



Jennifer Hu
@jennhu.bsky.social
Asst Prof at Johns Hopkins Cognitive Science • Director of the Group for Language and Intelligence (GLINT) ✨• Interested in all things language, cognition, and AI
jennhu.github.io
jennhu.github.io
This work was done with an amazing team: @wegotlieb.bsky.social, @siyuansong.bsky.social, @kmahowald.bsky.social, @rplevy.bsky.social
Preprint (pre-TACL version): arxiv.org/abs/2510.16227
10/10
Preprint (pre-TACL version): arxiv.org/abs/2510.16227
10/10

November 10, 2025 at 10:11 PM
This work was done with an amazing team: @wegotlieb.bsky.social, @siyuansong.bsky.social, @kmahowald.bsky.social, @rplevy.bsky.social
Preprint (pre-TACL version): arxiv.org/abs/2510.16227
10/10
Preprint (pre-TACL version): arxiv.org/abs/2510.16227
10/10
As mentioned above, Prediction #3 shows that recent criticism about the overlap in probabilities across gram/ungram strings should NOT be interpreted as a failure of probability to tell us about grammaticality.
This overlap is to be expected if prob is influenced by factors other than gram. 7/10
This overlap is to be expected if prob is influenced by factors other than gram. 7/10

November 10, 2025 at 10:11 PM
As mentioned above, Prediction #3 shows that recent criticism about the overlap in probabilities across gram/ungram strings should NOT be interpreted as a failure of probability to tell us about grammaticality.
This overlap is to be expected if prob is influenced by factors other than gram. 7/10
This overlap is to be expected if prob is influenced by factors other than gram. 7/10
We use our framework to derive 3 predictions, which we validate empirically:
1. Correlation btwn the prob of string probs within minimal pairs
2. Correlation btwn LMs’ and humans’ deltas within minimal pairs
3. Poor separation btwn prob of unpaired grammatical and ungrammatical strings
6/10
1. Correlation btwn the prob of string probs within minimal pairs
2. Correlation btwn LMs’ and humans’ deltas within minimal pairs
3. Poor separation btwn prob of unpaired grammatical and ungrammatical strings
6/10

November 10, 2025 at 10:11 PM
We use our framework to derive 3 predictions, which we validate empirically:
1. Correlation btwn the prob of string probs within minimal pairs
2. Correlation btwn LMs’ and humans’ deltas within minimal pairs
3. Poor separation btwn prob of unpaired grammatical and ungrammatical strings
6/10
1. Correlation btwn the prob of string probs within minimal pairs
2. Correlation btwn LMs’ and humans’ deltas within minimal pairs
3. Poor separation btwn prob of unpaired grammatical and ungrammatical strings
6/10
New work to appear @ TACL!
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇

November 10, 2025 at 10:11 PM
New work to appear @ TACL!
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
We then test whether measures of forward-pass dynamics (including competitor interference, & others) predict signatures of processing in humans.
We find that dynamic measures improve prediction of human measures above static (final-layer) measures -- across models, domains, & modalities.
(7/12)
We find that dynamic measures improve prediction of human measures above static (final-layer) measures -- across models, domains, & modalities.
(7/12)

May 20, 2025 at 2:26 PM
We then test whether measures of forward-pass dynamics (including competitor interference, & others) predict signatures of processing in humans.
We find that dynamic measures improve prediction of human measures above static (final-layer) measures -- across models, domains, & modalities.
(7/12)
We find that dynamic measures improve prediction of human measures above static (final-layer) measures -- across models, domains, & modalities.
(7/12)
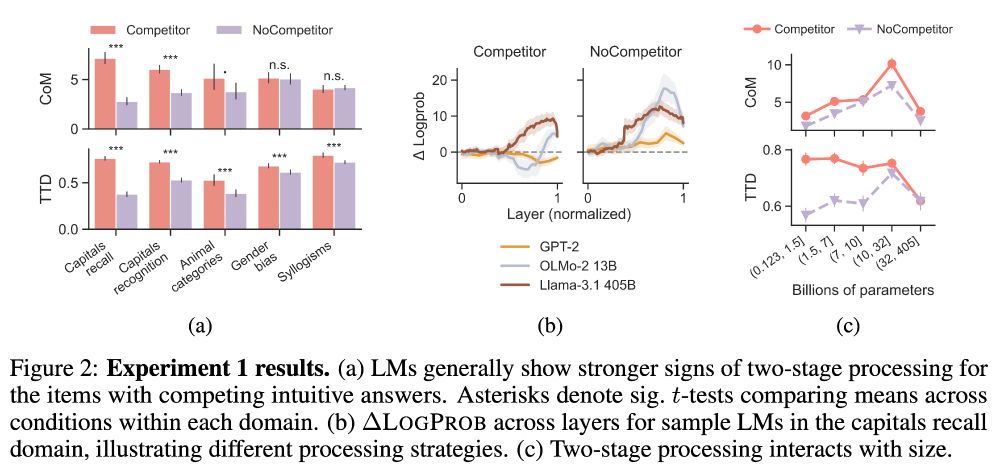
First, we use simple mech interp tools to measure competitor interference, such as evidence for “two-stage processing” and the “time to decision”.
We find that models indeed appear to initially favor a competing incorrect answer in the cases where we expect decision conflict in humans.
(6/12)
We find that models indeed appear to initially favor a competing incorrect answer in the cases where we expect decision conflict in humans.
(6/12)
May 20, 2025 at 2:26 PM
First, we use simple mech interp tools to measure competitor interference, such as evidence for “two-stage processing” and the “time to decision”.
We find that models indeed appear to initially favor a competing incorrect answer in the cases where we expect decision conflict in humans.
(6/12)
We find that models indeed appear to initially favor a competing incorrect answer in the cases where we expect decision conflict in humans.
(6/12)
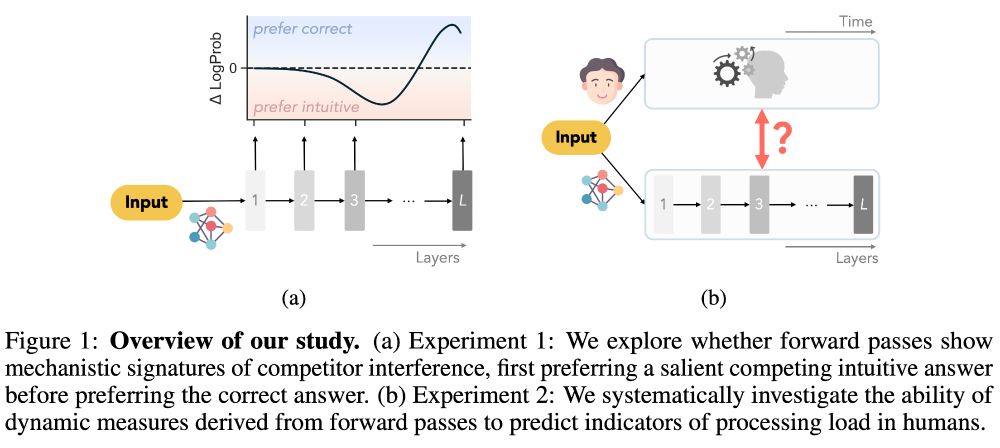
Excited to share a new preprint w/ @michael-lepori.bsky.social & Michael Franke!
A dominant approach in AI/cogsci uses *outputs* from AI models (eg logprobs) to predict human behavior.
But how does model *processing* (across layers in a forward pass) relate to human real-time processing? 👇 (1/12)
A dominant approach in AI/cogsci uses *outputs* from AI models (eg logprobs) to predict human behavior.
But how does model *processing* (across layers in a forward pass) relate to human real-time processing? 👇 (1/12)
May 20, 2025 at 2:26 PM
Excited to share a new preprint w/ @michael-lepori.bsky.social & Michael Franke!
A dominant approach in AI/cogsci uses *outputs* from AI models (eg logprobs) to predict human behavior.
But how does model *processing* (across layers in a forward pass) relate to human real-time processing? 👇 (1/12)
A dominant approach in AI/cogsci uses *outputs* from AI models (eg logprobs) to predict human behavior.
But how does model *processing* (across layers in a forward pass) relate to human real-time processing? 👇 (1/12)
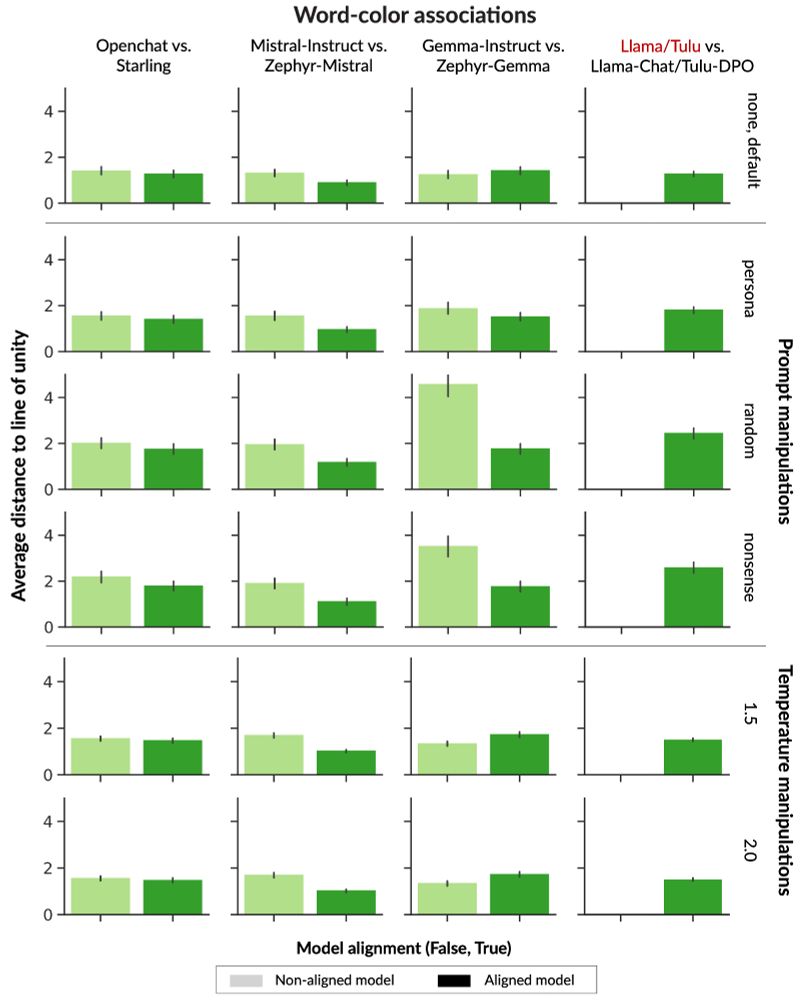
(6/9) We put a suite of aligned models, and their instruction fine-tuned counterparts, to the test and found:
* no model reaches human-like diversity of thought.
* aligned models show LESS conceptual diversity than instruction fine-tuned counterparts
* no model reaches human-like diversity of thought.
* aligned models show LESS conceptual diversity than instruction fine-tuned counterparts

February 10, 2025 at 2:22 PM
(6/9) We put a suite of aligned models, and their instruction fine-tuned counterparts, to the test and found:
* no model reaches human-like diversity of thought.
* aligned models show LESS conceptual diversity than instruction fine-tuned counterparts
* no model reaches human-like diversity of thought.
* aligned models show LESS conceptual diversity than instruction fine-tuned counterparts
(5/9) Our experiments are inspired by human studies in two domains with rich behavioral data.

February 10, 2025 at 2:22 PM
(5/9) Our experiments are inspired by human studies in two domains with rich behavioral data.
(4/9) We introduce a new way of measuring the conceptual diversity of synthetically-generated LLM "populations" by considering how its “individuals’” variability relates to that of the population.

February 10, 2025 at 2:22 PM
(4/9) We introduce a new way of measuring the conceptual diversity of synthetically-generated LLM "populations" by considering how its “individuals’” variability relates to that of the population.
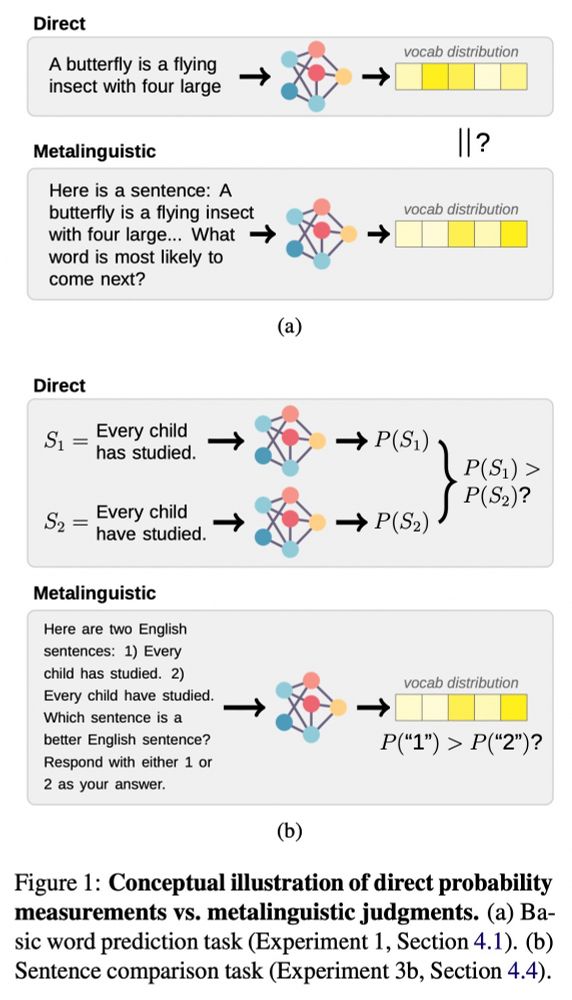
To researchers doing LLM evaluation: prompting is *not a substitute* for direct probability measurements. Check out the camera-ready version of our work, to appear at EMNLP 2023! (w/ @rplevy.bsky.social)
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...
October 24, 2023 at 3:03 PM
To researchers doing LLM evaluation: prompting is *not a substitute* for direct probability measurements. Check out the camera-ready version of our work, to appear at EMNLP 2023! (w/ @rplevy.bsky.social)
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...
Paper: arxiv.org/abs/2305.13264
Original thread: twitter.com/_jennhu/stat...