




Clement POIRET
@int8.tech
Ph.D. in Neuroimaging | AI/Computer Vision Researcher | Making training and inference more efficient | 🇲🇫 CTO & Startup Founder | Linux Aficionado

'The limits of my language means the limits of my world' — Wittgenstein.
New blog post reading the hype around scaling LLMs to reach AGI through the lens of anthropology, philosophy, and cognition.
int8.tech/posts/rethin...
New blog post reading the hype around scaling LLMs to reach AGI through the lens of anthropology, philosophy, and cognition.
int8.tech/posts/rethin...

Rethinking Superintelligence without Language | int8 blog
Language is a model of the world, and all models are wrong, but some are useful.
int8.tech
March 22, 2025 at 7:40 PM
'The limits of my language means the limits of my world' — Wittgenstein.
New blog post reading the hype around scaling LLMs to reach AGI through the lens of anthropology, philosophy, and cognition.
int8.tech/posts/rethin...
New blog post reading the hype around scaling LLMs to reach AGI through the lens of anthropology, philosophy, and cognition.
int8.tech/posts/rethin...
Reposted by Clement POIRET

🔥🔥🔥 CV Folks, I have some news! We're organizing a 1-day meeting in center Paris on June 6th before CVPR called CVPR@Paris (similar as NeurIPS@Paris) 🥐🍾🥖🍷
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!


March 21, 2025 at 6:43 AM
🔥🔥🔥 CV Folks, I have some news! We're organizing a 1-day meeting in center Paris on June 6th before CVPR called CVPR@Paris (similar as NeurIPS@Paris) 🥐🍾🥖🍷
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
Reposted by Clement POIRET

🚀 Paper Release! 🚀
Curious about image retrieval and contrastive learning? We present:
📄 "All You Need to Know About Training Image Retrieval Models"
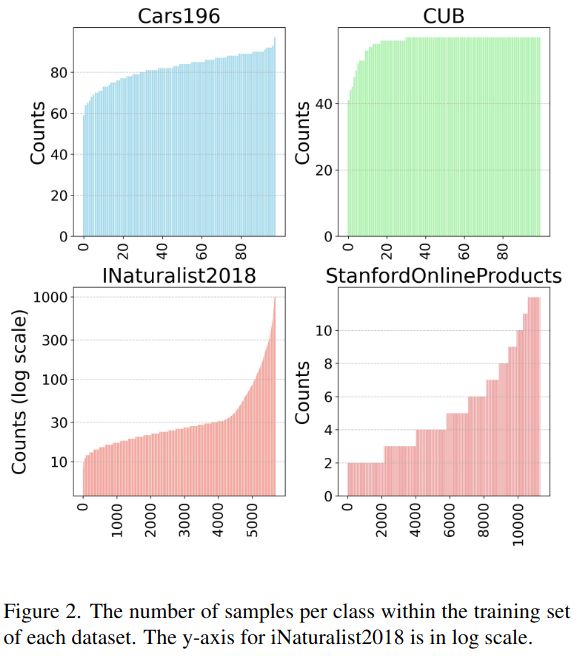
🔍 The most comprehensive retrieval benchmark—thousands of experiments across 4 datasets, dozens of losses, batch sizes, LRs, data labeling, and more!
Curious about image retrieval and contrastive learning? We present:
📄 "All You Need to Know About Training Image Retrieval Models"
🔍 The most comprehensive retrieval benchmark—thousands of experiments across 4 datasets, dozens of losses, batch sizes, LRs, data labeling, and more!

March 18, 2025 at 10:41 PM
🚀 Paper Release! 🚀
Curious about image retrieval and contrastive learning? We present:
📄 "All You Need to Know About Training Image Retrieval Models"
🔍 The most comprehensive retrieval benchmark—thousands of experiments across 4 datasets, dozens of losses, batch sizes, LRs, data labeling, and more!
Curious about image retrieval and contrastive learning? We present:
📄 "All You Need to Know About Training Image Retrieval Models"
🔍 The most comprehensive retrieval benchmark—thousands of experiments across 4 datasets, dozens of losses, batch sizes, LRs, data labeling, and more!
Following the release of DeepMind's TIPS model, I added support for text embeddings in Equimo. Just a few lines of code to embed text and images in the same space, enabling easy vision-language workflows in Jax.
Learn more at: github.com/clementpoire...
TIPS paper: arxiv.org/abs/2410.16512
Learn more at: github.com/clementpoire...
TIPS paper: arxiv.org/abs/2410.16512

March 14, 2025 at 2:56 PM
Following the release of DeepMind's TIPS model, I added support for text embeddings in Equimo. Just a few lines of code to embed text and images in the same space, enabling easy vision-language workflows in Jax.
Learn more at: github.com/clementpoire...
TIPS paper: arxiv.org/abs/2410.16512
Learn more at: github.com/clementpoire...
TIPS paper: arxiv.org/abs/2410.16512
SigLIP 2 has been recently released, so I just added support for it in my Jax model library, Equimo! Feel free to try it :)
github.com/clementpoire...
github.com/clementpoire...
February 24, 2025 at 8:19 PM
SigLIP 2 has been recently released, so I just added support for it in my Jax model library, Equimo! Feel free to try it :)
github.com/clementpoire...
github.com/clementpoire...
I just signed the exit of my own startup.
It's time to have some fun intermediate projects before the next big thing.
Let's take inspirations outside deep learning to come back stronger.
It's time to have some fun intermediate projects before the next big thing.
Let's take inspirations outside deep learning to come back stronger.

February 4, 2025 at 6:08 PM
I just signed the exit of my own startup.
It's time to have some fun intermediate projects before the next big thing.
Let's take inspirations outside deep learning to come back stronger.
It's time to have some fun intermediate projects before the next big thing.
Let's take inspirations outside deep learning to come back stronger.
Maybe a bit niche, but Helix is a great editor. Getting a good REPL experience is a bit tricky though, so I wrote a bit about it
int8.tech/posts/repl-p...
int8.tech/posts/repl-p...
REPL-Driven Programming with Helix, Zellij, and DevEnv | int8 blog
A simple guide to use a REPL with Helix
int8.tech
January 20, 2025 at 5:53 PM
Maybe a bit niche, but Helix is a great editor. Getting a good REPL experience is a bit tricky though, so I wrote a bit about it
int8.tech/posts/repl-p...
int8.tech/posts/repl-p...
Reposted by Clement POIRET

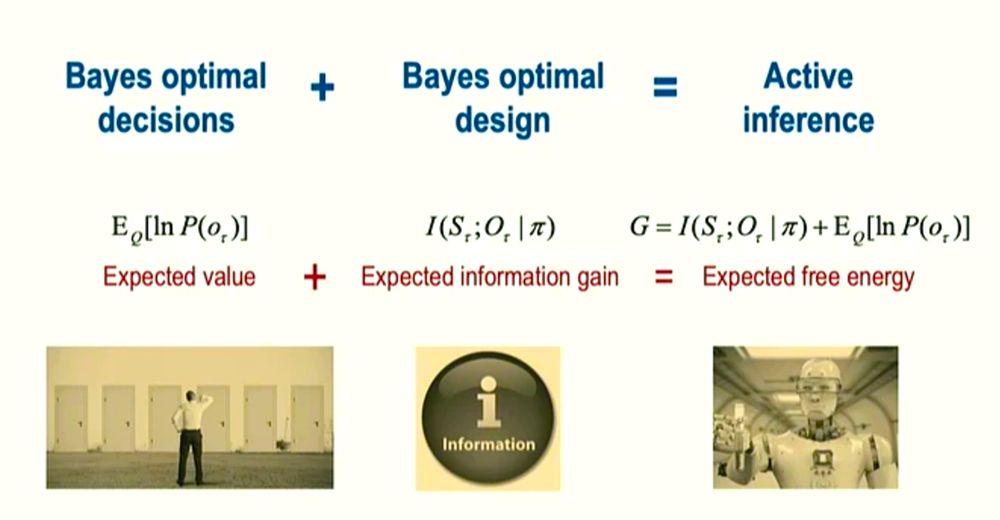
One of the most bizarre + complex talks at NeurIPS [1] was given by my fellow Yorkshireman, the inimitable Prof Karl Friston [2], explaining active inference to a room full of #AI people who are not really neuroscientists. This was interesting to me because... (1/n)


December 22, 2024 at 6:56 AM
One of the most bizarre + complex talks at NeurIPS [1] was given by my fellow Yorkshireman, the inimitable Prof Karl Friston [2], explaining active inference to a room full of #AI people who are not really neuroscientists. This was interesting to me because... (1/n)
Reposted by Clement POIRET

I ported Matt Might's bash scripts for detecting common issues in writing to a little web app (using Claude) and it's pretty fun to play with: https://simonwillison.net/2024/Dec/14/improve-your-writing/
3 shell scripts to improve your writing, or “My Ph.D. advisor rewrote himself in bash.”
Matt Might in 2010: > The hardest part of advising Ph.D. students is teaching them how to write. > > Fortunately, I've seen patterns emerge over the past couple years. …
simonwillison.net
December 14, 2024 at 6:56 PM
I ported Matt Might's bash scripts for detecting common issues in writing to a little web app (using Claude) and it's pretty fun to play with: https://simonwillison.net/2024/Dec/14/improve-your-writing/
Reposted by Clement POIRET

Our Open Source Developers Guide to the EU AI Act is now live! Check it out for an introduction to the AI Act and useful tools that may help prepare for compliance, with a focus on open source. Amazing to work with @frimelle.bsky.social and @yjernite.bsky.social on this!

Open Source Developers Guide to the EU AI Act
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
December 2, 2024 at 5:06 PM
Our Open Source Developers Guide to the EU AI Act is now live! Check it out for an introduction to the AI Act and useful tools that may help prepare for compliance, with a focus on open source. Amazing to work with @frimelle.bsky.social and @yjernite.bsky.social on this!
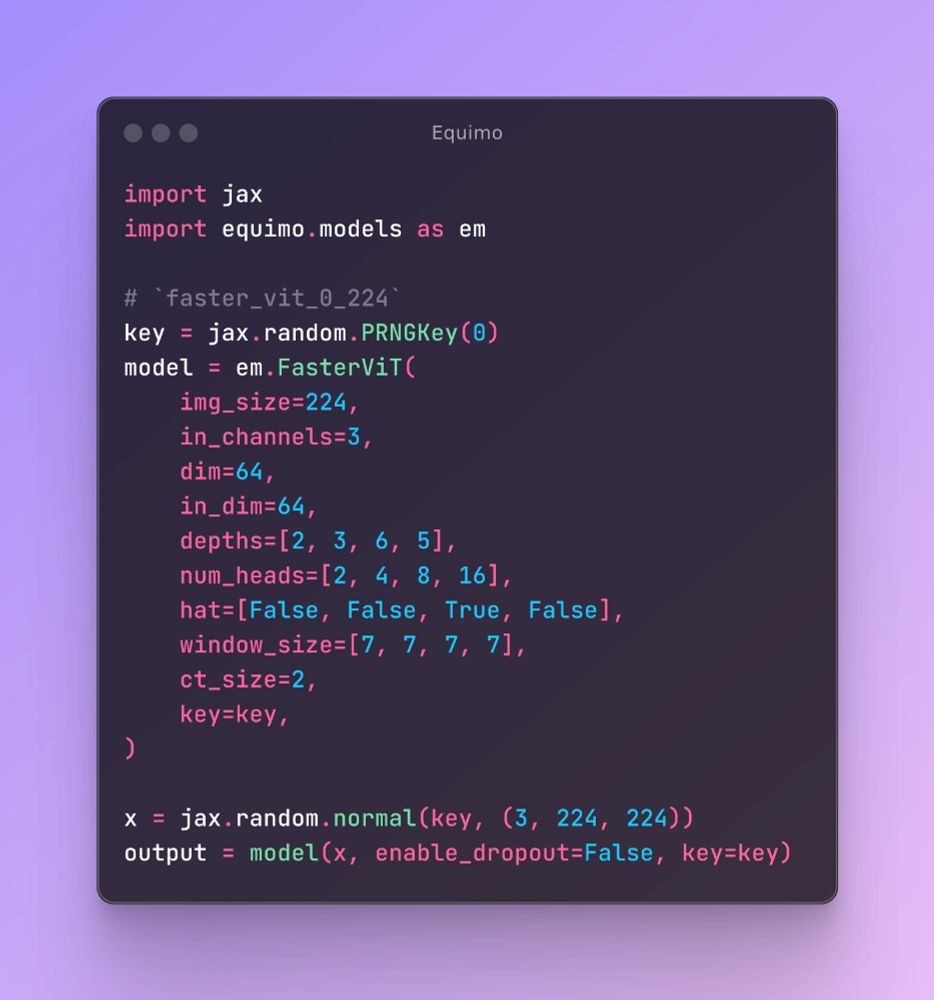
It ain't much, but it's honest work. I am open sourcing some model I am playing with.
Equimo is a JAX/Equinox library implementing modern vision architectures (2023-24). Features FasterViT, MLLA, VSSD, and more state-space/transformer models. Pure JAX implementation with modular design.
#MLSky
Equimo is a JAX/Equinox library implementing modern vision architectures (2023-24). Features FasterViT, MLLA, VSSD, and more state-space/transformer models. Pure JAX implementation with modular design.
#MLSky
November 26, 2024 at 10:49 AM
It ain't much, but it's honest work. I am open sourcing some model I am playing with.
Equimo is a JAX/Equinox library implementing modern vision architectures (2023-24). Features FasterViT, MLLA, VSSD, and more state-space/transformer models. Pure JAX implementation with modular design.
#MLSky
Equimo is a JAX/Equinox library implementing modern vision architectures (2023-24). Features FasterViT, MLLA, VSSD, and more state-space/transformer models. Pure JAX implementation with modular design.
#MLSky
Reposted by Clement POIRET

A timely paper exploring ways academics can pretrain larger models than they think, e.g. by trading time against GPU count.
Since the title is misleading, let me also say: US academics do not need $100k for this. They used 2,000 GPU hours in this paper; NSF will give you that. #MLSky
Since the title is misleading, let me also say: US academics do not need $100k for this. They used 2,000 GPU hours in this paper; NSF will give you that. #MLSky

$100K or 100 Days: Trade-offs when Pre-Training with Academic Resources
Pre-training is notoriously compute-intensive and academic researchers are notoriously under-resourced. It is, therefore, commonly assumed that academics can't pre-train models. In this paper, we seek...
arxiv.org
November 23, 2024 at 1:50 PM
A timely paper exploring ways academics can pretrain larger models than they think, e.g. by trading time against GPU count.
Since the title is misleading, let me also say: US academics do not need $100k for this. They used 2,000 GPU hours in this paper; NSF will give you that. #MLSky
Since the title is misleading, let me also say: US academics do not need $100k for this. They used 2,000 GPU hours in this paper; NSF will give you that. #MLSky
Reposted by Clement POIRET

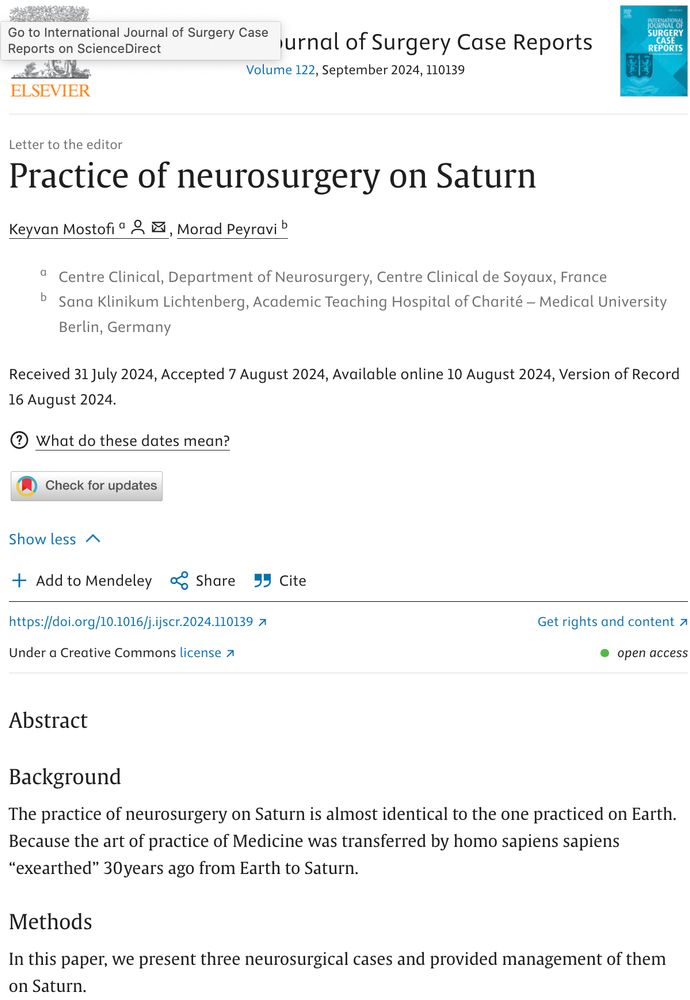
Wishing the Elsevier editors who desk-accepted this all the best for their next career moves.
doi.org/10.1016/j.ij...
doi.org/10.1016/j.ij...
November 22, 2024 at 2:49 PM
Wishing the Elsevier editors who desk-accepted this all the best for their next career moves.
doi.org/10.1016/j.ij...
doi.org/10.1016/j.ij...
NixOS is literally a game changer. Managing the state of your entire OS in Git feels like a superpower. The only downside was dev environments (e.g. python venv), which is solved by devenv.sh. I made a very simple template I use every day w/ optional CUDA support: github.com/clementpoire...
GitHub - clementpoiret/nix-python-devenv
Contribute to clementpoiret/nix-python-devenv development by creating an account on GitHub.
github.com
November 22, 2024 at 2:43 PM
NixOS is literally a game changer. Managing the state of your entire OS in Git feels like a superpower. The only downside was dev environments (e.g. python venv), which is solved by devenv.sh. I made a very simple template I use every day w/ optional CUDA support: github.com/clementpoire...