



Hope Schroeder
@hopeschroeder.bsky.social
Studying NLP, CSS, and Human-AI interaction. PhD student @MIT. Previously at Microsoft FATE + CSS, Oxford Internet Institute, Stanford Symbolic Systems
hopeschroeder.com
hopeschroeder.com
Thanks for sharing- not just our paper but also learned a lot from this list! :)
July 24, 2025 at 9:06 AM
Thanks for sharing- not just our paper but also learned a lot from this list! :)
Awesome work and great presentation! Congrats!! ⚡️
July 23, 2025 at 1:42 PM
Awesome work and great presentation! Congrats!! ⚡️
Implications vary by task and domain. Researchers should clearly define their annotation constructs before reviewing LLM annotations. We are subject to anchoring bias that can affect our evaluations, or even our research findings!
Read more: arxiv.org/abs/2507.15821
Read more: arxiv.org/abs/2507.15821

July 22, 2025 at 8:35 AM
Implications vary by task and domain. Researchers should clearly define their annotation constructs before reviewing LLM annotations. We are subject to anchoring bias that can affect our evaluations, or even our research findings!
Read more: arxiv.org/abs/2507.15821
Read more: arxiv.org/abs/2507.15821
Using LLM-influenced labels, even when a crowd of humans reviews them and is aggregated into a set of crowd labels, can lead to 1) different findings when used in data analysis and 2) different results when used as a basis of evaluating LLM performance on the task.
July 22, 2025 at 8:34 AM
Using LLM-influenced labels, even when a crowd of humans reviews them and is aggregated into a set of crowd labels, can lead to 1) different findings when used in data analysis and 2) different results when used as a basis of evaluating LLM performance on the task.
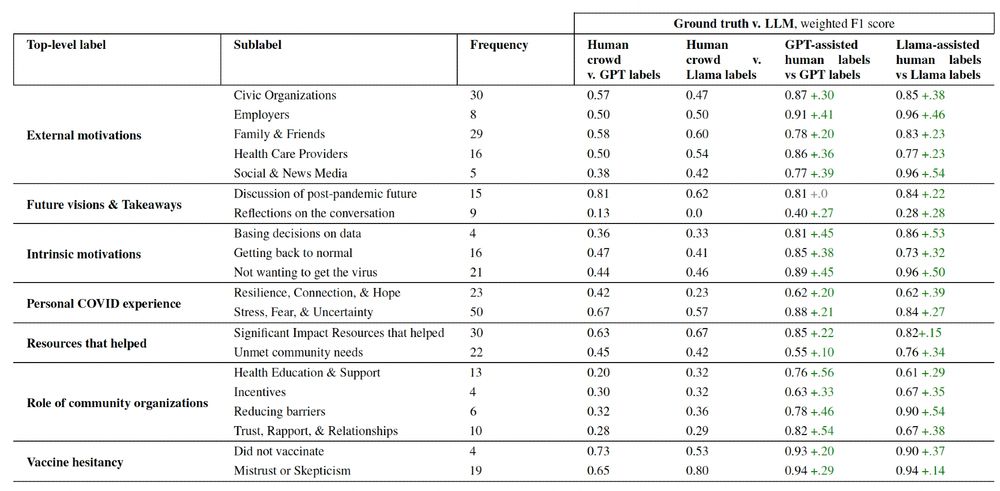
What happens if we use LLM-influenced labels as ground truth when evaluating LLM performance on these tasks? We can seriously overestimate LLM performance on these tasks. F1 scores for some tasks were +.5 higher when evaluated using LLM-influenced labels as ground truth!
July 22, 2025 at 8:34 AM
What happens if we use LLM-influenced labels as ground truth when evaluating LLM performance on these tasks? We can seriously overestimate LLM performance on these tasks. F1 scores for some tasks were +.5 higher when evaluated using LLM-influenced labels as ground truth!
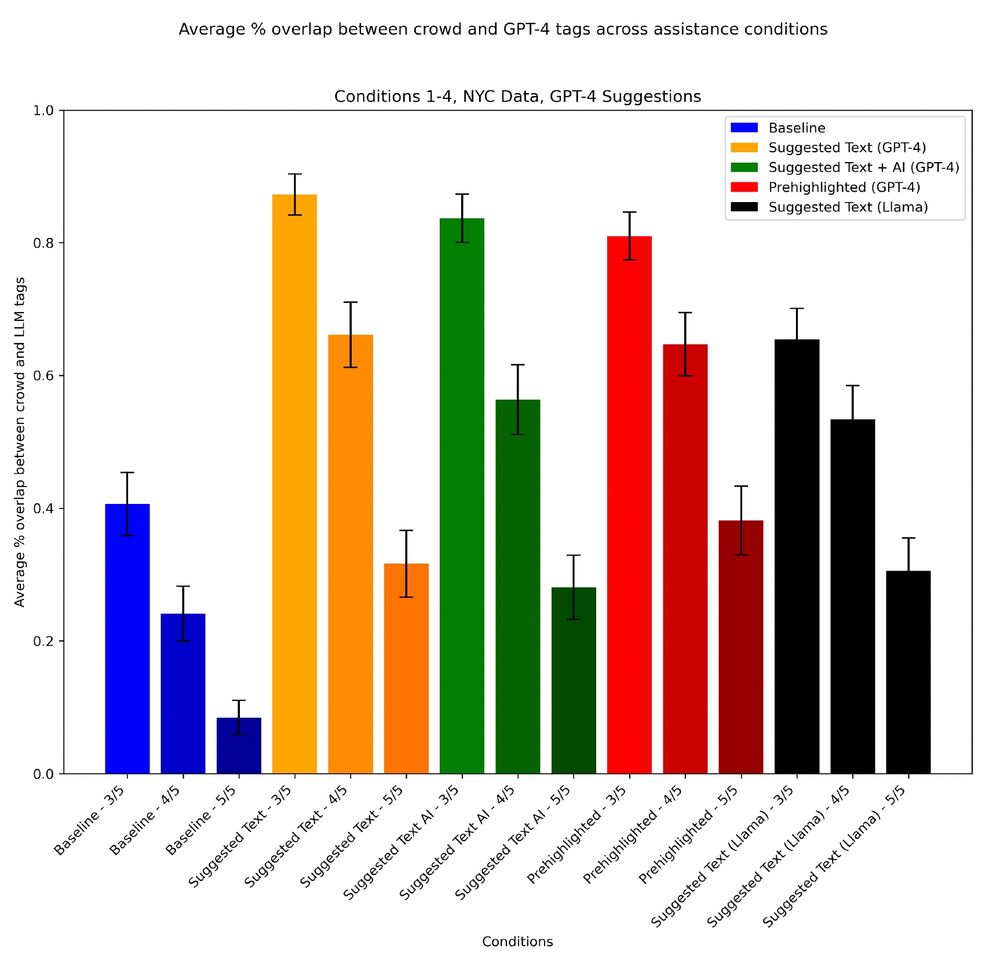
However… annotators STRONGLY took LLM suggestions: just 40% of human crowd labels overlap with LLM baselines, but overlap jumps to over 80% when LLM suggestions are given (varied crowd thresholds and conditions shown in graph). Beware: Humans are subject to anchoring bias!
July 22, 2025 at 8:34 AM
However… annotators STRONGLY took LLM suggestions: just 40% of human crowd labels overlap with LLM baselines, but overlap jumps to over 80% when LLM suggestions are given (varied crowd thresholds and conditions shown in graph). Beware: Humans are subject to anchoring bias!
Some findings: ⚠️ reviewing LLM suggestions did not make annotators go faster, and often slowed them down! OTOH, having LLM assistance made annotators ❗more self-confident❗in their task and content understanding at no identified cost to their tested task understanding.
July 22, 2025 at 8:33 AM
Some findings: ⚠️ reviewing LLM suggestions did not make annotators go faster, and often slowed them down! OTOH, having LLM assistance made annotators ❗more self-confident❗in their task and content understanding at no identified cost to their tested task understanding.
We conducted experiments where over 410 unique annotators generated with over 7,000 annotations across three LLM assistance conditions of varying strengths against a control, using two different models, and two different complex, subjective annotation tasks.
July 22, 2025 at 8:33 AM
We conducted experiments where over 410 unique annotators generated with over 7,000 annotations across three LLM assistance conditions of varying strengths against a control, using two different models, and two different complex, subjective annotation tasks.
LLMs can be fast and promising annotators, so letting human annotators "review" first-pass LLM annotations in interpretive tasks is tempting. How does this impact productivity, annotators, evaluating LLM performance on subjective tasks and downstream data analysis?
July 22, 2025 at 8:32 AM
LLMs can be fast and promising annotators, so letting human annotators "review" first-pass LLM annotations in interpretive tasks is tempting. How does this impact productivity, annotators, evaluating LLM performance on subjective tasks and downstream data analysis?
Thanks for attending and for your comments!!
June 25, 2025 at 8:28 AM
Thanks for attending and for your comments!!
Come hear much more at our paper talk tomorrow (Wednesday, 6/25) in Meta Research and Critiques, 9:12 am at New Stage A! Read the paper here: dl.acm.org/doi/10.1145/...

Disclosure without Engagement: An Empirical Review of Positionality Statements at FAccT | Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency
You will be notified whenever a record that you have chosen has been cited.
dl.acm.org
June 24, 2025 at 2:51 PM
Come hear much more at our paper talk tomorrow (Wednesday, 6/25) in Meta Research and Critiques, 9:12 am at New Stage A! Read the paper here: dl.acm.org/doi/10.1145/...
*What should FAccT do?* We discuss a need for the conference to clarify its policies next year, engage scholars from different disciplines when considering policy on this delicate subject, and engage authors in reflexive practice upstream of paper-writing, potentially through CRAFT.
June 24, 2025 at 2:50 PM
*What should FAccT do?* We discuss a need for the conference to clarify its policies next year, engage scholars from different disciplines when considering policy on this delicate subject, and engage authors in reflexive practice upstream of paper-writing, potentially through CRAFT.
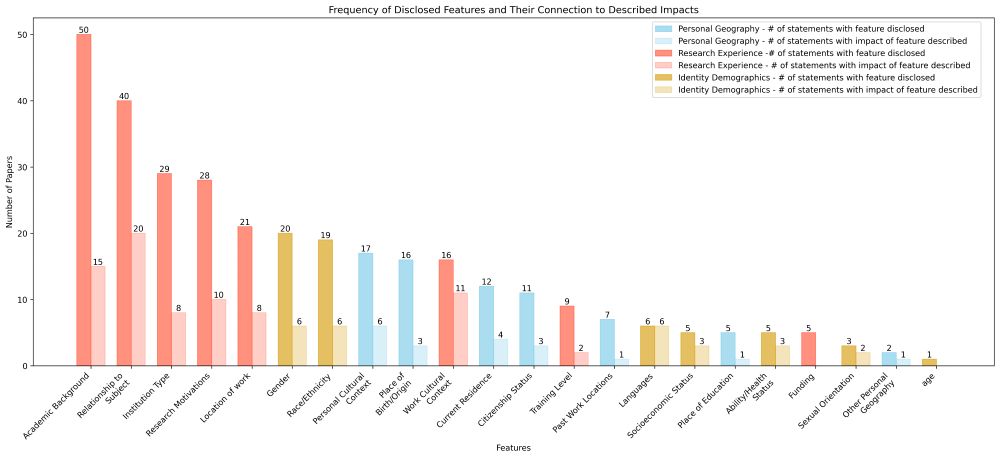
*Are disclosed features connected to described impacts?* Disclosed features are much less commonly described in terms of impacts the feature had on the research, which may leave a gap for readers to jump to conclusions about how the disclosed feature impacted the work.
June 24, 2025 at 2:50 PM
*Are disclosed features connected to described impacts?* Disclosed features are much less commonly described in terms of impacts the feature had on the research, which may leave a gap for readers to jump to conclusions about how the disclosed feature impacted the work.
*What do authors disclose in positionality statements?* We conducted fine-grained annotation of the statements. We find academic background and training are disclosed most often, but identity features like race and gender are also common.
June 24, 2025 at 2:49 PM
*What do authors disclose in positionality statements?* We conducted fine-grained annotation of the statements. We find academic background and training are disclosed most often, but identity features like race and gender are also common.
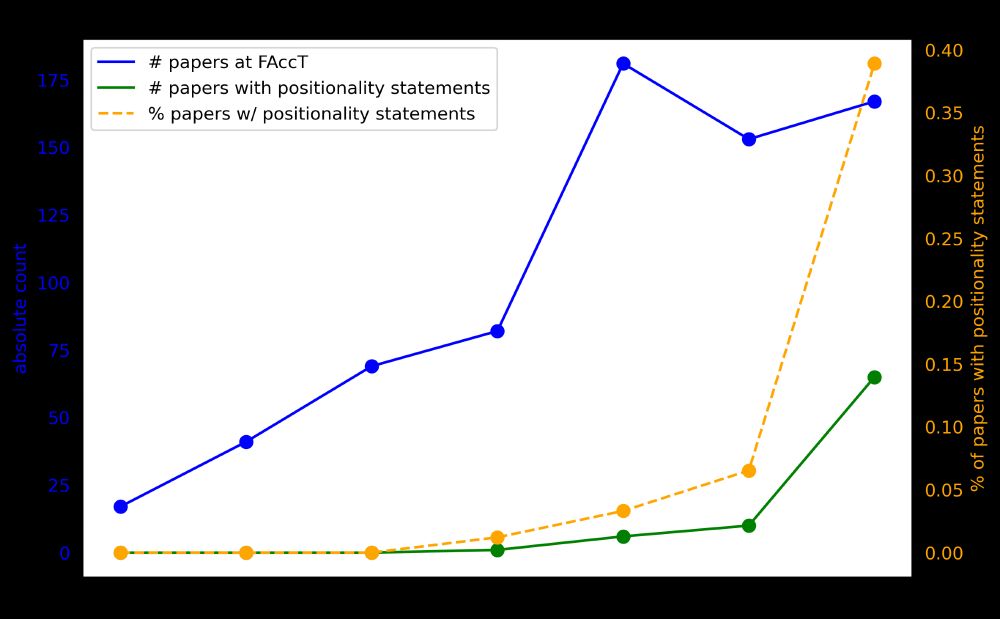
We reviewed papers from the entire history of FAccT for the presence of positionality statements. We find 2024 marked a significant proportional increase in papers that included positionality statements, likely as a result of PC recommendations:
June 24, 2025 at 2:48 PM
We reviewed papers from the entire history of FAccT for the presence of positionality statements. We find 2024 marked a significant proportional increase in papers that included positionality statements, likely as a result of PC recommendations:
In 2024, the FAccT PCs recommended that authors write positionality statements (blog post: medium.com/@alexandra.o...)
Responsible AI Research Needs Impact Statements Too
Alexandra Olteanu, Michael Ekstrand, Carlos Castillo, and Jina Suh
medium.com
June 24, 2025 at 2:47 PM
In 2024, the FAccT PCs recommended that authors write positionality statements (blog post: medium.com/@alexandra.o...)
With ongoing reflection on the impact of computing on society, and the role of researchers in shaping impacts, positionality statements have become more common in computing venues, but little is known about their contents or the impact of conference policy on their presence.
June 24, 2025 at 2:46 PM
With ongoing reflection on the impact of computing on society, and the role of researchers in shaping impacts, positionality statements have become more common in computing venues, but little is known about their contents or the impact of conference policy on their presence.