



Inception Labs
@inceptionlabs.bsky.social
Pioneering a new generation of LLMs.
Check out our blog post: www.inceptionlabs.ai/news

Inception Labs
We are leveraging diffusion technology to develop a new generation of LLMs. Our dLLMs are much faster and more efficient than traditional auto-regressive LLMs. And diffusion models are more accurate, ...
www.inceptionlabs.ai
February 26, 2025 at 8:51 PM
Check out our blog post: www.inceptionlabs.ai/news
Try Mercury Coder on our playground at chat.inceptionlabs.ai

February 26, 2025 at 8:51 PM
Try Mercury Coder on our playground at chat.inceptionlabs.ai
On Copilot Arena, developers consistently prefer Mercury’s generations. It ranks #1 on speed and #2 on quality. Mercury is the fastest code LLM on the market
February 26, 2025 at 8:51 PM
On Copilot Arena, developers consistently prefer Mercury’s generations. It ranks #1 on speed and #2 on quality. Mercury is the fastest code LLM on the market
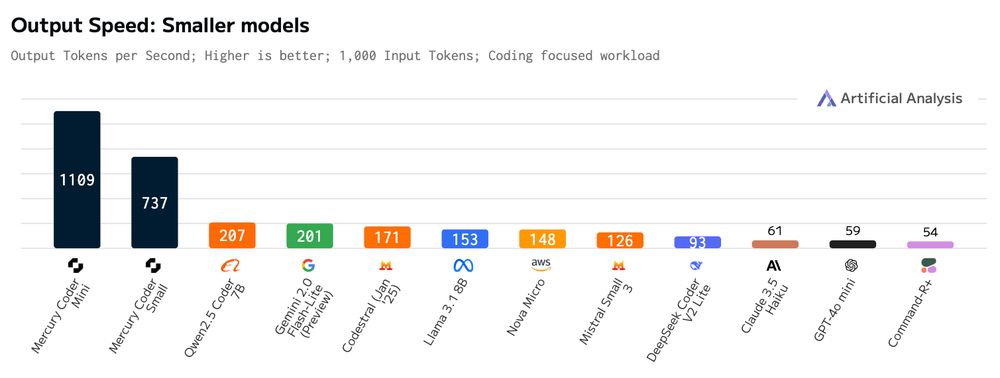
We achieve over 1000 tokens/second on NVIDIA H100s. Blazing fast generations without specialized chips!
February 26, 2025 at 8:51 PM
We achieve over 1000 tokens/second on NVIDIA H100s. Blazing fast generations without specialized chips!
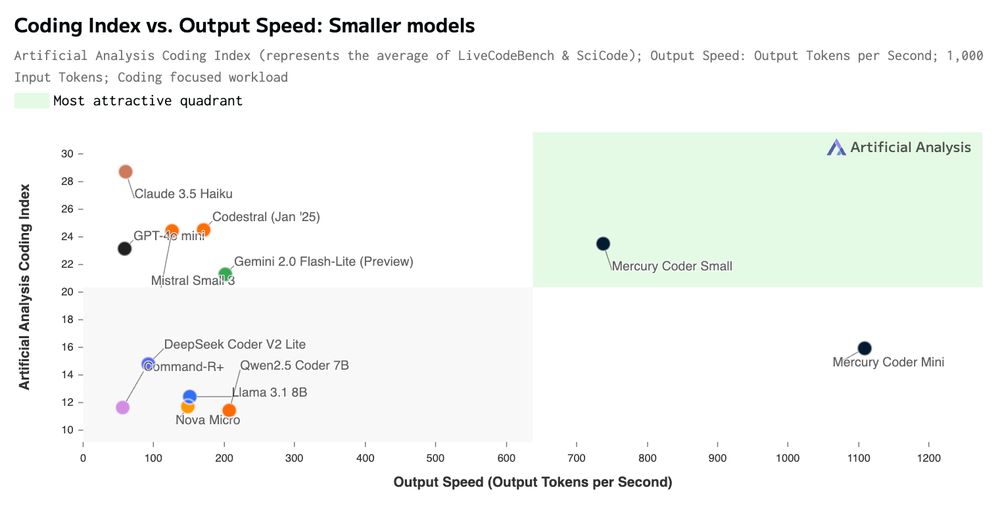
Mercury Coder diffusion large language models match the performance of frontier speed-optimized models like GPT-4o Mini and Claude 3.5 Haiku while running up to 10x faster.
February 26, 2025 at 8:51 PM
Mercury Coder diffusion large language models match the performance of frontier speed-optimized models like GPT-4o Mini and Claude 3.5 Haiku while running up to 10x faster.