



📊 RESULTS: State-of-the-Art Performance on 8B size. Qwen3-8B-Base trained on our 212K synthetic data matches performance of DeepSeek-R1-671B on LCB!
🧵4/5
🧵4/5

October 21, 2025 at 2:01 PM
📊 RESULTS: State-of-the-Art Performance on 8B size. Qwen3-8B-Base trained on our 212K synthetic data matches performance of DeepSeek-R1-671B on LCB!
🧵4/5
🧵4/5
💥Introducing new paper: arxiv.org/pdf/2510.17715, QueST — train specialized generators to create challenging coding problems.
From Qwen3-8B-Base
✅ 100K synthetic problems: better than Qwen3-8B
✅ Combining with human written problems: matches DeepSeek-R1-671B
🧵(1/5)
From Qwen3-8B-Base
✅ 100K synthetic problems: better than Qwen3-8B
✅ Combining with human written problems: matches DeepSeek-R1-671B
🧵(1/5)

October 21, 2025 at 2:01 PM
💥Introducing new paper: arxiv.org/pdf/2510.17715, QueST — train specialized generators to create challenging coding problems.
From Qwen3-8B-Base
✅ 100K synthetic problems: better than Qwen3-8B
✅ Combining with human written problems: matches DeepSeek-R1-671B
🧵(1/5)
From Qwen3-8B-Base
✅ 100K synthetic problems: better than Qwen3-8B
✅ Combining with human written problems: matches DeepSeek-R1-671B
🧵(1/5)
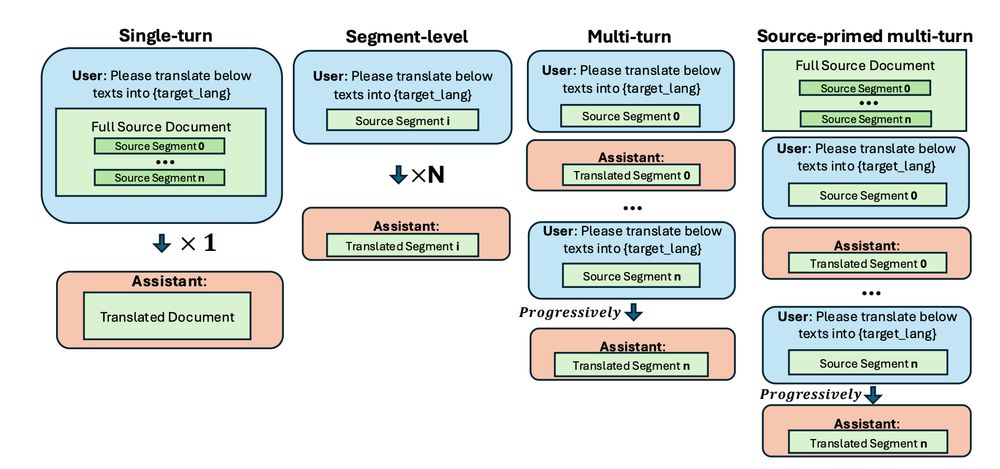
We further propose a source-primed multi-turn variant which allows LLMs to first access the entire source document and then conduct multi-turn chat. It achieves the best performance compared to previous settings when using GPT-4-mini, Qwen-2.5-Instruct, and Llama-3.1-Instruct.

March 14, 2025 at 2:58 PM
We further propose a source-primed multi-turn variant which allows LLMs to first access the entire source document and then conduct multi-turn chat. It achieves the best performance compared to previous settings when using GPT-4-mini, Qwen-2.5-Instruct, and Llama-3.1-Instruct.
I'm thrilled to share my first PhD project, a joint work with
@vamvas.bsky.social and @ricosennrich.bsky.social
Paper link:
arxiv.org/pdf/2503.10494
Long context LLMs have paved the way for document translation, but is simply inputting the whole content the optimal way?
Here's the thread 🧵 [1/n]
@vamvas.bsky.social and @ricosennrich.bsky.social
Paper link:
arxiv.org/pdf/2503.10494
Long context LLMs have paved the way for document translation, but is simply inputting the whole content the optimal way?
Here's the thread 🧵 [1/n]
March 14, 2025 at 2:58 PM
I'm thrilled to share my first PhD project, a joint work with
@vamvas.bsky.social and @ricosennrich.bsky.social
Paper link:
arxiv.org/pdf/2503.10494
Long context LLMs have paved the way for document translation, but is simply inputting the whole content the optimal way?
Here's the thread 🧵 [1/n]
@vamvas.bsky.social and @ricosennrich.bsky.social
Paper link:
arxiv.org/pdf/2503.10494
Long context LLMs have paved the way for document translation, but is simply inputting the whole content the optimal way?
Here's the thread 🧵 [1/n]