




Daniel
@indent4.bsky.social
🤖 ML Engineer → Developing Apps & Sharing ML/AI Insights 🚀 | Always Learning #MachineLearning #DataScience #AI
3️⃣ Orchestrators 🤖
The orchestrator is responsible for managing the pipeline execution.
This allows us to easily switch components (e.g., swap XGBoost for RandomForest).
The orchestrator is responsible for managing the pipeline execution.
This allows us to easily switch components (e.g., swap XGBoost for RandomForest).

February 21, 2025 at 5:31 PM
3️⃣ Orchestrators 🤖
The orchestrator is responsible for managing the pipeline execution.
This allows us to easily switch components (e.g., swap XGBoost for RandomForest).
The orchestrator is responsible for managing the pipeline execution.
This allows us to easily switch components (e.g., swap XGBoost for RandomForest).
2️⃣ Pipelines 🛤️
A TrainingPipeline ties together components into a single workflow.
Pipelines ensure a clear flow of data, from raw input to final evaluation.
A TrainingPipeline ties together components into a single workflow.
Pipelines ensure a clear flow of data, from raw input to final evaluation.

February 21, 2025 at 5:31 PM
2️⃣ Pipelines 🛤️
A TrainingPipeline ties together components into a single workflow.
Pipelines ensure a clear flow of data, from raw input to final evaluation.
A TrainingPipeline ties together components into a single workflow.
Pipelines ensure a clear flow of data, from raw input to final evaluation.
1️⃣ Components 📦
Each key function (data import, preprocessing, training, evaluation) is wrapped in its own class.
This makes it reusable, testable, and modular.
Example: A DataImporter class to load data!
Each key function (data import, preprocessing, training, evaluation) is wrapped in its own class.
This makes it reusable, testable, and modular.
Example: A DataImporter class to load data!

February 21, 2025 at 5:31 PM
1️⃣ Components 📦
Each key function (data import, preprocessing, training, evaluation) is wrapped in its own class.
This makes it reusable, testable, and modular.
Example: A DataImporter class to load data!
Each key function (data import, preprocessing, training, evaluation) is wrapped in its own class.
This makes it reusable, testable, and modular.
Example: A DataImporter class to load data!
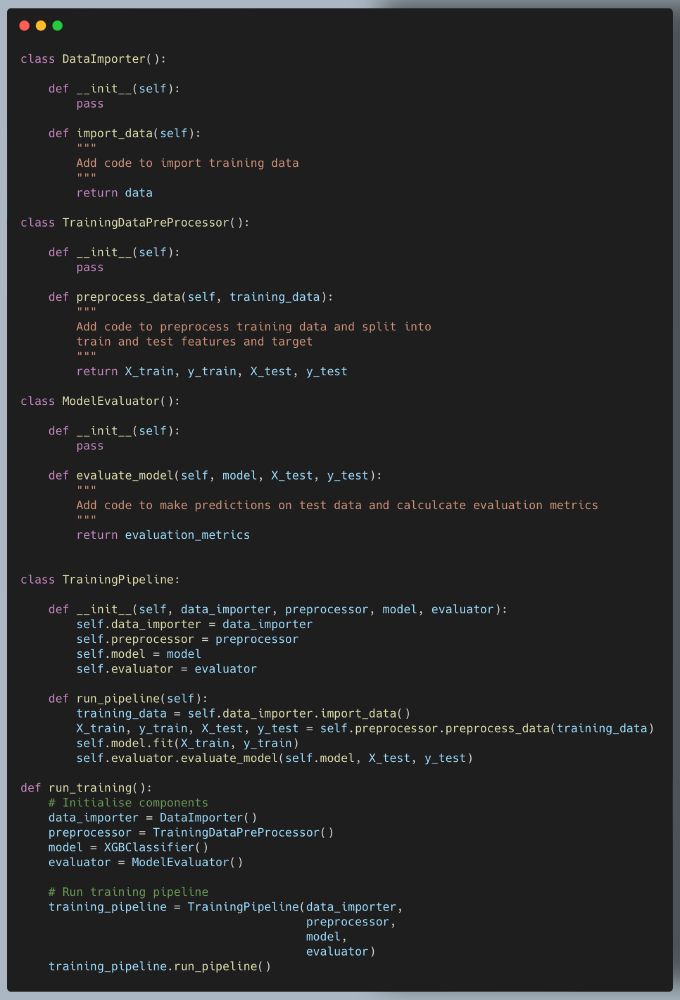
🚀 Want to write production-grade ML code that’s clean, modular & maintainable?
Here’s a simple CPO (components, pipelines, orchestrators) pattern example to structure your code.
Let's break this down with a training pipeline example👇
#MachineLearning #DataScience #MLOps
Here’s a simple CPO (components, pipelines, orchestrators) pattern example to structure your code.
Let's break this down with a training pipeline example👇
#MachineLearning #DataScience #MLOps
February 21, 2025 at 5:31 PM
🚀 Want to write production-grade ML code that’s clean, modular & maintainable?
Here’s a simple CPO (components, pipelines, orchestrators) pattern example to structure your code.
Let's break this down with a training pipeline example👇
#MachineLearning #DataScience #MLOps
Here’s a simple CPO (components, pipelines, orchestrators) pattern example to structure your code.
Let's break this down with a training pipeline example👇
#MachineLearning #DataScience #MLOps
🚀 Many newbies jump straight to feature eng and training ML models... then find models underperform.
Why? They skip Exploratory Data Analysis (EDA).
EDA is an important step for performance and explainability.
Here’s how to start👇
#DataAnalytics #100DaysOfML #MachineLearning
Why? They skip Exploratory Data Analysis (EDA).
EDA is an important step for performance and explainability.
Here’s how to start👇
#DataAnalytics #100DaysOfML #MachineLearning

February 19, 2025 at 3:32 PM
🚀 Many newbies jump straight to feature eng and training ML models... then find models underperform.
Why? They skip Exploratory Data Analysis (EDA).
EDA is an important step for performance and explainability.
Here’s how to start👇
#DataAnalytics #100DaysOfML #MachineLearning
Why? They skip Exploratory Data Analysis (EDA).
EDA is an important step for performance and explainability.
Here’s how to start👇
#DataAnalytics #100DaysOfML #MachineLearning