



Harshit Sikchi
@harshitsikchi.bsky.social
Research @OpenAI. I study Reinforcement Learning. PhD from UT Austin. Previously FAIR Paris, Meta US, NVIDIA, CMU, and IIT Kharagpur.
Website: https://hari-sikchi.github.io/
Website: https://hari-sikchi.github.io/
(6/n) With RLZero, you can just pass in a YouTube video and ask an agent to mimic the behavior instantly. This brings us closer to true zero-shot cross-embodiment transfer.
December 11, 2024 at 7:11 AM
(6/n) With RLZero, you can just pass in a YouTube video and ask an agent to mimic the behavior instantly. This brings us closer to true zero-shot cross-embodiment transfer.
(5/n) RLZero’s Prompt to Policy: Asking a humanoid agent to perform a headstand.
December 11, 2024 at 7:11 AM
(5/n) RLZero’s Prompt to Policy: Asking a humanoid agent to perform a headstand.
(4/n) Reward is an inconvenient and easily hackable form of task specification. Now, we can prompt and obtain behaviors zero-shot with language. Example: Asking a walker agent to perform a cartwheel.
December 11, 2024 at 7:11 AM
(4/n) Reward is an inconvenient and easily hackable form of task specification. Now, we can prompt and obtain behaviors zero-shot with language. Example: Asking a walker agent to perform a cartwheel.
🤖 Introducing RL Zero 🤖: a new approach to transform language into behavior zero-shot for embodied agents without labeled datasets!
December 11, 2024 at 7:11 AM
🤖 Introducing RL Zero 🤖: a new approach to transform language into behavior zero-shot for embodied agents without labeled datasets!
(6/n) With RLZero, you can just pass in a YouTube video and ask an agent to mimic the behavior instantly. This brings us closer to true zero-shot cross-embodiment transfer.
December 10, 2024 at 8:14 AM
(6/n) With RLZero, you can just pass in a YouTube video and ask an agent to mimic the behavior instantly. This brings us closer to true zero-shot cross-embodiment transfer.
(5/n) RLZero’s Prompt to Policy: Asking a humanoid agent to perform a headstand.
December 10, 2024 at 8:14 AM
(5/n) RLZero’s Prompt to Policy: Asking a humanoid agent to perform a headstand.
(4/n) Reward is an inconvenient and easily hackable form of task specification. Now, we can prompt and obtain behaviors zero-shot with language. Example: Asking a walker agent to perform a cartwheel.
December 10, 2024 at 8:14 AM
(4/n) Reward is an inconvenient and easily hackable form of task specification. Now, we can prompt and obtain behaviors zero-shot with language. Example: Asking a walker agent to perform a cartwheel.
What if I told you all solutions for RL lie on a (hyper) plane? Then, we can use that fact to learn a compressed representation for MDP that unlocks efficient policy inference for any reward fn. On this plane, solving RL is equivalent to solving a linear constrained optimization!
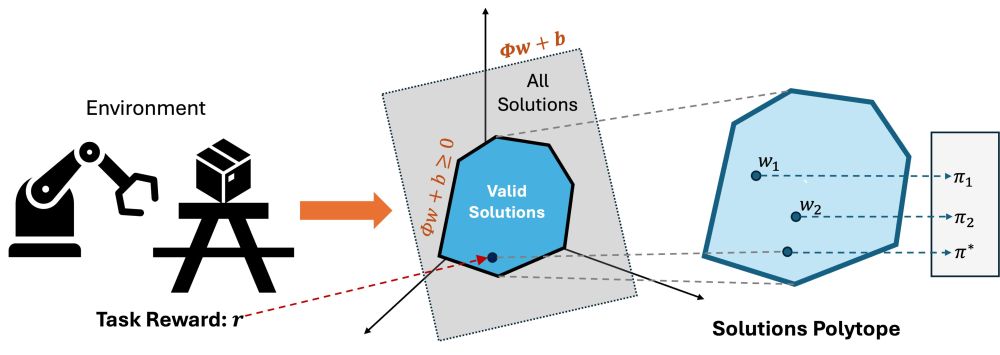
December 3, 2024 at 12:33 AM
What if I told you all solutions for RL lie on a (hyper) plane? Then, we can use that fact to learn a compressed representation for MDP that unlocks efficient policy inference for any reward fn. On this plane, solving RL is equivalent to solving a linear constrained optimization!