




Michael Horrell
@horrellmt.bsky.social
PhD in Statistics
Building https://github.com/mthorrell/gbnet
Building https://github.com/mthorrell/gbnet
Side note: if you extend this case to use different numbers of observations and different variances, you get actually a pretty nice looking matplotlib plot

June 16, 2025 at 2:54 AM
Side note: if you extend this case to use different numbers of observations and different variances, you get actually a pretty nice looking matplotlib plot
Bayesian modeling provides a nice test bed for this
Eg: When finding a mean, how much to weight the prior (call it Model 1) vs the sample average (Model 2)? Some bayesian math gives the optimal answer given # of obs.
A bit of GBNet & PyTorch empirically derives the same answer almost exactly.
Eg: When finding a mean, how much to weight the prior (call it Model 1) vs the sample average (Model 2)? Some bayesian math gives the optimal answer given # of obs.
A bit of GBNet & PyTorch empirically derives the same answer almost exactly.


June 16, 2025 at 2:54 AM
Bayesian modeling provides a nice test bed for this
Eg: When finding a mean, how much to weight the prior (call it Model 1) vs the sample average (Model 2)? Some bayesian math gives the optimal answer given # of obs.
A bit of GBNet & PyTorch empirically derives the same answer almost exactly.
Eg: When finding a mean, how much to weight the prior (call it Model 1) vs the sample average (Model 2)? Some bayesian math gives the optimal answer given # of obs.
A bit of GBNet & PyTorch empirically derives the same answer almost exactly.
Next application for GBNet is basically a data-aware model averaging or a mixture of experts type of analysis.
Situation: you have several models with predictions
Q: Is there a data-driven way to combine them? And, for convenience, can I use XGBoost to do find the right averaging coefficients?
Situation: you have several models with predictions
Q: Is there a data-driven way to combine them? And, for convenience, can I use XGBoost to do find the right averaging coefficients?

June 14, 2025 at 5:12 PM
Next application for GBNet is basically a data-aware model averaging or a mixture of experts type of analysis.
Situation: you have several models with predictions
Q: Is there a data-driven way to combine them? And, for convenience, can I use XGBoost to do find the right averaging coefficients?
Situation: you have several models with predictions
Q: Is there a data-driven way to combine them? And, for convenience, can I use XGBoost to do find the right averaging coefficients?
GBNet calls XGBoost/LightGBM under the hood. This means you can bring native XGB/LGBM features to PyTorch with little effort.
Categorical splitting is one interesting feature to play with using GBNet. To scratch the surface, I fit a basic Word2Vec model using XGBoost for categorical splitting.
Categorical splitting is one interesting feature to play with using GBNet. To scratch the surface, I fit a basic Word2Vec model using XGBoost for categorical splitting.


May 26, 2025 at 2:48 PM
GBNet calls XGBoost/LightGBM under the hood. This means you can bring native XGB/LGBM features to PyTorch with little effort.
Categorical splitting is one interesting feature to play with using GBNet. To scratch the surface, I fit a basic Word2Vec model using XGBoost for categorical splitting.
Categorical splitting is one interesting feature to play with using GBNet. To scratch the surface, I fit a basic Word2Vec model using XGBoost for categorical splitting.
Just released GBNet V0.5.0
Beyond some usability improvements, the uncertainty estimation for the Forecasting module got merged in. Now GBNet forecasting is:
✅ Faster
✅ More accurate than Prophet
✅ Provides uncertainty estimates
✅ Supports changepoints
Beyond some usability improvements, the uncertainty estimation for the Forecasting module got merged in. Now GBNet forecasting is:
✅ Faster
✅ More accurate than Prophet
✅ Provides uncertainty estimates
✅ Supports changepoints

May 22, 2025 at 1:29 AM
Just released GBNet V0.5.0
Beyond some usability improvements, the uncertainty estimation for the Forecasting module got merged in. Now GBNet forecasting is:
✅ Faster
✅ More accurate than Prophet
✅ Provides uncertainty estimates
✅ Supports changepoints
Beyond some usability improvements, the uncertainty estimation for the Forecasting module got merged in. Now GBNet forecasting is:
✅ Faster
✅ More accurate than Prophet
✅ Provides uncertainty estimates
✅ Supports changepoints
One benefit to speeding up model fitting code 5X is that you can use that saved time for other things.
Adding conf intervals for gbnet forecasting module, I can do train/validation holdout for this and still be 3-4X faster.
Trying to get 80% test coverage:
New method: 76% avg
Prophet: 55% avg
Adding conf intervals for gbnet forecasting module, I can do train/validation holdout for this and still be 3-4X faster.
Trying to get 80% test coverage:
New method: 76% avg
Prophet: 55% avg

April 28, 2025 at 12:27 AM
One benefit to speeding up model fitting code 5X is that you can use that saved time for other things.
Adding conf intervals for gbnet forecasting module, I can do train/validation holdout for this and still be 3-4X faster.
Trying to get 80% test coverage:
New method: 76% avg
Prophet: 55% avg
Adding conf intervals for gbnet forecasting module, I can do train/validation holdout for this and still be 3-4X faster.
Trying to get 80% test coverage:
New method: 76% avg
Prophet: 55% avg
So it's continually a nice surprise that stuff like this kinda just works.
I asked GBNet for a second prediction output. I slapped on torch.nn.GaussianNLLLoss and out comes a variance estimate that is well calibrated.
I asked GBNet for a second prediction output. I slapped on torch.nn.GaussianNLLLoss and out comes a variance estimate that is well calibrated.

April 13, 2025 at 12:30 AM
So it's continually a nice surprise that stuff like this kinda just works.
I asked GBNet for a second prediction output. I slapped on torch.nn.GaussianNLLLoss and out comes a variance estimate that is well calibrated.
I asked GBNet for a second prediction output. I slapped on torch.nn.GaussianNLLLoss and out comes a variance estimate that is well calibrated.
Just merged changepoints into the forecasting sub-module of GBNet and released V0.4.0.
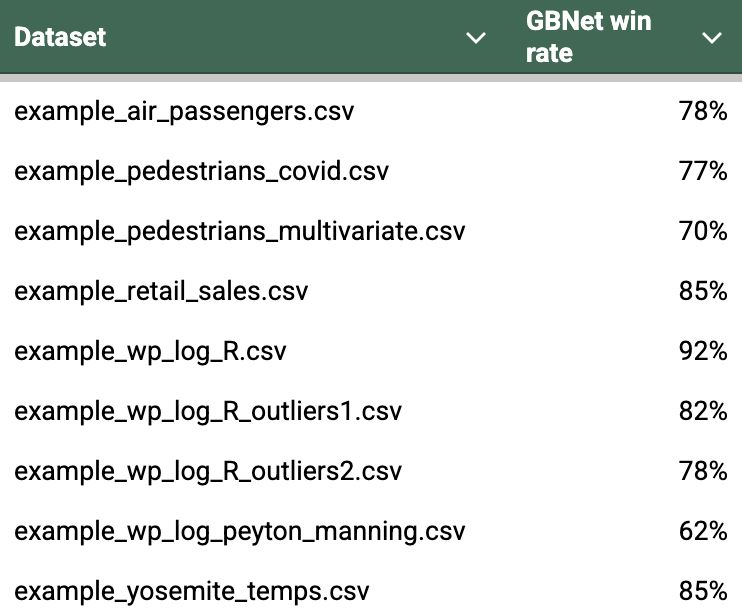
Default forecast performance improved by 20% and achieved a 5X speedup. Using the random training, random horizon benchmark, now 9 of 9 example datasets have better performance with GBNet compared to Prophet.
Default forecast performance improved by 20% and achieved a 5X speedup. Using the random training, random horizon benchmark, now 9 of 9 example datasets have better performance with GBNet compared to Prophet.
April 12, 2025 at 8:11 PM
Just merged changepoints into the forecasting sub-module of GBNet and released V0.4.0.
Default forecast performance improved by 20% and achieved a 5X speedup. Using the random training, random horizon benchmark, now 9 of 9 example datasets have better performance with GBNet compared to Prophet.
Default forecast performance improved by 20% and achieved a 5X speedup. Using the random training, random horizon benchmark, now 9 of 9 example datasets have better performance with GBNet compared to Prophet.
Still working on changepoints. Several methods work but don't improve benchmarks. When your model is Trend + XGBoost, XGB can just handle a lot of non-stationarity.
Most promising method so far (see plot) asks GBDT to fit and find the changepoints. Another cool application of GBNet (see equation).
Most promising method so far (see plot) asks GBDT to fit and find the changepoints. Another cool application of GBNet (see equation).


March 30, 2025 at 10:35 PM
Still working on changepoints. Several methods work but don't improve benchmarks. When your model is Trend + XGBoost, XGB can just handle a lot of non-stationarity.
Most promising method so far (see plot) asks GBDT to fit and find the changepoints. Another cool application of GBNet (see equation).
Most promising method so far (see plot) asks GBDT to fit and find the changepoints. Another cool application of GBNet (see equation).
Claude gets half credit. It added changepoints for the PyTorch trend option but skipped it for the GBLinear option.
Unfortunately it's back to the drawing board. PyTorch changepoints fit too slowly and GBLinear, I now realize, can't actually turn them off. It does work though!
Unfortunately it's back to the drawing board. PyTorch changepoints fit too slowly and GBLinear, I now realize, can't actually turn them off. It does work though!

March 19, 2025 at 11:33 PM
Claude gets half credit. It added changepoints for the PyTorch trend option but skipped it for the GBLinear option.
Unfortunately it's back to the drawing board. PyTorch changepoints fit too slowly and GBLinear, I now realize, can't actually turn them off. It does work though!
Unfortunately it's back to the drawing board. PyTorch changepoints fit too slowly and GBLinear, I now realize, can't actually turn them off. It does work though!
Case in point: GBNet Forecast fits XB + GBDT(X). It has a linear component.
I replaced PyTorch Linear with GBLinear (removing batchnorm) and...
1. improved accuracy (see table)
2. sped up fitting 10X by using fewer training rounds
3. improved worst-case performance (see plot)
I replaced PyTorch Linear with GBLinear (removing batchnorm) and...
1. improved accuracy (see table)
2. sped up fitting 10X by using fewer training rounds
3. improved worst-case performance (see plot)


March 5, 2025 at 3:34 AM
Case in point: GBNet Forecast fits XB + GBDT(X). It has a linear component.
I replaced PyTorch Linear with GBLinear (removing batchnorm) and...
1. improved accuracy (see table)
2. sped up fitting 10X by using fewer training rounds
3. improved worst-case performance (see plot)
I replaced PyTorch Linear with GBLinear (removing batchnorm) and...
1. improved accuracy (see table)
2. sped up fitting 10X by using fewer training rounds
3. improved worst-case performance (see plot)
GBLinear solves this without scaling. Also, it generally can find sharper minima, often resulting in better training loss which of course can be associated with better test loss.
Training curves on the left (note the log scales). A sample from the dataset on the right... far from a crazy dataset.
Training curves on the left (note the log scales). A sample from the dataset on the right... far from a crazy dataset.


March 2, 2025 at 9:34 PM
GBLinear solves this without scaling. Also, it generally can find sharper minima, often resulting in better training loss which of course can be associated with better test loss.
Training curves on the left (note the log scales). A sample from the dataset on the right... far from a crazy dataset.
Training curves on the left (note the log scales). A sample from the dataset on the right... far from a crazy dataset.
Cool trick I hadn't seen before today -- You can solve Ridge Regression with some simple concatenations to the X and Y inputs.
Turned out great for my use-case because I was using a pure least-squares solver but I wanted Ridge Regression.
Turned out great for my use-case because I was using a pure least-squares solver but I wanted Ridge Regression.

February 21, 2025 at 3:48 AM
Cool trick I hadn't seen before today -- You can solve Ridge Regression with some simple concatenations to the X and Y inputs.
Turned out great for my use-case because I was using a pure least-squares solver but I wanted Ridge Regression.
Turned out great for my use-case because I was using a pure least-squares solver but I wanted Ridge Regression.
Case in point, it seems to work! Nice job! I copied and pasted their loss function, put LightGBM on it via GBNet and off it went.

February 7, 2025 at 2:09 AM
Case in point, it seems to work! Nice job! I copied and pasted their loss function, put LightGBM on it via GBNet and off it went.
Due to a user request, I added Ordinal Regression into GBNet. You can now use XGBoost/LightGBM for Ord. Regression.
Ord. loss is complex and has viable alternatives. But, on a set of 19 Ordinal Datasets, Ord. Reg. using LightGBM came out on top. Maybe worth keeping in mind if your data is Ordinal.
Ord. loss is complex and has viable alternatives. But, on a set of 19 Ordinal Datasets, Ord. Reg. using LightGBM came out on top. Maybe worth keeping in mind if your data is Ordinal.

January 26, 2025 at 11:10 PM
Due to a user request, I added Ordinal Regression into GBNet. You can now use XGBoost/LightGBM for Ord. Regression.
Ord. loss is complex and has viable alternatives. But, on a set of 19 Ordinal Datasets, Ord. Reg. using LightGBM came out on top. Maybe worth keeping in mind if your data is Ordinal.
Ord. loss is complex and has viable alternatives. But, on a set of 19 Ordinal Datasets, Ord. Reg. using LightGBM came out on top. Maybe worth keeping in mind if your data is Ordinal.
I used GBNet to fit different 2D embeddings of MNIST. One is trained to classify via GBNet(X) * Beta. The other is trained by contrastive learning via || GBNet(X) - GBNet(Y) ||.
Plots are below. Which is the contrastive embedding? Which is the classification embedding?
Plots are below. Which is the contrastive embedding? Which is the classification embedding?


December 18, 2024 at 12:42 AM
I used GBNet to fit different 2D embeddings of MNIST. One is trained to classify via GBNet(X) * Beta. The other is trained by contrastive learning via || GBNet(X) - GBNet(Y) ||.
Plots are below. Which is the contrastive embedding? Which is the classification embedding?
Plots are below. Which is the contrastive embedding? Which is the classification embedding?
POV: me flying from 80 degree Miami to -25 wind chill Chicago earlier this week

December 14, 2024 at 10:29 PM
POV: me flying from 80 degree Miami to -25 wind chill Chicago earlier this week
Maybe the weirdest training loss you'll see today:

December 4, 2024 at 1:20 AM
Maybe the weirdest training loss you'll see today: