



Iris Groen
@irisgroen.bsky.social
Assistant Professor @UvA_Amsterdam | Cognitive neuroscience, Scene perception, Computational vision | Chair of CCN2025 | www.irisgroen.com
I’ve had 40 birthdays so far, but this is the first one chairing a major international conference 👩💻! Thanks to the nearly 1000 attendees of #CCN2025 for coming to my birthday this year 😉

August 14, 2025 at 7:32 AM
I’ve had 40 birthdays so far, but this is the first one chairing a major international conference 👩💻! Thanks to the nearly 1000 attendees of #CCN2025 for coming to my birthday this year 😉

On Tuesday,
@sargechris.bsky.social
will present a follow-up on her earlier ICLR paper (openreview.net/pdf?id=LM4PY...), where we performed large-scale benchmarking of video-DNNs agains the BOLD Moments fMRI dataset, to see how well such models are representationally aligned with the human brain;
@sargechris.bsky.social
will present a follow-up on her earlier ICLR paper (openreview.net/pdf?id=LM4PY...), where we performed large-scale benchmarking of video-DNNs agains the BOLD Moments fMRI dataset, to see how well such models are representationally aligned with the human brain;

August 10, 2025 at 3:20 PM
On Tuesday,
@sargechris.bsky.social
will present a follow-up on her earlier ICLR paper (openreview.net/pdf?id=LM4PY...), where we performed large-scale benchmarking of video-DNNs agains the BOLD Moments fMRI dataset, to see how well such models are representationally aligned with the human brain;
@sargechris.bsky.social
will present a follow-up on her earlier ICLR paper (openreview.net/pdf?id=LM4PY...), where we performed large-scale benchmarking of video-DNNs agains the BOLD Moments fMRI dataset, to see how well such models are representationally aligned with the human brain;
After preparing for a full year together with @neurosteven.bsky.social and all other amazing organizers
of @cogcompneuro.bsky.social, #CCN2025 is finally here!
While I'm proud of the entire program we put together, I'd now like to highlight my own lab's contributions, 6 posters total:
of @cogcompneuro.bsky.social, #CCN2025 is finally here!
While I'm proud of the entire program we put together, I'd now like to highlight my own lab's contributions, 6 posters total:

August 10, 2025 at 3:20 PM
After preparing for a full year together with @neurosteven.bsky.social and all other amazing organizers
of @cogcompneuro.bsky.social, #CCN2025 is finally here!
While I'm proud of the entire program we put together, I'd now like to highlight my own lab's contributions, 6 posters total:
of @cogcompneuro.bsky.social, #CCN2025 is finally here!
While I'm proud of the entire program we put together, I'd now like to highlight my own lab's contributions, 6 posters total:
Can we enhance DNN-human alignment for affordances? We tried three things: direct supervision with affordance labels, linguistic representations via captions, and probing a multi-modal LLM (ChatGPT!). While we saw improvements, none of these perfectly captured locomotive affordance representations.

June 16, 2025 at 11:34 AM
Can we enhance DNN-human alignment for affordances? We tried three things: direct supervision with affordance labels, linguistic representations via captions, and probing a multi-modal LLM (ChatGPT!). While we saw improvements, none of these perfectly captured locomotive affordance representations.
Moreover, the models showed quite poor alignment with the fMRI patterns we had measured for these scenes. And the unique affordance-related variance was not ‘explained away’ by the best-aligned DNN. Our second key finding!

June 16, 2025 at 11:34 AM
Moreover, the models showed quite poor alignment with the fMRI patterns we had measured for these scenes. And the unique affordance-related variance was not ‘explained away’ by the best-aligned DNN. Our second key finding!
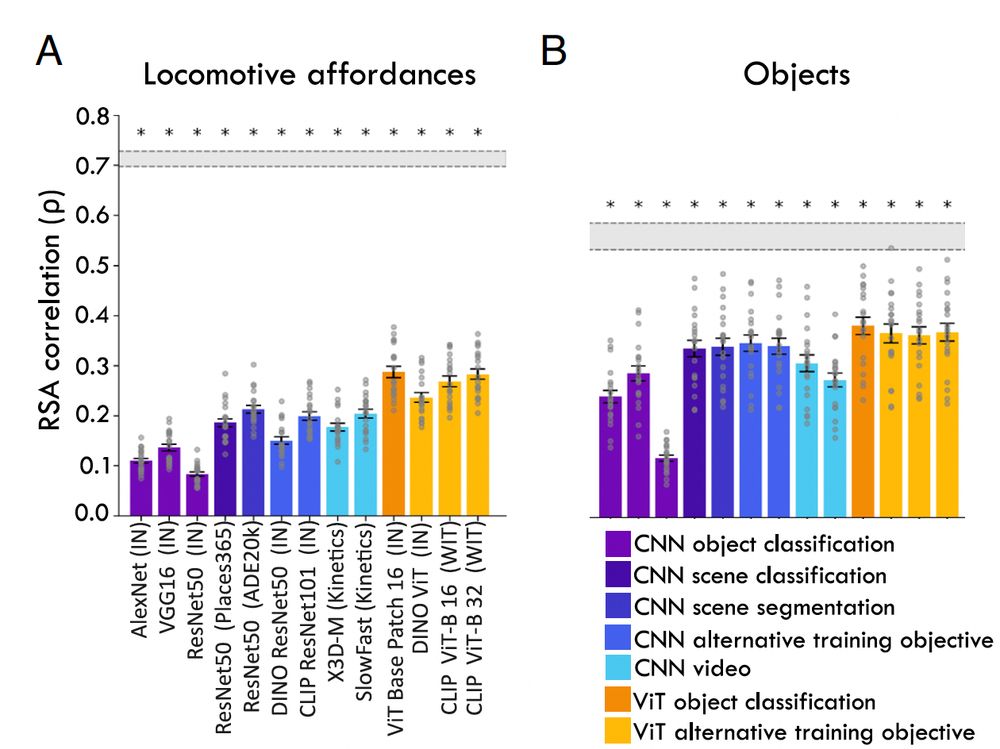
We tested a whole bunch of models, and it turns out that all models showed lower alignment with affordances than objects. This was true for models on various tasks – not just classic object or scene recognition, but also contrastive learning with text, self-supervised tasks, video, etc.
June 16, 2025 at 11:34 AM
We tested a whole bunch of models, and it turns out that all models showed lower alignment with affordances than objects. This was true for models on various tasks – not just classic object or scene recognition, but also contrastive learning with text, self-supervised tasks, video, etc.
Then, we measured MRI, and found that brain activity patterns in scene-selective visual regions also contained ‘unique’ variance reflecting locomotive affordance information only. Hence, demonstrating a ‘neural reality of affordances’ (PNAS Editor’s quote!) – our first key finding!

June 16, 2025 at 11:34 AM
Then, we measured MRI, and found that brain activity patterns in scene-selective visual regions also contained ‘unique’ variance reflecting locomotive affordance information only. Hence, demonstrating a ‘neural reality of affordances’ (PNAS Editor’s quote!) – our first key finding!
You might think: but this task is easy because you can just say ‘swimming’ if you see ‘water’, and ‘driving’ when you see ‘road’. But the answers were not trivially explained by such labels - almost 80% of the variation in the locomotive action ratings was unexplained by other scene properties!

June 16, 2025 at 11:34 AM
You might think: but this task is easy because you can just say ‘swimming’ if you see ‘water’, and ‘driving’ when you see ‘road’. But the answers were not trivially explained by such labels - almost 80% of the variation in the locomotive action ratings was unexplained by other scene properties!
This is a very easy task for humans: they respond in a split second, giving highly consistent answers. And these answers form a highly structured representational space, clearly separating different actions along meaningful dimensions, such as water-based vs. road-based activities.

June 16, 2025 at 11:34 AM
This is a very easy task for humans: they respond in a split second, giving highly consistent answers. And these answers form a highly structured representational space, clearly separating different actions along meaningful dimensions, such as water-based vs. road-based activities.
We showed participants images from real-world indoor and outdoor environments while they did a simple task: mark 6 ways (walking, driving, biking, swimming, boating, climbing) you could realistically move in this environment – i.e. indicate its locomotive action affordances.

June 16, 2025 at 11:34 AM
We showed participants images from real-world indoor and outdoor environments while they did a simple task: mark 6 ways (walking, driving, biking, swimming, boating, climbing) you could realistically move in this environment – i.e. indicate its locomotive action affordances.