



Guy Davidson
@guydav.bsky.social
@guyd33 on the X-bird site. PhD student at NYU, broadly cognitive science x machine learning, specifically richer representations for tasks and cognitive goals. Otherwise found cooking, playing ultimate frisbee, and making hot sauces.
I owe tremendous thanks to many other people, all (or, hopefully, at least most) of whom I mentioned in my acknowledgments. I’m also so grateful my dad could represent my family, and for my wife, Sarah, for, well, everything.

September 17, 2025 at 7:46 PM
I owe tremendous thanks to many other people, all (or, hopefully, at least most) of whom I mentioned in my acknowledgments. I’m also so grateful my dad could represent my family, and for my wife, Sarah, for, well, everything.
Much, much larger thanks to my advisors, @brendenlake.bsky.social and @toddgureckis.bsky.social , for your guidance and mentorship over the last several years. I appreciate you so much, and this wouldn’t have looked the same without you!

September 17, 2025 at 7:46 PM
Much, much larger thanks to my advisors, @brendenlake.bsky.social and @toddgureckis.bsky.social , for your guidance and mentorship over the last several years. I appreciate you so much, and this wouldn’t have looked the same without you!
Belated update #1: I defended my PhD about a month ago! I appreciate the warm reception from everyone who made it in-person and virtually. Thanks to my committee, @lerrelpinto.com, @togelius.bsky.social, and @markkho.bsky.social for your feedback and fun questions.




September 17, 2025 at 7:46 PM
Belated update #1: I defended my PhD about a month ago! I appreciate the warm reception from everyone who made it in-person and virtually. Thanks to my committee, @lerrelpinto.com, @togelius.bsky.social, and @markkho.bsky.social for your feedback and fun questions.
Friends and virtual acquaintances! I’m defending my PhD tomorrow morning at 11:30 AM ET. If anyone would like to watch, let me know and I’ll send you the Zoom link (and if you’re in NYC and feel compelled to join in person, that works, too!)

August 6, 2025 at 6:41 PM
Friends and virtual acquaintances! I’m defending my PhD tomorrow morning at 11:30 AM ET. If anyone would like to watch, let me know and I’ll send you the Zoom link (and if you’re in NYC and feel compelled to join in person, that works, too!)
Finding 5 bonus: Which post-training steps facilitate this? Using the OLMo-2 model family, we find that the SFT and DPO stages each bring a jump in performance, but the final RLVR step doesn't make a difference for the ability to extract instruction FVs. 12/N

May 23, 2025 at 5:38 PM
Finding 5 bonus: Which post-training steps facilitate this? Using the OLMo-2 model family, we find that the SFT and DPO stages each bring a jump in performance, but the final RLVR step doesn't make a difference for the ability to extract instruction FVs. 12/N
Finding 5: We can steer base models with instruction FVs extracted from their post-trained versions. We didn't expect this to work! It's less effective for the Llama-3.2 models that are distilled and smaller. We're also excited to dig into this and see where we can push it. 11/N
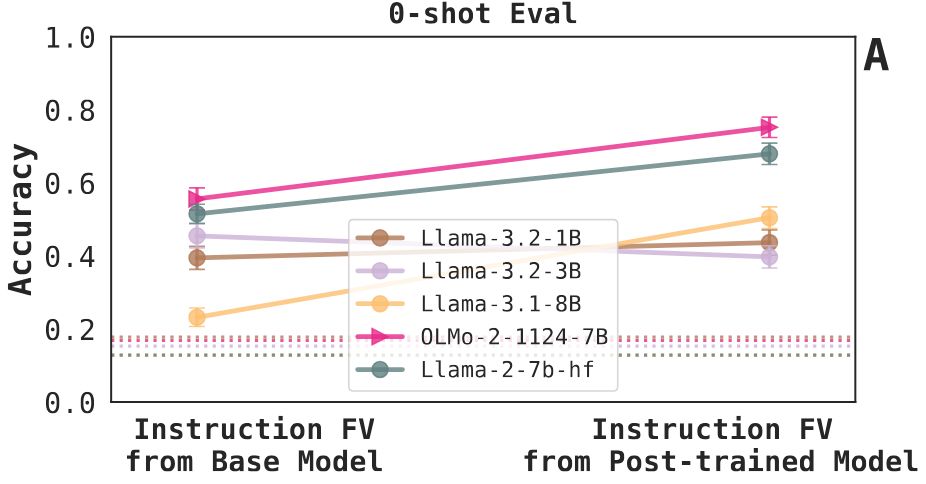
May 23, 2025 at 5:38 PM
Finding 5: We can steer base models with instruction FVs extracted from their post-trained versions. We didn't expect this to work! It's less effective for the Llama-3.2 models that are distilled and smaller. We're also excited to dig into this and see where we can push it. 11/N
Finding 4: The relationship between demonstrations and instructions is asymmetrical. Especially in post-trained models, the top attention heads for instructions appear peripherally useful for demonstrations, more than the opposite case (see paper for details). 10/N
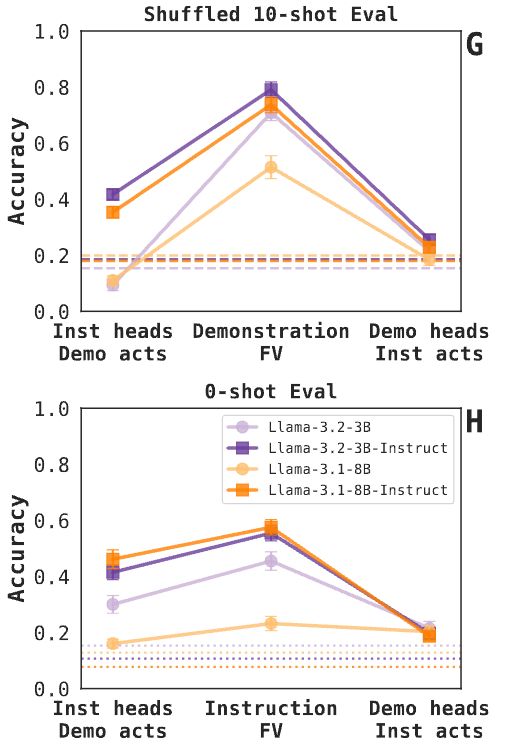
May 23, 2025 at 5:38 PM
Finding 4: The relationship between demonstrations and instructions is asymmetrical. Especially in post-trained models, the top attention heads for instructions appear peripherally useful for demonstrations, more than the opposite case (see paper for details). 10/N
Finding 3 bonus: examining activations in the shared attention heads, we see (a) generally increased similarity with increasing model depth, and (b) no difference in similarity between base and post-trained models (circles and squares). 8/N
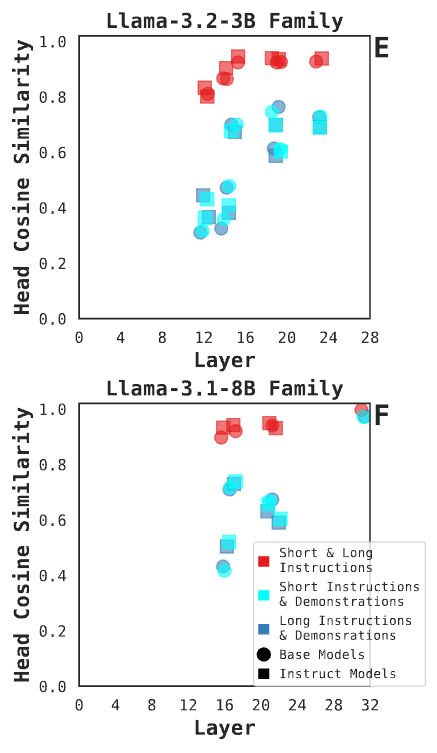
May 23, 2025 at 5:38 PM
Finding 3 bonus: examining activations in the shared attention heads, we see (a) generally increased similarity with increasing model depth, and (b) no difference in similarity between base and post-trained models (circles and squares). 8/N
Finding 3: Different attention heads are identified by the FV procedure between demonstrations and instructions => different mechanisms are involved in creating task representations from different prompt forms. We also see consistent base/post-trained model differences. 7/N
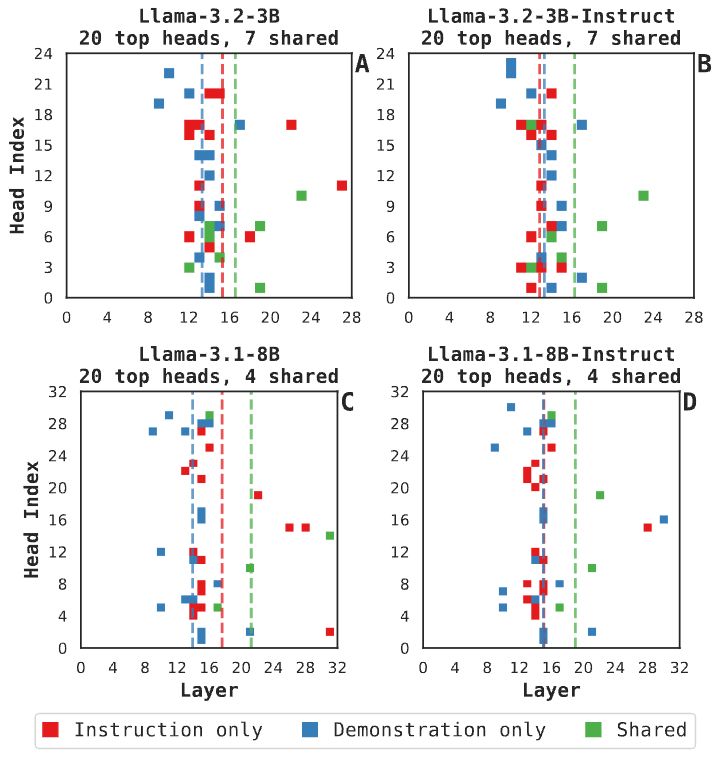
May 23, 2025 at 5:38 PM
Finding 3: Different attention heads are identified by the FV procedure between demonstrations and instructions => different mechanisms are involved in creating task representations from different prompt forms. We also see consistent base/post-trained model differences. 7/N
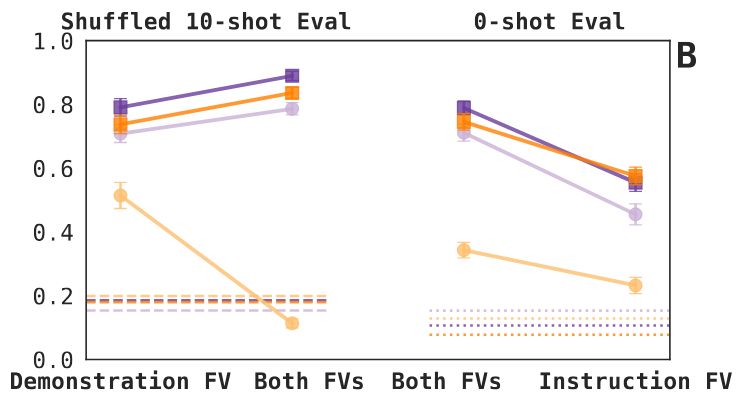
Finding 2: Demonstration and instruction FVs help when applied to a model together (again, with the caveat of the 3.1-8B base model) => they carry (at least some) different information => these different forms elicit non-identical task representations (at least, as FVs). 6/N
May 23, 2025 at 5:38 PM
Finding 2: Demonstration and instruction FVs help when applied to a model together (again, with the caveat of the 3.1-8B base model) => they carry (at least some) different information => these different forms elicit non-identical task representations (at least, as FVs). 6/N
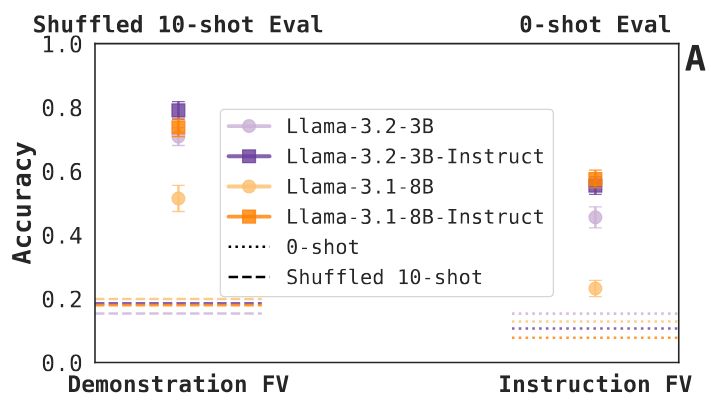
Finding 1: Instruction FVs increase zero-shot task accuracy (even if not as much as demonstration FVs increase accuracy in a shuffled 10-shot evaluation). The 3.1-8B base model trails the rest; we think it has to do with sensitivity to the chosen FV intervention depth. 5/N
May 23, 2025 at 5:38 PM
Finding 1: Instruction FVs increase zero-shot task accuracy (even if not as much as demonstration FVs increase accuracy in a shuffled 10-shot evaluation). The 3.1-8B base model trails the rest; we think it has to do with sensitivity to the chosen FV intervention depth. 5/N
TL;DR: We successfully extend FVs to ICL instruction prompts and extract instruction function vectors that raise zero-shot task accuracy. We offer evidence that they carry different information from demonstration FVs and are represented by mostly different attention heads. 4/N

May 23, 2025 at 5:38 PM
TL;DR: We successfully extend FVs to ICL instruction prompts and extract instruction function vectors that raise zero-shot task accuracy. We offer evidence that they carry different information from demonstration FVs and are represented by mostly different attention heads. 4/N
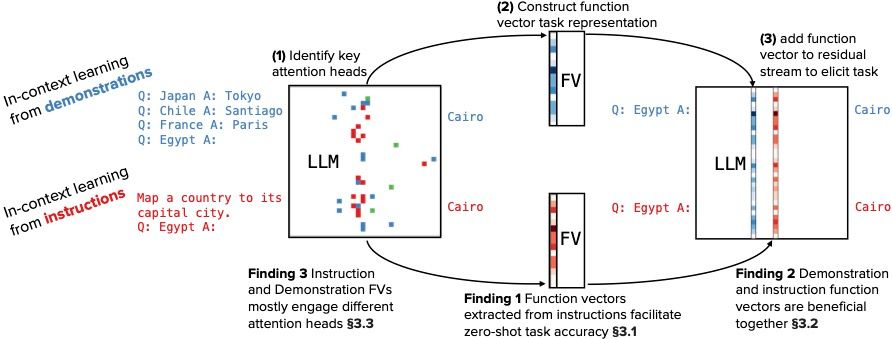
We were inspired by @davidbau.bsky.social 's talk at NYU last fall, in which he discussed the function vector work led by @ericwtodd.bsky.social . They show how to extract task representations (= FVs) from ICL demonstrations. Could we extend FVs to instructions? What would we learn? 3/N
May 23, 2025 at 5:38 PM
We were inspired by @davidbau.bsky.social 's talk at NYU last fall, in which he discussed the function vector work led by @ericwtodd.bsky.social . They show how to extract task representations (= FVs) from ICL demonstrations. Could we extend FVs to instructions? What would we learn? 3/N
New preprint alert! We often prompt ICL tasks using either demonstrations or instructions. How much does the form of the prompt matter to the task representation formed by a language model? Stick around to find out 1/N

May 23, 2025 at 5:38 PM
New preprint alert! We often prompt ICL tasks using either demonstrations or instructions. How much does the form of the prompt matter to the task representation formed by a language model? Stick around to find out 1/N
We then run a detailed human evaluation of model-generated programs, asking participants to rate games (back-translated to natural language) on attributes such as fun, creativity, and difficulty. What did we find? You'll have to read the paper to find out! 10/N

February 21, 2025 at 4:29 PM
We then run a detailed human evaluation of model-generated programs, asking participants to rate games (back-translated to natural language) on attributes such as fun, creativity, and difficulty. What did we find? You'll have to read the paper to find out! 10/N
Model details: we contrastively learn a fitness function by corrupting real programs and learning to distinguish them from real ones, then use MAP-Elites (@jb-mouret.bsky.social and @jeffclune.com) to generate diverse programs that maximize our fitness metric. 9/N

February 21, 2025 at 4:29 PM
Model details: we contrastively learn a fitness function by corrupting real programs and learning to distinguish them from real ones, then use MAP-Elites (@jb-mouret.bsky.social and @jeffclune.com) to generate diverse programs that maximize our fitness metric. 9/N
We then built a computational model -- from a small number of human-created programs (green), we generate both similar examples (blue) and novel ones (purple), which is hard, in part, because the grammar we defined is vastly underconstrained (leading to failure modes, red). 8/N

February 21, 2025 at 4:29 PM
We then built a computational model -- from a small number of human-created programs (green), we generate both similar examples (blue) and novel ones (purple), which is hard, in part, because the grammar we defined is vastly underconstrained (leading to failure modes, red). 8/N
We report some fun analyses of this data. My favorite, pictured below, highlights compositional motif reuse between programs in our dataset (improved versions of work previously reported in escholarship.org/uc/item/18x3...: 7/N

February 21, 2025 at 4:29 PM
We report some fun analyses of this data. My favorite, pictured below, highlights compositional motif reuse between programs in our dataset (improved versions of work previously reported in escholarship.org/uc/item/18x3...: 7/N
Behavioral work: we built an experiment based on AI2-THOR where participants created games in an environment resembling a child's playroom. We collected a dataset of 98 games and translated them to programs in a domain-specific language we created to capture semantics. 6/N

February 21, 2025 at 4:29 PM
Behavioral work: we built an experiment based on AI2-THOR where participants created games in an environment resembling a child's playroom. We collected a dataset of 98 games and translated them to programs in a domain-specific language we created to capture semantics. 6/N
Why such programs? 1) explicit structure facilitates compositional motif reuse (highlighted in the bottom part of the figure), 2) program representations make semantics explicit, and 3) programs are interpretable to provide a signal ('reward') toward goal achievement. 4/N

February 21, 2025 at 4:29 PM
Why such programs? 1) explicit structure facilitates compositional motif reuse (highlighted in the bottom part of the figure), 2) program representations make semantics explicit, and 3) programs are interpretable to provide a signal ('reward') toward goal achievement. 4/N
TL;DR: we think about representing goals as a particular kind of symbolic program we term 'reward-producing programs' (pseudocode examples below). These programs are interpreted to map between behavior to a reward indicating progress or a degree of success. 3/N
February 21, 2025 at 4:29 PM
TL;DR: we think about representing goals as a particular kind of symbolic program we term 'reward-producing programs' (pseudocode examples below). These programs are interpreted to map between behavior to a reward indicating progress or a degree of success. 3/N
Out today in Nature Machine Intelligence!
From childhood on, people can create novel, playful, and creative goals. Models have yet to capture this ability. We propose a new way to represent goals and report a model that can generate human-like goals in a playful setting... 1/N
From childhood on, people can create novel, playful, and creative goals. Models have yet to capture this ability. We propose a new way to represent goals and report a model that can generate human-like goals in a playful setting... 1/N

February 21, 2025 at 4:29 PM
Out today in Nature Machine Intelligence!
From childhood on, people can create novel, playful, and creative goals. Models have yet to capture this ability. We propose a new way to represent goals and report a model that can generate human-like goals in a playful setting... 1/N
From childhood on, people can create novel, playful, and creative goals. Models have yet to capture this ability. We propose a new way to represent goals and report a model that can generate human-like goals in a playful setting... 1/N
I've been really enjoying the new Gemini 2.0-Flash as my go-to 'how do I do this', but the Experimental tag is there for a reason. The funniest failure mode I've had yet:

January 22, 2025 at 9:24 PM
I've been really enjoying the new Gemini 2.0-Flash as my go-to 'how do I do this', but the Experimental tag is there for a reason. The funniest failure mode I've had yet:
Big, if true
(Definitely true)
(Not very big; might grow up to be!)
(Meet Lila!!)
(Definitely true)
(Not very big; might grow up to be!)
(Meet Lila!!)




December 26, 2024 at 9:17 PM
Big, if true
(Definitely true)
(Not very big; might grow up to be!)
(Meet Lila!!)
(Definitely true)
(Not very big; might grow up to be!)
(Meet Lila!!)
4 (got the falling order right, but the physics feels wonky):
December 18, 2024 at 3:48 AM
4 (got the falling order right, but the physics feels wonky):