



Jana Straková
@janastrakova.bsky.social
Researcher at Charles University developing open-source tools for NLP. Parent of two kids and two cats.
Reposted by Jana Straková

EMNLP 2025 is over... and Milan Straka is bringing home an award! 🏆
CorPipe triumphed in the prestigious CRAC25 Shared Task, focusing on multilingual coreference resolution.
Did Milan just CRACk it? We certainly think so! 😉
🔗 Find out more at arxiv.org/abs/2509.17858
#EMNLP2025 #CorPipe #CRAC25
CorPipe triumphed in the prestigious CRAC25 Shared Task, focusing on multilingual coreference resolution.
Did Milan just CRACk it? We certainly think so! 😉
🔗 Find out more at arxiv.org/abs/2509.17858
#EMNLP2025 #CorPipe #CRAC25



November 11, 2025 at 1:49 PM
EMNLP 2025 is over... and Milan Straka is bringing home an award! 🏆
CorPipe triumphed in the prestigious CRAC25 Shared Task, focusing on multilingual coreference resolution.
Did Milan just CRACk it? We certainly think so! 😉
🔗 Find out more at arxiv.org/abs/2509.17858
#EMNLP2025 #CorPipe #CRAC25
CorPipe triumphed in the prestigious CRAC25 Shared Task, focusing on multilingual coreference resolution.
Did Milan just CRACk it? We certainly think so! 😉
🔗 Find out more at arxiv.org/abs/2509.17858
#EMNLP2025 #CorPipe #CRAC25
Reposted by Jana Straková
Great week at #TSD2025 in Erlangen! Our @ufal-cuni.bsky.social team presented 7 papers covering various topics from Czech speech assessment to multilingual morphology. Thanks to all attendees who engaged with our work! 🧵👇
#NLP #ComputationalLinguistics #CzechNLP #MachineLearning
#NLP #ComputationalLinguistics #CzechNLP #MachineLearning

September 1, 2025 at 2:29 PM
Great week at #TSD2025 in Erlangen! Our @ufal-cuni.bsky.social team presented 7 papers covering various topics from Czech speech assessment to multilingual morphology. Thanks to all attendees who engaged with our work! 🧵👇
#NLP #ComputationalLinguistics #CzechNLP #MachineLearning
#NLP #ComputationalLinguistics #CzechNLP #MachineLearning
On the final day of TSD 2025, I shared our work “Flexing in 73 Languages: A Single Small Model for Multilingual Inflection”. I am grateful for the discussions and feedback!

August 28, 2025 at 4:36 PM
On the final day of TSD 2025, I shared our work “Flexing in 73 Languages: A Single Small Model for Multilingual Inflection”. I am grateful for the discussions and feedback!
Great presentation by Petr Pechman on our work “Refining Czech GEC: Insights from a Multi-Experiment Approach” at TSD 2025:
arxiv.org/abs/2506.22402
arxiv.org/abs/2506.22402



August 27, 2025 at 11:44 AM
Great presentation by Petr Pechman on our work “Refining Czech GEC: Insights from a Multi-Experiment Approach” at TSD 2025:
arxiv.org/abs/2506.22402
arxiv.org/abs/2506.22402
🚀 Excited for Text, Speech and Dialogue 2025 starting today!
I’ll have two works there:
1️⃣ Refining Czech GEC: Insights from a Multi-Experiment Approach by Petr Pechman, Milan Straka, me, Jakub Náplava
2️⃣ Flexing in 73 Languages: A Single Small Model for Multilingual Inflection by Tomáš Sourada & me
I’ll have two works there:
1️⃣ Refining Czech GEC: Insights from a Multi-Experiment Approach by Petr Pechman, Milan Straka, me, Jakub Náplava
2️⃣ Flexing in 73 Languages: A Single Small Model for Multilingual Inflection by Tomáš Sourada & me
August 25, 2025 at 9:16 AM
🚀 Excited for Text, Speech and Dialogue 2025 starting today!
I’ll have two works there:
1️⃣ Refining Czech GEC: Insights from a Multi-Experiment Approach by Petr Pechman, Milan Straka, me, Jakub Náplava
2️⃣ Flexing in 73 Languages: A Single Small Model for Multilingual Inflection by Tomáš Sourada & me
I’ll have two works there:
1️⃣ Refining Czech GEC: Insights from a Multi-Experiment Approach by Petr Pechman, Milan Straka, me, Jakub Náplava
2️⃣ Flexing in 73 Languages: A Single Small Model for Multilingual Inflection by Tomáš Sourada & me
Reposted by Jana Straková
NameTag 3: A Tool and a Service for Multilingual/Multitagset NER
aclanthology.org/2025.acl-dem...
by @janastrakova.bsky.social and @straka-milan.bsky.social bsky.social
Open-source multilingual NER tool achieving state-of-the-art results on 21 datasets in 15 languages with a single 355M model.
aclanthology.org/2025.acl-dem...
by @janastrakova.bsky.social and @straka-milan.bsky.social bsky.social
Open-source multilingual NER tool achieving state-of-the-art results on 21 datasets in 15 languages with a single 355M model.

July 28, 2025 at 12:56 PM
NameTag 3: A Tool and a Service for Multilingual/Multitagset NER
aclanthology.org/2025.acl-dem...
by @janastrakova.bsky.social and @straka-milan.bsky.social bsky.social
Open-source multilingual NER tool achieving state-of-the-art results on 21 datasets in 15 languages with a single 355M model.
aclanthology.org/2025.acl-dem...
by @janastrakova.bsky.social and @straka-milan.bsky.social bsky.social
Open-source multilingual NER tool achieving state-of-the-art results on 21 datasets in 15 languages with a single 355M model.
Reposted by Jana Straková
#ACL2025NLP in Vienna 🇦🇹 starts today with 23 🤯 @ufal-cuni.bsky.social folks presenting their work both at the main conference and workshops. Check out our main conference papers today and on Wednesday 👇


July 28, 2025 at 7:27 AM
#ACL2025NLP in Vienna 🇦🇹 starts today with 23 🤯 @ufal-cuni.bsky.social folks presenting their work both at the main conference and workshops. Check out our main conference papers today and on Wednesday 👇
Our paper “NameTag 3: A Tool and a Service for Multilingual/Multitagset NER” was accepted to the ACL 2025 Systems Demonstration Track!
lindat.mff.cuni.cz/services/nam...
If you're attending ACL 2025, stop by our demo, we'd love to show you what it can do.
#ACL2025NLP #NLProc
lindat.mff.cuni.cz/services/nam...
If you're attending ACL 2025, stop by our demo, we'd love to show you what it can do.
#ACL2025NLP #NLProc
May 26, 2025 at 1:17 PM
Our paper “NameTag 3: A Tool and a Service for Multilingual/Multitagset NER” was accepted to the ACL 2025 Systems Demonstration Track!
lindat.mff.cuni.cz/services/nam...
If you're attending ACL 2025, stop by our demo, we'd love to show you what it can do.
#ACL2025NLP #NLProc
lindat.mff.cuni.cz/services/nam...
If you're attending ACL 2025, stop by our demo, we'd love to show you what it can do.
#ACL2025NLP #NLProc
Reposted by Jana Straková

V dalším díle našeho seriálu o mladých vědkyních z Informatické sekce Matfyzu nás do svého badatelského světa, do oblasti výpočetní lingvistiky, zavede Jana Straková.
🔗 www.matfyz.cz/clanky/holky...
🖥️ @ufal-cuni.bsky.social
🔗 www.matfyz.cz/clanky/holky...
🖥️ @ufal-cuni.bsky.social

May 21, 2025 at 1:14 PM
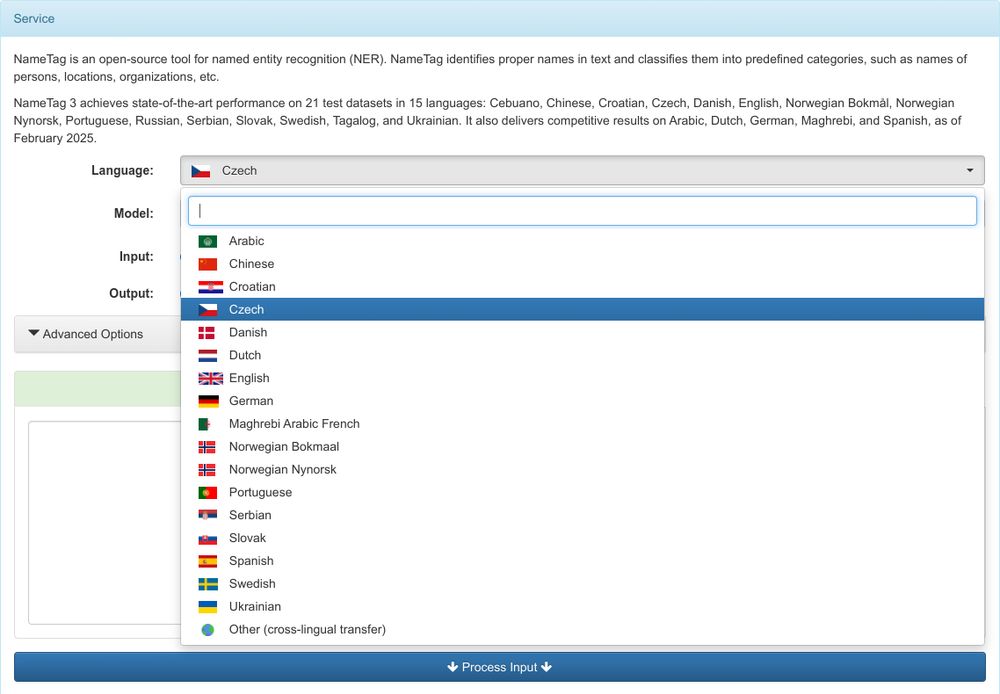
📢 NameTag 3.1 is here, now supporting 17 languages!
🎉 NameTag 3.1 achieves state of the art on 21 datasets across 15 languages.
🛞 Try the demo: lindat.mff.cuni.cz/services/nam...
🎉 NameTag 3.1 achieves state of the art on 21 datasets across 15 languages.
🛞 Try the demo: lindat.mff.cuni.cz/services/nam...
NameTag
lindat.mff.cuni.cz
April 15, 2025 at 1:05 PM
📢 NameTag 3.1 is here, now supporting 17 languages!
🎉 NameTag 3.1 achieves state of the art on 21 datasets across 15 languages.
🛞 Try the demo: lindat.mff.cuni.cz/services/nam...
🎉 NameTag 3.1 achieves state of the art on 21 datasets across 15 languages.
🛞 Try the demo: lindat.mff.cuni.cz/services/nam...
Taking the plunge! 👋 Hello, Bluesky! I'm new here, coming from the old place. It's nice to meet you all!
November 22, 2024 at 7:35 AM
Taking the plunge! 👋 Hello, Bluesky! I'm new here, coming from the old place. It's nice to meet you all!