOv2 feature maps of dimension 40 (PCA-reduced) takes about 9s. See Appendix B.1 for more details.
(3/3) LUDVIG uses a graph diffusion mechanism to refine 3D features, such as coarse segmentation masks, by leveraging 3D scene geometry and pairwise similarities induced by DINOv2.
January 31, 2025 at 9:59 AM
(3/3) LUDVIG uses a graph diffusion mechanism to refine 3D features, such as coarse segmentation masks, by leveraging 3D scene geometry and pairwise similarities induced by DINOv2.
(2/3) We propose a simple, parameter-free aggregation mechanism, based on alpha-weighted multi-view blending of 2D pixel features in the forward rendering process.
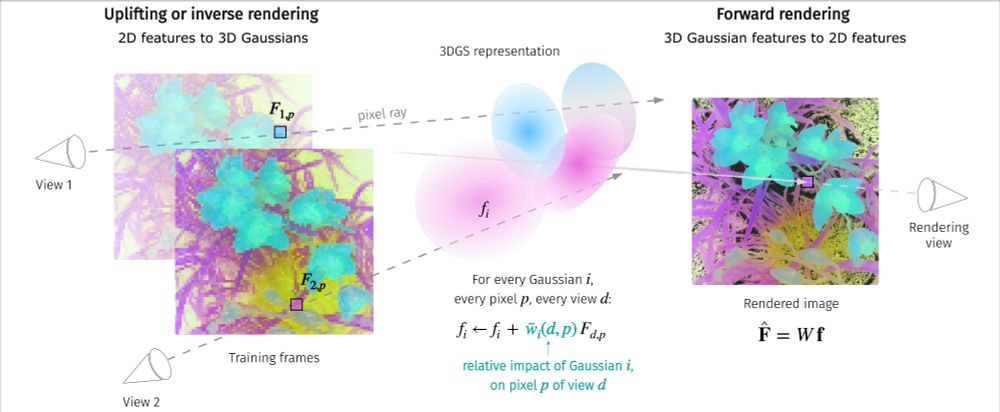
January 31, 2025 at 9:59 AM
(2/3) We propose a simple, parameter-free aggregation mechanism, based on alpha-weighted multi-view blending of 2D pixel features in the forward rendering process.