



Jessy Li
@jessyjli.bsky.social
https://jessyli.com Associate Professor, UT Austin Linguistics.
Part of UT Computational Linguistics https://sites.utexas.edu/compling/ and UT NLP https://www.nlp.utexas.edu/
Part of UT Computational Linguistics https://sites.utexas.edu/compling/ and UT NLP https://www.nlp.utexas.edu/
Incredibly honored to serve as #EMNLP 2026 Program Chair along with @sunipadev.bsky.social and Hung-yi Lee, and General Chair @andre-t-martins.bsky.social. Looking forward to Budapest!!
(With thanks to Lisa Chuyuan Li who took this photo in Suzhou!)
(With thanks to Lisa Chuyuan Li who took this photo in Suzhou!)

November 8, 2025 at 2:39 AM
Incredibly honored to serve as #EMNLP 2026 Program Chair along with @sunipadev.bsky.social and Hung-yi Lee, and General Chair @andre-t-martins.bsky.social. Looking forward to Budapest!!
(With thanks to Lisa Chuyuan Li who took this photo in Suzhou!)
(With thanks to Lisa Chuyuan Li who took this photo in Suzhou!)
🚨 Does your LLM really understand code -- or is it just really good at remembering it?
We built **PLSemanticsBench** to find out.
The results: a wild mix.
✅The Brilliant:
Top reasoning models can execute complex, fuzzer-generated programs -- even with 5+ levels of nested loops! 🤯
❌The Brittle: 🧵
We built **PLSemanticsBench** to find out.
The results: a wild mix.
✅The Brilliant:
Top reasoning models can execute complex, fuzzer-generated programs -- even with 5+ levels of nested loops! 🤯
❌The Brittle: 🧵


October 14, 2025 at 2:33 AM
🚨 Does your LLM really understand code -- or is it just really good at remembering it?
We built **PLSemanticsBench** to find out.
The results: a wild mix.
✅The Brilliant:
Top reasoning models can execute complex, fuzzer-generated programs -- even with 5+ levels of nested loops! 🤯
❌The Brittle: 🧵
We built **PLSemanticsBench** to find out.
The results: a wild mix.
✅The Brilliant:
Top reasoning models can execute complex, fuzzer-generated programs -- even with 5+ levels of nested loops! 🤯
❌The Brittle: 🧵
On my way to #COLM2025 🍁
Check out jessyli.com/colm2025
QUDsim: Discourse templates in LLM stories arxiv.org/abs/2504.09373
EvalAgent: retrieval-based eval targeting implicit criteria arxiv.org/abs/2504.15219
RoboInstruct: code generation for robotics with simulators arxiv.org/abs/2405.20179
Check out jessyli.com/colm2025
QUDsim: Discourse templates in LLM stories arxiv.org/abs/2504.09373
EvalAgent: retrieval-based eval targeting implicit criteria arxiv.org/abs/2504.15219
RoboInstruct: code generation for robotics with simulators arxiv.org/abs/2405.20179

October 6, 2025 at 3:50 PM
On my way to #COLM2025 🍁
Check out jessyli.com/colm2025
QUDsim: Discourse templates in LLM stories arxiv.org/abs/2504.09373
EvalAgent: retrieval-based eval targeting implicit criteria arxiv.org/abs/2504.15219
RoboInstruct: code generation for robotics with simulators arxiv.org/abs/2405.20179
Check out jessyli.com/colm2025
QUDsim: Discourse templates in LLM stories arxiv.org/abs/2504.09373
EvalAgent: retrieval-based eval targeting implicit criteria arxiv.org/abs/2504.15219
RoboInstruct: code generation for robotics with simulators arxiv.org/abs/2405.20179
The Echoes in AI paper showed quite the opposite with also a story continuation setup.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.



August 12, 2025 at 9:01 PM
The Echoes in AI paper showed quite the opposite with also a story continuation setup.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.
Finally, we consider if LLMs can introspect (= direct rate the salience of questions), if those direct ratings correlate with their behavior and with human perceptions of salience. Surprisingly, LLM behavior only weakly correlates in those settings. (5/6)

February 21, 2025 at 6:15 PM
Finally, we consider if LLMs can introspect (= direct rate the salience of questions), if those direct ratings correlate with their behavior and with human perceptions of salience. Surprisingly, LLM behavior only weakly correlates in those settings. (5/6)
We can use the CSM to understand if any two models have a similar notion of salience. Running a large-scale study with 13 LLMs on four genres (medicine, astrophysics, NLP, meetings), we find that models' notion of salience is highly consistent with itself, and across models. (4/6)

February 21, 2025 at 6:15 PM
We can use the CSM to understand if any two models have a similar notion of salience. Running a large-scale study with 13 LLMs on four genres (medicine, astrophysics, NLP, meetings), we find that models' notion of salience is highly consistent with itself, and across models. (4/6)
Second, we conceptualize salience as the answerability of domain-relevant questions on the summaries. More important questions can be answered even with shorter summaries. Our Content Salience Maps (CSMs) systematically track this. (3/6)

February 21, 2025 at 6:15 PM
Second, we conceptualize salience as the answerability of domain-relevant questions on the summaries. More important questions can be answered even with shorter summaries. Our Content Salience Maps (CSMs) systematically track this. (3/6)
First, we devise a behavioral probe: when we give LLMs an increasingly tight budget to summarize texts (e.g., 10, 20, 50, 100, 200 words), we posit that the least important (to the LLM) information is dropped first. 🔎 (2/6)

February 21, 2025 at 6:15 PM
First, we devise a behavioral probe: when we give LLMs an increasingly tight budget to summarize texts (e.g., 10, 20, 50, 100, 200 words), we posit that the least important (to the LLM) information is dropped first. 🔎 (2/6)
Do you want to know what information LLMs prioritize in text synthesis tasks? Here's a short 🧵 about our new paper, led by Jan Trienes: an interpretable framework for salience analysis in LLMs.
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)

February 21, 2025 at 6:15 PM
Do you want to know what information LLMs prioritize in text synthesis tasks? Here's a short 🧵 about our new paper, led by Jan Trienes: an interpretable framework for salience analysis in LLMs.
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)
We at UT Linguistics are hiring for 🔥 2 faculty positions in Computational Linguistics! Assistant or Associate professors, deadline Dec 1.
UT has a super vibrant comp ling & #nlp community!!
Apply here 👉 apply.interfolio.com/158280
UT has a super vibrant comp ling & #nlp community!!
Apply here 👉 apply.interfolio.com/158280
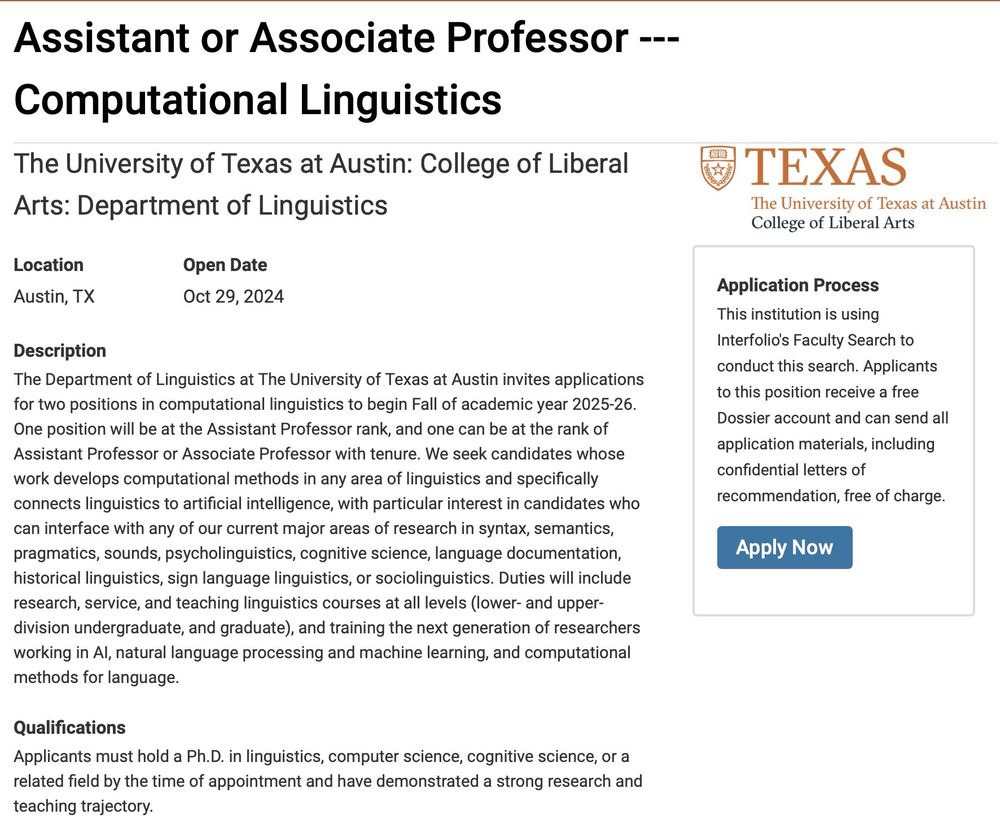
November 19, 2024 at 10:45 PM
We at UT Linguistics are hiring for 🔥 2 faculty positions in Computational Linguistics! Assistant or Associate professors, deadline Dec 1.
UT has a super vibrant comp ling & #nlp community!!
Apply here 👉 apply.interfolio.com/158280
UT has a super vibrant comp ling & #nlp community!!
Apply here 👉 apply.interfolio.com/158280
Wednesday at #EMNLP: @yatingwu.bsky.social will present our work connecting curiosity and questions in discourse. We built strong models to predict salience, outperforming large LLMs.
👉[Oral] Discourse+Phonology+Syntax2 10:30-12:00 @ Flagler
also w/ Ritika Mangla @gregdnlp.bsky.social Alex Dimakis
👉[Oral] Discourse+Phonology+Syntax2 10:30-12:00 @ Flagler
also w/ Ritika Mangla @gregdnlp.bsky.social Alex Dimakis

November 13, 2024 at 5:45 AM
Wednesday at #EMNLP: @yatingwu.bsky.social will present our work connecting curiosity and questions in discourse. We built strong models to predict salience, outperforming large LLMs.
👉[Oral] Discourse+Phonology+Syntax2 10:30-12:00 @ Flagler
also w/ Ritika Mangla @gregdnlp.bsky.social Alex Dimakis
👉[Oral] Discourse+Phonology+Syntax2 10:30-12:00 @ Flagler
also w/ Ritika Mangla @gregdnlp.bsky.social Alex Dimakis
The 2nd Disinformation Day @ UT Austin is a 🔥event with experts from AI/NLP, Linguistics, Philosophy, and media; join us in this virtual event (for free)! Details & registration at disinfoday.github.io

April 23, 2024 at 5:15 PM
The 2nd Disinformation Day @ UT Austin is a 🔥event with experts from AI/NLP, Linguistics, Philosophy, and media; join us in this virtual event (for free)! Details & registration at disinfoday.github.io
To appear #EMNLP2023! Can LMs simplify medical texts in non-English languages? We introduce⚕️MultiCochrane: the *first* multilingual, aligned dataset for this. arxiv.org/abs/2305.12532. Led by Sebastian Joseph, also w/ @byron.bsky.social Wei Xu

November 14, 2023 at 11:31 PM
To appear #EMNLP2023! Can LMs simplify medical texts in non-English languages? We introduce⚕️MultiCochrane: the *first* multilingual, aligned dataset for this. arxiv.org/abs/2305.12532. Led by Sebastian Joseph, also w/ @byron.bsky.social Wei Xu
Psych theories suggest that how we judge a situation (*cognitive appraisal*) leads to diverse emotions. Our #EMNLP 2023 Findings paper tests LLMs' ability to assess and explain such appraisals -- big gap between open-source LLMs and GPT3.5.
Paper arxiv.org/abs/2310.14389 w Hongli Zhan, Desmond Ong
Paper arxiv.org/abs/2310.14389 w Hongli Zhan, Desmond Ong


November 1, 2023 at 8:22 PM
Psych theories suggest that how we judge a situation (*cognitive appraisal*) leads to diverse emotions. Our #EMNLP 2023 Findings paper tests LLMs' ability to assess and explain such appraisals -- big gap between open-source LLMs and GPT3.5.
Paper arxiv.org/abs/2310.14389 w Hongli Zhan, Desmond Ong
Paper arxiv.org/abs/2310.14389 w Hongli Zhan, Desmond Ong
Can we use LLMs to help disseminate medical information more broadly? @byron.bsky.social, Mike Mackert, Wei Xu and I are hosting an online panel today at the HARC conference
at 4:30 EST/3:30 CST on Simplifying Medical Texts with Large Language Models! harcconf.org/agenda-monda...
at 4:30 EST/3:30 CST on Simplifying Medical Texts with Large Language Models! harcconf.org/agenda-monda...

October 30, 2023 at 2:21 PM
Can we use LLMs to help disseminate medical information more broadly? @byron.bsky.social, Mike Mackert, Wei Xu and I are hosting an online panel today at the HARC conference
at 4:30 EST/3:30 CST on Simplifying Medical Texts with Large Language Models! harcconf.org/agenda-monda...
at 4:30 EST/3:30 CST on Simplifying Medical Texts with Large Language Models! harcconf.org/agenda-monda...
To appear EMNLP2023: simplifying text involves explaining and elaborating concepts. Using QUDs in a question generation -> answering pipeline leads to much better generation of such elaborations!
arxiv.org/abs/2305.10387
w/ @yatingwu.bsky.social Will Sheffield @kmahowald.bsky.social
arxiv.org/abs/2305.10387
w/ @yatingwu.bsky.social Will Sheffield @kmahowald.bsky.social

October 25, 2023 at 11:57 PM
To appear EMNLP2023: simplifying text involves explaining and elaborating concepts. Using QUDs in a question generation -> answering pipeline leads to much better generation of such elaborations!
arxiv.org/abs/2305.10387
w/ @yatingwu.bsky.social Will Sheffield @kmahowald.bsky.social
arxiv.org/abs/2305.10387
w/ @yatingwu.bsky.social Will Sheffield @kmahowald.bsky.social
📢Our EMNLP 2023 work on Questions Under Discussion (QUD)! We introduce QUDeval, the first benchmark for evaluating the generation of open-ended questions and QUD parsing using linguistic principles.
Paper: arxiv.org/abs/2310.14520
w/ @yatingwu.bsky.social, Ritika Mangla, @gregdnlp.bsky.social
Paper: arxiv.org/abs/2310.14520
w/ @yatingwu.bsky.social, Ritika Mangla, @gregdnlp.bsky.social

October 24, 2023 at 10:22 PM
📢Our EMNLP 2023 work on Questions Under Discussion (QUD)! We introduce QUDeval, the first benchmark for evaluating the generation of open-ended questions and QUD parsing using linguistic principles.
Paper: arxiv.org/abs/2310.14520
w/ @yatingwu.bsky.social, Ritika Mangla, @gregdnlp.bsky.social
Paper: arxiv.org/abs/2310.14520
w/ @yatingwu.bsky.social, Ritika Mangla, @gregdnlp.bsky.social