



Harris Chan
@harrischan.bsky.social
Research Scientist at @GoogleDeepMind, ML PhD @UofT/@VectorInst. EngSci Grad. Former Canadian Rubik's Cube Champion
Here's my attempt at visualizing the training pipeline for DeepSeek-R1(-Zero) and the distillation to smaller models.
Note they retrain DeepSeek-V3-Base with the new 800k curated data instead of continuing to finetune the checkpoint from the first round of cold-start SFT + RL
Note they retrain DeepSeek-V3-Base with the new 800k curated data instead of continuing to finetune the checkpoint from the first round of cold-start SFT + RL

January 21, 2025 at 1:11 AM
Here's my attempt at visualizing the training pipeline for DeepSeek-R1(-Zero) and the distillation to smaller models.
Note they retrain DeepSeek-V3-Base with the new 800k curated data instead of continuing to finetune the checkpoint from the first round of cold-start SFT + RL
Note they retrain DeepSeek-V3-Base with the new 800k curated data instead of continuing to finetune the checkpoint from the first round of cold-start SFT + RL
If you can imagine it, you can play it in Genie 2 🧞
Our foundation world model is capable of generating interactive worlds controllable with keyboard/mouse actions, starting from a single prompt image
So proud to have been part of this work led by @jparkerholder.bsky.social and @rockt.ai 🙏
Our foundation world model is capable of generating interactive worlds controllable with keyboard/mouse actions, starting from a single prompt image
So proud to have been part of this work led by @jparkerholder.bsky.social and @rockt.ai 🙏

December 5, 2024 at 3:24 AM
If you can imagine it, you can play it in Genie 2 🧞
Our foundation world model is capable of generating interactive worlds controllable with keyboard/mouse actions, starting from a single prompt image
So proud to have been part of this work led by @jparkerholder.bsky.social and @rockt.ai 🙏
Our foundation world model is capable of generating interactive worlds controllable with keyboard/mouse actions, starting from a single prompt image
So proud to have been part of this work led by @jparkerholder.bsky.social and @rockt.ai 🙏
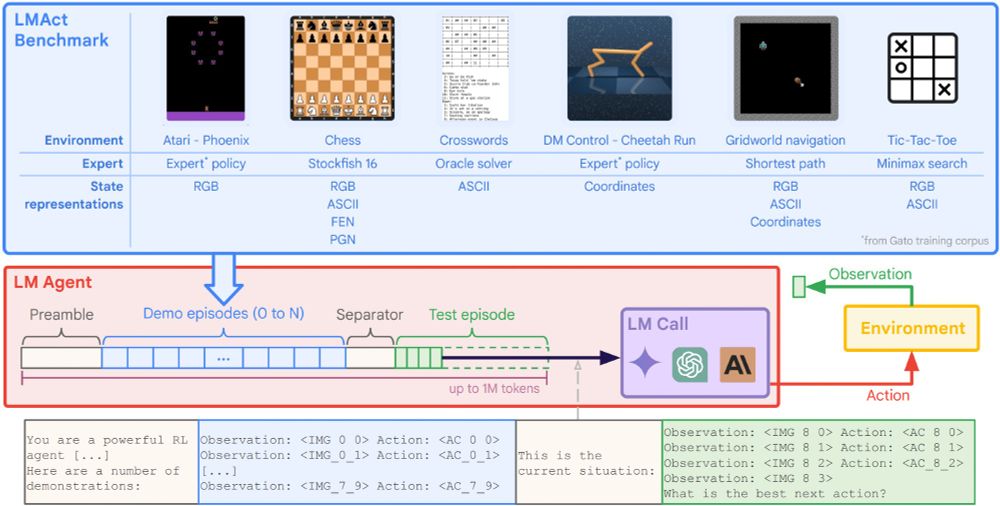
LMs see, can LMs do?
LMAct benchmarks current SOTA foundation models' ability to act in text/visual environments using text as low-level actions in many domains using in-context expert (multimodal) demonstrations. We're excited to see how this benchmark drives further progress!
LMAct benchmarks current SOTA foundation models' ability to act in text/visual environments using text as low-level actions in many domains using in-context expert (multimodal) demonstrations. We're excited to see how this benchmark drives further progress!

Ever wonder how well frontier models (Claude 3.5 Sonnet, Gemini 1.5 Flash & Pro, GPT-4o, o1-mini & o1-preview) play Atari, chess, or tic-tac-toe?
We present LMAct, an in-context imitation learning benchmark with long multimodal demonstrations (arxiv.org/abs/2412.01441).
🧵 1/N
We present LMAct, an in-context imitation learning benchmark with long multimodal demonstrations (arxiv.org/abs/2412.01441).
🧵 1/N
December 5, 2024 at 3:07 AM
LMs see, can LMs do?
LMAct benchmarks current SOTA foundation models' ability to act in text/visual environments using text as low-level actions in many domains using in-context expert (multimodal) demonstrations. We're excited to see how this benchmark drives further progress!
LMAct benchmarks current SOTA foundation models' ability to act in text/visual environments using text as low-level actions in many domains using in-context expert (multimodal) demonstrations. We're excited to see how this benchmark drives further progress!