



Janet Liu
@janetlauyeung.bsky.social
🏫 asst. prof. of compling at university of pittsburgh
past:
🛎️ postdoc @mainlp.bsky.social, LMU Munich
🤠 PhD in CompLing from Georgetown
🕺🏻 x2 intern @Spotify @SpotifyResearch
https://janetlauyeung.github.io/
past:
🛎️ postdoc @mainlp.bsky.social, LMU Munich
🤠 PhD in CompLing from Georgetown
🕺🏻 x2 intern @Spotify @SpotifyResearch
https://janetlauyeung.github.io/

🤚🏼 co-organizing a workshop on the 10th!
September 12, 2025 at 7:59 PM
🤚🏼 co-organizing a workshop on the 10th!
💡 more findings, error analysis, and in-depth discussion are in our paper:
📄 arxiv.org/abs/2503.10515
🤖 github.com/mainlp/disco...
meet and chat with us at our poster in Vienna 🇦🇹 at #ACL2025NLP
🕰️ 11:00-12:30, Wednesday, July 30
📍 Hall 4/5 Session 12: IP-Posters
📄 arxiv.org/abs/2503.10515
🤖 github.com/mainlp/disco...
meet and chat with us at our poster in Vienna 🇦🇹 at #ACL2025NLP
🕰️ 11:00-12:30, Wednesday, July 30
📍 Hall 4/5 Session 12: IP-Posters
July 10, 2025 at 12:38 PM
💡 more findings, error analysis, and in-depth discussion are in our paper:
📄 arxiv.org/abs/2503.10515
🤖 github.com/mainlp/disco...
meet and chat with us at our poster in Vienna 🇦🇹 at #ACL2025NLP
🕰️ 11:00-12:30, Wednesday, July 30
📍 Hall 4/5 Session 12: IP-Posters
📄 arxiv.org/abs/2503.10515
🤖 github.com/mainlp/disco...
meet and chat with us at our poster in Vienna 🇦🇹 at #ACL2025NLP
🕰️ 11:00-12:30, Wednesday, July 30
📍 Hall 4/5 Session 12: IP-Posters
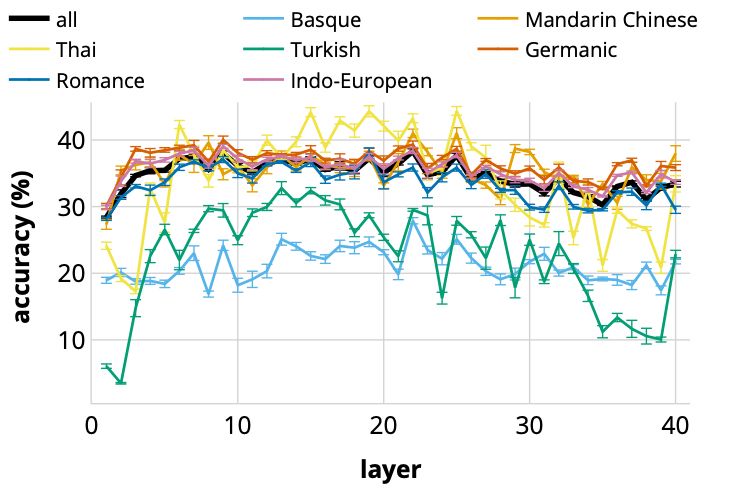
🔍 finding 3: discourse representations are best aligned across languages in the intermediate layers
July 10, 2025 at 12:38 PM
🔍 finding 3: discourse representations are best aligned across languages in the intermediate layers
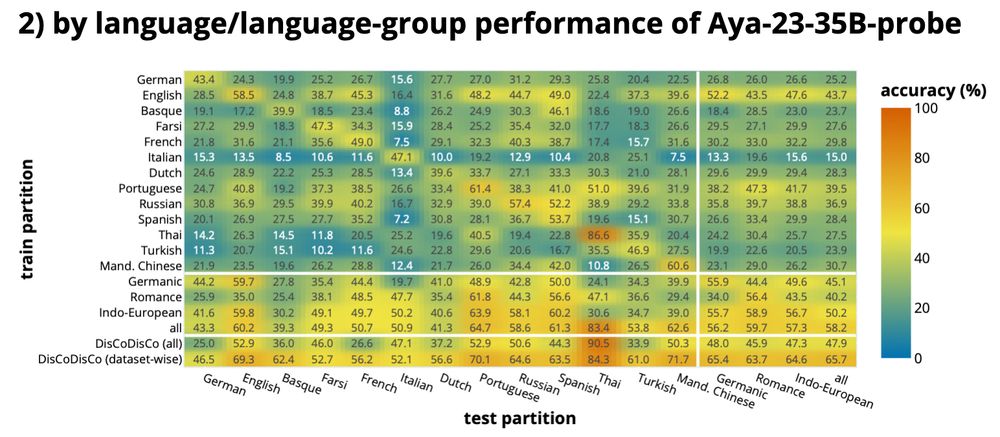
🌍 finding 2: our probes generalize across languages and language families
July 10, 2025 at 12:38 PM
🌍 finding 2: our probes generalize across languages and language families
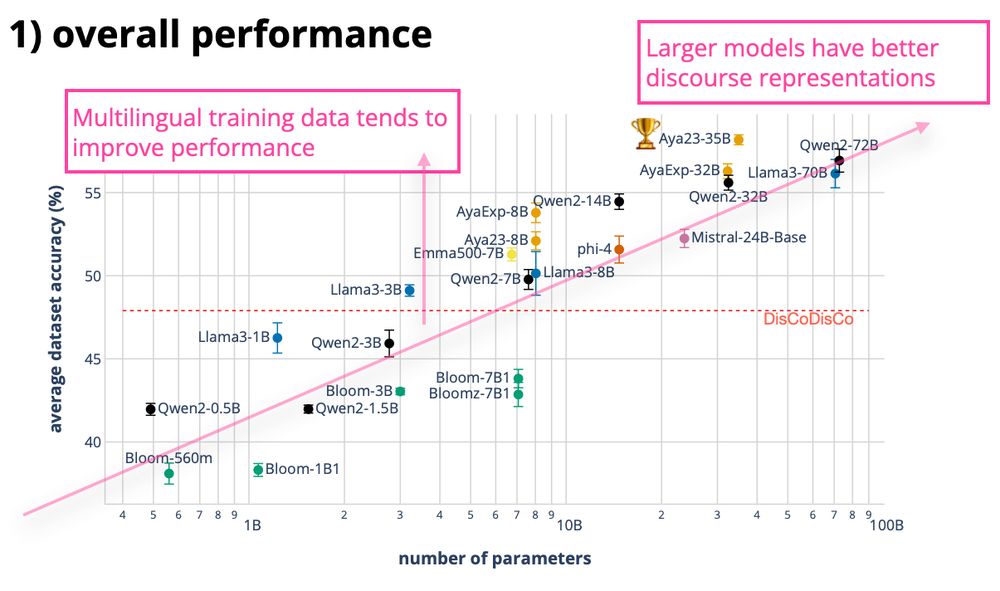
📌 finding 1: model size alone does not lead to discourse probing success; instead, multilingual training, dataset composition, and language-specific factors play significant roles
July 10, 2025 at 12:38 PM
📌 finding 1: model size alone does not lead to discourse probing success; instead, multilingual training, dataset composition, and language-specific factors play significant roles
🧪 for 23 SOTA LLMs, we use a probing approach to test whether their representations encode information relevant to discourse relation classification on DISRPT 2023, which covers 13 languages, four frameworks, 26 datasets, and various genres, domains, and modalities
July 10, 2025 at 12:38 PM
🧪 for 23 SOTA LLMs, we use a probing approach to test whether their representations encode information relevant to discourse relation classification on DISRPT 2023, which covers 13 languages, four frameworks, 26 datasets, and various genres, domains, and modalities
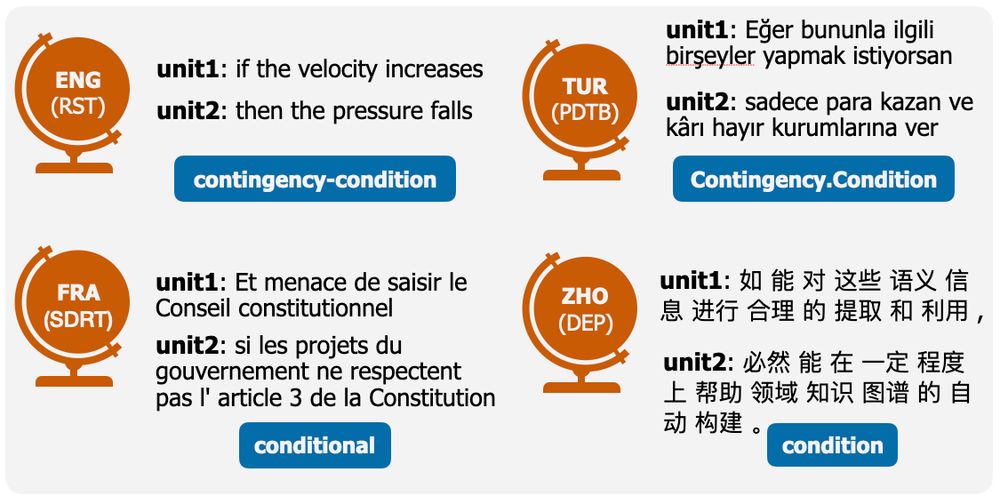
❓problem: discourse relations are central to NLU, but current work is primarily fragmented across frameworks & languages
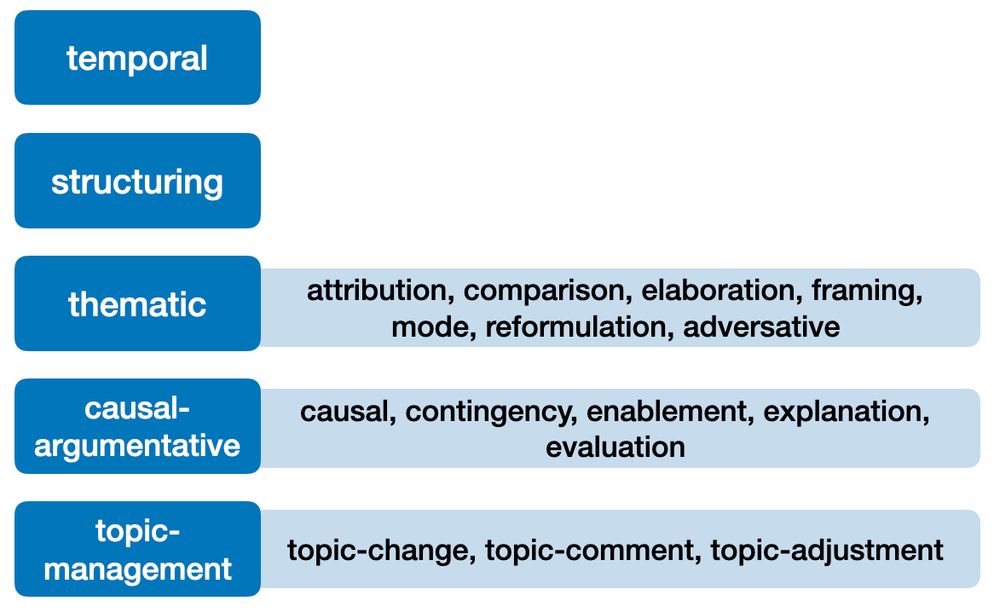
🔧 solution: we proposed a unified label set of 17 relations across 4 discourse frameworks. This lets us compare model behavior across corpora, languages, and annotation schemes
🔧 solution: we proposed a unified label set of 17 relations across 4 discourse frameworks. This lets us compare model behavior across corpora, languages, and annotation schemes
July 10, 2025 at 12:38 PM
❓problem: discourse relations are central to NLU, but current work is primarily fragmented across frameworks & languages
🔧 solution: we proposed a unified label set of 17 relations across 4 discourse frameworks. This lets us compare model behavior across corpora, languages, and annotation schemes
🔧 solution: we proposed a unified label set of 17 relations across 4 discourse frameworks. This lets us compare model behavior across corpora, languages, and annotation schemes
my amazing co-organizers: @assenmacher.bsky.social Jacob Beck, @barbaraplank.bsky.social , @stephnie.bsky.social, Frauke Kreuter, Gina Walejko
May 16, 2025 at 1:24 PM
my amazing co-organizers: @assenmacher.bsky.social Jacob Beck, @barbaraplank.bsky.social , @stephnie.bsky.social, Frauke Kreuter, Gina Walejko