


Jeremy Howard
@howard.fm
https://Answer.AI & https://fast.ai founding CEO; previous: hon professor @ UQ; leader of masks4all; founding CEO Enlitic; founding president Kaggle; various other stuff…
Post credits easter egg:
Hey did you wonder what if we trained a bigger model? Where would that take us?
Yeah, us too.
So we're gonna train a "huge" version of this model in 2025. We might need to change the y-axis on this graph…
Hey did you wonder what if we trained a bigger model? Where would that take us?
Yeah, us too.
So we're gonna train a "huge" version of this model in 2025. We might need to change the y-axis on this graph…

December 19, 2024 at 4:45 PM
Post credits easter egg:
Hey did you wonder what if we trained a bigger model? Where would that take us?
Yeah, us too.
So we're gonna train a "huge" version of this model in 2025. We might need to change the y-axis on this graph…
Hey did you wonder what if we trained a bigger model? Where would that take us?
Yeah, us too.
So we're gonna train a "huge" version of this model in 2025. We might need to change the y-axis on this graph…
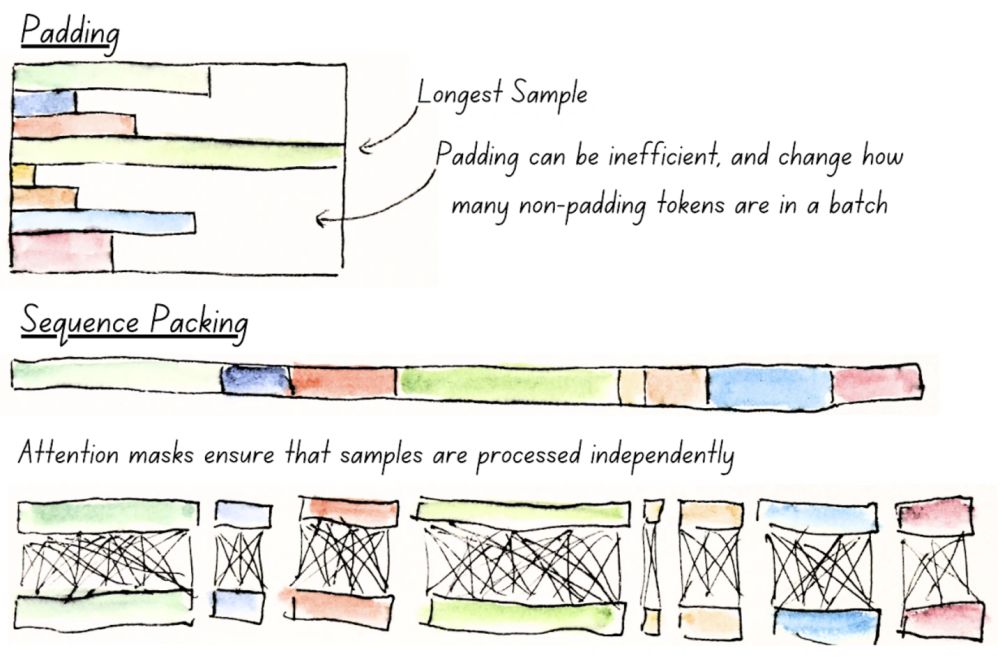
ModernBERT takes inspiration from the Transformer++ (from Mamba), including using RoPE & GeGLU, removing unnecessary bias terms, & adding an extra norm layer after embeddings.
Then, we added Alternating Attention (very impactful!), Sequence Packing, & Hardware-Aware Design
Then, we added Alternating Attention (very impactful!), Sequence Packing, & Hardware-Aware Design
December 19, 2024 at 4:45 PM
ModernBERT takes inspiration from the Transformer++ (from Mamba), including using RoPE & GeGLU, removing unnecessary bias terms, & adding an extra norm layer after embeddings.
Then, we added Alternating Attention (very impactful!), Sequence Packing, & Hardware-Aware Design
Then, we added Alternating Attention (very impactful!), Sequence Packing, & Hardware-Aware Design
And ModernBERT is *efficient*.
It’s twice as fast as DeBERTa; up to 4x faster in the more common situation where inputs are mixed length. Long context inference is ~3x faster than other high-quality models.
And it uses less than 1/5th of Deberta’s memory!
It’s twice as fast as DeBERTa; up to 4x faster in the more common situation where inputs are mixed length. Long context inference is ~3x faster than other high-quality models.
And it uses less than 1/5th of Deberta’s memory!

December 19, 2024 at 4:45 PM
And ModernBERT is *efficient*.
It’s twice as fast as DeBERTa; up to 4x faster in the more common situation where inputs are mixed length. Long context inference is ~3x faster than other high-quality models.
And it uses less than 1/5th of Deberta’s memory!
It’s twice as fast as DeBERTa; up to 4x faster in the more common situation where inputs are mixed length. Long context inference is ~3x faster than other high-quality models.
And it uses less than 1/5th of Deberta’s memory!
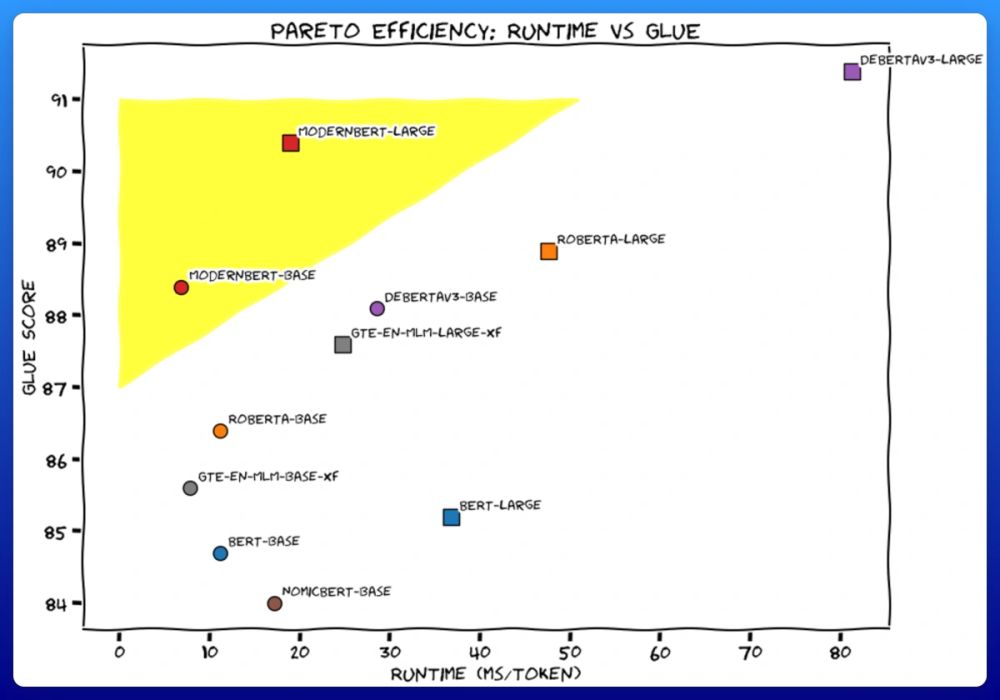
As you can see, ModernBERT is *accurate*: it's the only model which is a top scorer across every category, which makes it the one model you can use for all your encoder-based tasks.

December 19, 2024 at 4:45 PM
As you can see, ModernBERT is *accurate*: it's the only model which is a top scorer across every category, which makes it the one model you can use for all your encoder-based tasks.
6 years after BERT, we have a replacement: ModernBERT!
@answerdotai, @LightOnIO (et al) took dozens of advances from recent years of work on LLMs, and applied them to a BERT-style model, including updates to the architecture and the training process, eg alternating attention.
@answerdotai, @LightOnIO (et al) took dozens of advances from recent years of work on LLMs, and applied them to a BERT-style model, including updates to the architecture and the training process, eg alternating attention.

December 19, 2024 at 4:45 PM
6 years after BERT, we have a replacement: ModernBERT!
@answerdotai, @LightOnIO (et al) took dozens of advances from recent years of work on LLMs, and applied them to a BERT-style model, including updates to the architecture and the training process, eg alternating attention.
@answerdotai, @LightOnIO (et al) took dozens of advances from recent years of work on LLMs, and applied them to a BERT-style model, including updates to the architecture and the training process, eg alternating attention.
Seven months ago, @bclavie.bsky.social kicked things off, and soon Benjamin Warner & @nohtow.bsky.social joined him as project co-leads. I don't think anyone quite knew what we were getting in to…
It turns out that training a new, SoTA model from scratch is actually pretty hard. Who knew? 🤷
It turns out that training a new, SoTA model from scratch is actually pretty hard. Who knew? 🤷

December 19, 2024 at 4:45 PM
Seven months ago, @bclavie.bsky.social kicked things off, and soon Benjamin Warner & @nohtow.bsky.social joined him as project co-leads. I don't think anyone quite knew what we were getting in to…
It turns out that training a new, SoTA model from scratch is actually pretty hard. Who knew? 🤷
It turns out that training a new, SoTA model from scratch is actually pretty hard. Who knew? 🤷
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
December 19, 2024 at 4:45 PM
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
👀something's coming...
December 18, 2024 at 11:42 PM
👀something's coming...
...besides which that copyright maximalists are *directly* advocating for increased power and money for big tech and media companies. MPAA having a field day here.
(I noticed a lot of the "anti-AI" folks work for those companies, or have them as clients. Funny that.)
(I noticed a lot of the "anti-AI" folks work for those companies, or have them as clients. Funny that.)

December 11, 2024 at 10:19 AM
...besides which that copyright maximalists are *directly* advocating for increased power and money for big tech and media companies. MPAA having a field day here.
(I noticed a lot of the "anti-AI" folks work for those companies, or have them as clients. Funny that.)
(I noticed a lot of the "anti-AI" folks work for those companies, or have them as clients. Funny that.)

I used a few starter packs to help connect with my communities, but after a couple of weeks I noticed nearly all the posts I'm interested in are from folks that follow me back.
So I created an nb to unfollow non-mutual follows. Code in alt text, or here:
colab.research.google.com/drive/1V7QjZ...
So I created an nb to unfollow non-mutual follows. Code in alt text, or here:
colab.research.google.com/drive/1V7QjZ...
![# Remove bsky non-mutual follows
from fastcore.utils import *
from fastcore.xtras import *
from atproto import Client
from fastprogress.fastprogress import master_bar, progress_bar
cli = Client()
pv = cli.login('youruser', 'yourpass')
did = pv.did
pv.posts_count,pv.followers_count,pv.follows_count
def at_paged(did, meth):
"Return all pages of results from some method"
resp = None
while True:
resp = meth(did, cursor=resp.cursor if resp else None)
yield resp
if not resp.cursor: return
posts = L(at_paged(did, cli.get_author_feed)).attrgot('feed').concat()
posts[-2].post.record
fws = L(at_paged(did, cli.get_follows))
frs = L(at_paged(did, cli.get_followers))
following = fws.attrgot('follows').concat()
followers = frs.attrgot('followers').concat()
len(following),len(followers)
to_unfollow = set(following.attrgot('did')) - set(followers.attrgot('did'))
len(to_unfollow)
followd = {o.did:o.viewer.following for o in following}
for fdid in progress_bar(to_unfollow):
try: cli.unfollow(followd[fdid])
except Exception as e: print(f"Could not unfollow {fdid}: {e}")](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:ihze7dasblwewgunyesfbm23/bafkreia2oxxpu274ex3axg22mhfkhj5eusbpnusllc7a5g3jcojtyxqd4q@jpeg)
December 2, 2024 at 9:24 PM
I used a few starter packs to help connect with my communities, but after a couple of weeks I noticed nearly all the posts I'm interested in are from folks that follow me back.
So I created an nb to unfollow non-mutual follows. Code in alt text, or here:
colab.research.google.com/drive/1V7QjZ...
So I created an nb to unfollow non-mutual follows. Code in alt text, or here:
colab.research.google.com/drive/1V7QjZ...
Gab (remember them?) tried to push their narrative with their AI system prompt. I dunno if they had insta-ban words or sentences though?

November 30, 2024 at 6:05 PM
Gab (remember them?) tried to push their narrative with their AI system prompt. I dunno if they had insta-ban words or sentences though?
Twitter bans the word "cisgender" (or at least used to -- dunno if they still do)

November 30, 2024 at 5:59 PM
Twitter bans the word "cisgender" (or at least used to -- dunno if they still do)
I don't want to get insta-banned myself, but I also know everyone is gonna ask me what the sentence is, so I'm going to paste it as an image here, without alt text.
(I'm not saying this sentence is true, I'm just saying it's the sentence that got hardmaru banned for testing it.)
(I'm not saying this sentence is true, I'm just saying it's the sentence that got hardmaru banned for testing it.)

November 30, 2024 at 5:56 PM
I don't want to get insta-banned myself, but I also know everyone is gonna ask me what the sentence is, so I'm going to paste it as an image here, without alt text.
(I'm not saying this sentence is true, I'm just saying it's the sentence that got hardmaru banned for testing it.)
(I'm not saying this sentence is true, I'm just saying it's the sentence that got hardmaru banned for testing it.)


Maybe Apple Intelligence shouldn’t mark scam emails as “Priority” with a summary saying it’s for security purposes?

November 28, 2024 at 1:19 AM
Maybe Apple Intelligence shouldn’t mark scam emails as “Priority” with a summary saying it’s for security purposes?
I've never, personally, had any direct utility from traditional academic peer review for my scientific work.
I've never used that peer review as any kind of signal or credential in judging a paper or deciding whether to read it.
Nearly all the papers I read are preprints.
I've never used that peer review as any kind of signal or credential in judging a paper or deciding whether to read it.
Nearly all the papers I read are preprints.

November 25, 2024 at 2:01 AM
I've never, personally, had any direct utility from traditional academic peer review for my scientific work.
I've never used that peer review as any kind of signal or credential in judging a paper or deciding whether to read it.
Nearly all the papers I read are preprints.
I've never used that peer review as any kind of signal or credential in judging a paper or deciding whether to read it.
Nearly all the papers I read are preprints.
I suspect I'm being silly and am missing something obvious, but I can't see a way to view mentions (i.e replies and quotes), which makes it hard to respond to people. Instead my notifications are full stuff I don't need about who is following me etc.
Is there something like Twitter's 'mentions'?
Is there something like Twitter's 'mentions'?
November 19, 2024 at 11:19 PM
I suspect I'm being silly and am missing something obvious, but I can't see a way to view mentions (i.e replies and quotes), which makes it hard to respond to people. Instead my notifications are full stuff I don't need about who is following me etc.
Is there something like Twitter's 'mentions'?
Is there something like Twitter's 'mentions'?