



Joaquin Bravo
@jackbravo.github.io
Programmer from Guadalajara, Mexico. Developed Drupal for newspapers, magazines, and universities. Helped organize open source conferences in Latin America. Ex-Wizeline Director of Innovation. Currently works at Bixal, developing AI solutions.
Reposted by Joaquin Bravo

Foto de un servidor y @jackbravo.github.io nomás porque no es tan común toparme irl con personajes con presencia también aquí 😎

February 12, 2025 at 11:26 PM
Foto de un servidor y @jackbravo.github.io nomás porque no es tan común toparme irl con personajes con presencia también aquí 😎
Reposted by Joaquin Bravo

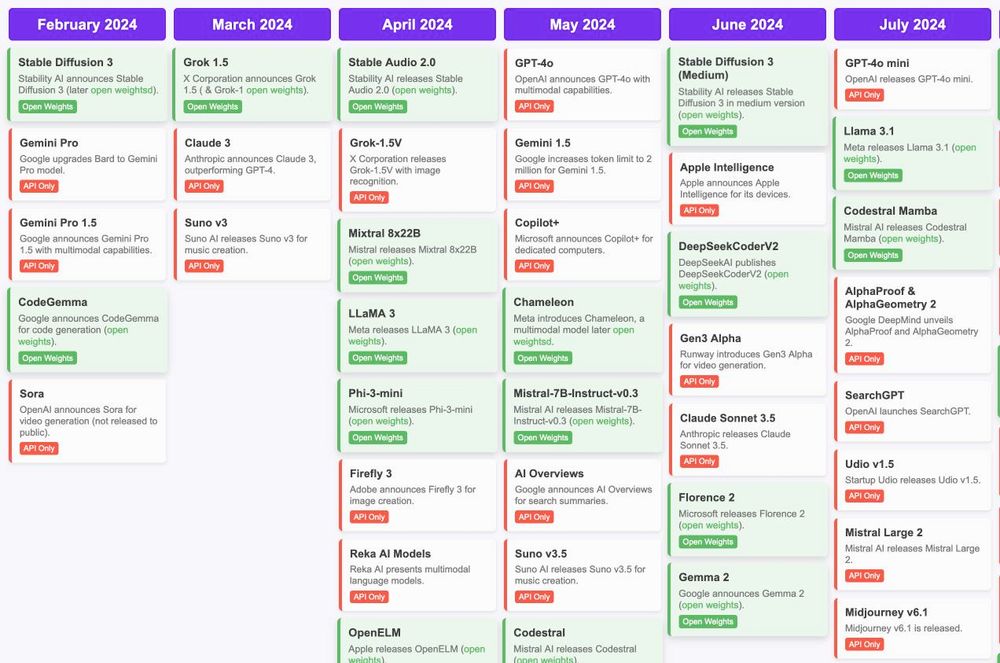
I really like this timeline of AI model releases in 2024 - I'd hoped to include something like this in my post but I ran out of time, and this one (by @reach-vb.hf.co is MUCH better than what I had planned huggingface.co/spaces/reach...
December 31, 2024 at 10:17 PM
I really like this timeline of AI model releases in 2024 - I'd hoped to include something like this in my post but I ran out of time, and this one (by @reach-vb.hf.co is MUCH better than what I had planned huggingface.co/spaces/reach...
Reposted by Joaquin Bravo

Great to see this trending on the @hf.co Hub!
I also wrote a short blog on why we're building this dataset: huggingface.co/blog/davanst...
I also wrote a short blog on why we're building this dataset: huggingface.co/blog/davanst...

December 23, 2024 at 10:52 PM
Great to see this trending on the @hf.co Hub!
I also wrote a short blog on why we're building this dataset: huggingface.co/blog/davanst...
I also wrote a short blog on why we're building this dataset: huggingface.co/blog/davanst...
Reposted by Joaquin Bravo

brew install mactop
github.com/context-labs...
github.com/context-labs...

November 23, 2024 at 8:02 PM
brew install mactop
github.com/context-labs...
github.com/context-labs...
Reposted by Joaquin Bravo

Track your own health privately, from @huggingface.bsky.social and @cyrilzakka.bsky.social
huggingface.co/blog/cyrilza...
huggingface.co/blog/cyrilza...

Halo: Open Source Health Tracking with Wearables
A Blog post by Cyril on Hugging Face
huggingface.co
November 22, 2024 at 3:22 AM
Track your own health privately, from @huggingface.bsky.social and @cyrilzakka.bsky.social
huggingface.co/blog/cyrilza...
huggingface.co/blog/cyrilza...
Reposted by Joaquin Bravo

🚀 @Qwen just dropped 2.5-Turbo!
1M token context (that's entire "War and Peace"!) + 4.3x faster processing speed 🔥
Check out the demo: https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
#QWEN
1M token context (that's entire "War and Peace"!) + 4.3x faster processing speed 🔥
Check out the demo: https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
#QWEN

November 18, 2024 at 8:55 PM
🚀 @Qwen just dropped 2.5-Turbo!
1M token context (that's entire "War and Peace"!) + 4.3x faster processing speed 🔥
Check out the demo: https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
#QWEN
1M token context (that's entire "War and Peace"!) + 4.3x faster processing speed 🔥
Check out the demo: https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
#QWEN
Reposted by Joaquin Bravo

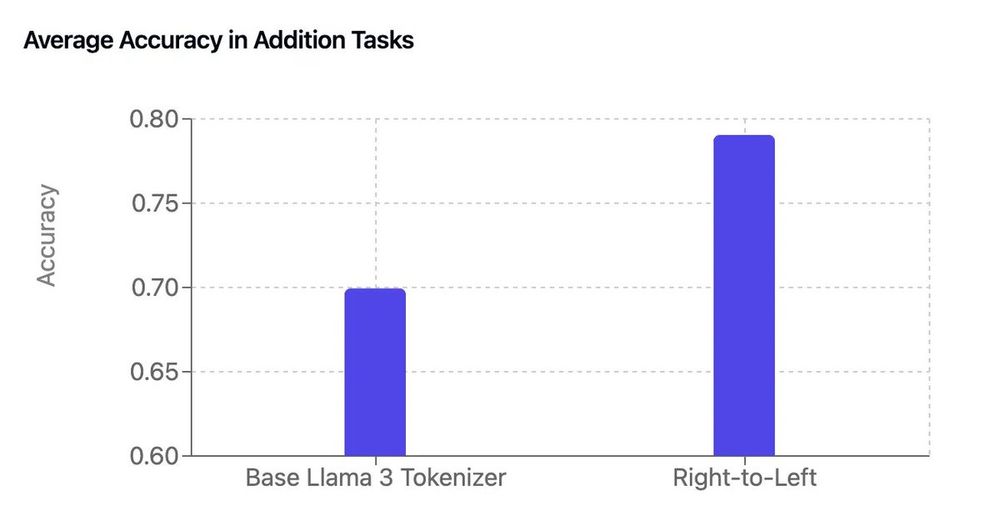
It's Sunday morning so taking a minute for a nerdy thread (on math, tokenizers and LLMs) of the work of our intern Garreth
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
November 24, 2024 at 11:05 AM
It's Sunday morning so taking a minute for a nerdy thread (on math, tokenizers and LLMs) of the work of our intern Garreth
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]