


Golub Capital Social Impact Lab
@gsbsilab.bsky.social
Led by @susanathey.bsky.social, the Golub Capital Social Impact Lab at the Stanford University Graduate School of Business uses digital technology and social science to improve the effectiveness of social sector organizations.
In our theory, we show how the estimator’s bias depends on product of imbalance across units, time and bias of the regression adjustment, so that effectively only one of these three needs to be small. This gives flexibility in the choice of unit, time weights and outcome model.

October 20, 2025 at 5:21 PM
In our theory, we show how the estimator’s bias depends on product of imbalance across units, time and bias of the regression adjustment, so that effectively only one of these three needs to be small. This gives flexibility in the choice of unit, time weights and outcome model.
In contrast, TROP embeds all these estimators as special cases, while it learns which components of such estimators are most relevant to accurately predict the counterfactual. We evaluate TROP through a large set of simulation studies calibrated to match real-world applications.

October 20, 2025 at 5:21 PM
In contrast, TROP embeds all these estimators as special cases, while it learns which components of such estimators are most relevant to accurately predict the counterfactual. We evaluate TROP through a large set of simulation studies calibrated to match real-world applications.
Why this matters: TROP learns the combination of time, unit weights and regression adjustments that most accurately predict the counterfactual as below. Common estimators of causal effects in panel data (DID/TWFE, SC, MC, SDID) rest on different assumptions, but all can fail in applications.

October 20, 2025 at 5:21 PM
Why this matters: TROP learns the combination of time, unit weights and regression adjustments that most accurately predict the counterfactual as below. Common estimators of causal effects in panel data (DID/TWFE, SC, MC, SDID) rest on different assumptions, but all can fail in applications.
New paper: Triply Robust Panel Estimators (TROP) by @susanathey.bsky.social @guidoimbens.bsky.social Zhaonan Qu @vivianodavide.bsky.social.
arxiv.org/pdf/2508.21536
arxiv.org/pdf/2508.21536

October 20, 2025 at 5:21 PM
New paper: Triply Robust Panel Estimators (TROP) by @susanathey.bsky.social @guidoimbens.bsky.social Zhaonan Qu @vivianodavide.bsky.social.
arxiv.org/pdf/2508.21536
arxiv.org/pdf/2508.21536
Earlier this month @susanathey.bsky.social joined Stanford University President Levin, @siepr.bsky.social Director @nealemahoney.bsky.social and other distinguished faculty to connect over cutting-edge research developments at Stanford Open Minds New York.

September 24, 2025 at 6:15 PM
Earlier this month @susanathey.bsky.social joined Stanford University President Levin, @siepr.bsky.social Director @nealemahoney.bsky.social and other distinguished faculty to connect over cutting-edge research developments at Stanford Open Minds New York.
Listen to Raj Chetty talk about how surrogate indices make it possible to make decisions more quickly using multiple short-term outcomes to predict long-term effects with @nber.org
www.nber.org/research/vid...
www.nber.org/research/vid...

August 27, 2025 at 6:33 PM
Listen to Raj Chetty talk about how surrogate indices make it possible to make decisions more quickly using multiple short-term outcomes to predict long-term effects with @nber.org
www.nber.org/research/vid...
www.nber.org/research/vid...
AI & digitisation are rapidly reshaping the way we work.
Policymakers need to understand how, and what to do about it.
Watch @Susan_Athey speak to G20 leaders about these issues tomorrow 16 July @ 13:30 CET. #G20SouthAfrica
bit.ly/3GyMFgm or bit.ly/44PTXFP
Policymakers need to understand how, and what to do about it.
Watch @Susan_Athey speak to G20 leaders about these issues tomorrow 16 July @ 13:30 CET. #G20SouthAfrica
bit.ly/3GyMFgm or bit.ly/44PTXFP

July 15, 2025 at 1:42 PM
AI & digitisation are rapidly reshaping the way we work.
Policymakers need to understand how, and what to do about it.
Watch @Susan_Athey speak to G20 leaders about these issues tomorrow 16 July @ 13:30 CET. #G20SouthAfrica
bit.ly/3GyMFgm or bit.ly/44PTXFP
Policymakers need to understand how, and what to do about it.
Watch @Susan_Athey speak to G20 leaders about these issues tomorrow 16 July @ 13:30 CET. #G20SouthAfrica
bit.ly/3GyMFgm or bit.ly/44PTXFP
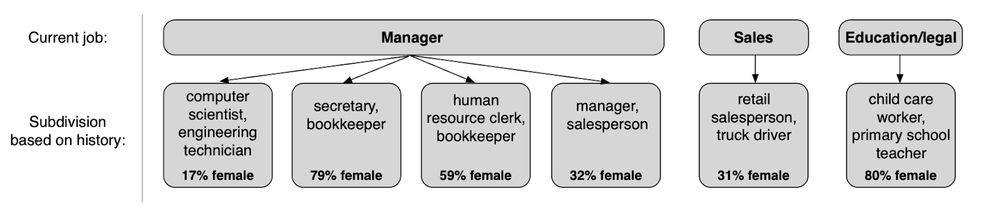
Analyzing representations tells us where history explains the gap.
Ex: there are two kinds of managers: those who used to be engineers and those who didn’t. The first group gets paid more and has more males than the second.
Models that don’t use history omit this distinction.
Ex: there are two kinds of managers: those who used to be engineers and those who didn’t. The first group gets paid more and has more males than the second.
Models that don’t use history omit this distinction.
June 30, 2025 at 12:16 PM
Analyzing representations tells us where history explains the gap.
Ex: there are two kinds of managers: those who used to be engineers and those who didn’t. The first group gets paid more and has more males than the second.
Models that don’t use history omit this distinction.
Ex: there are two kinds of managers: those who used to be engineers and those who didn’t. The first group gets paid more and has more males than the second.
Models that don’t use history omit this distinction.
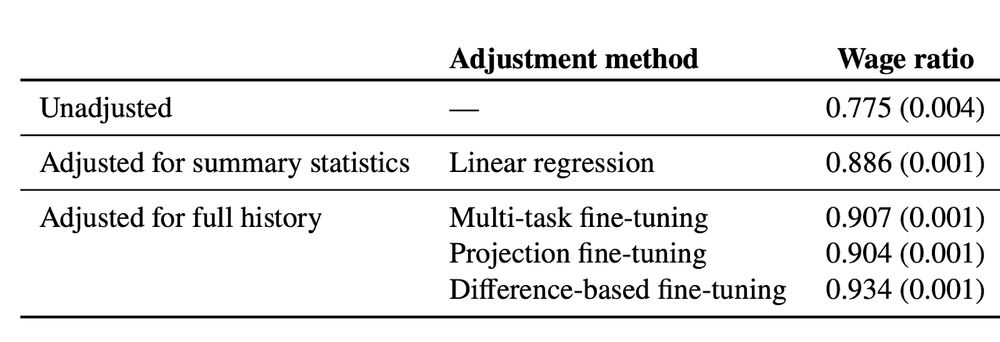
We use these methods to estimate wage gaps adjusted for full job history, following the literature on gender wage gaps.
History explains a substantial fraction of the remaining wage gap when compared to simpler methods. But there’s still a lot that history can’t account for.
History explains a substantial fraction of the remaining wage gap when compared to simpler methods. But there’s still a lot that history can’t account for.
June 30, 2025 at 12:16 PM
We use these methods to estimate wage gaps adjusted for full job history, following the literature on gender wage gaps.
History explains a substantial fraction of the remaining wage gap when compared to simpler methods. But there’s still a lot that history can’t account for.
History explains a substantial fraction of the remaining wage gap when compared to simpler methods. But there’s still a lot that history can’t account for.
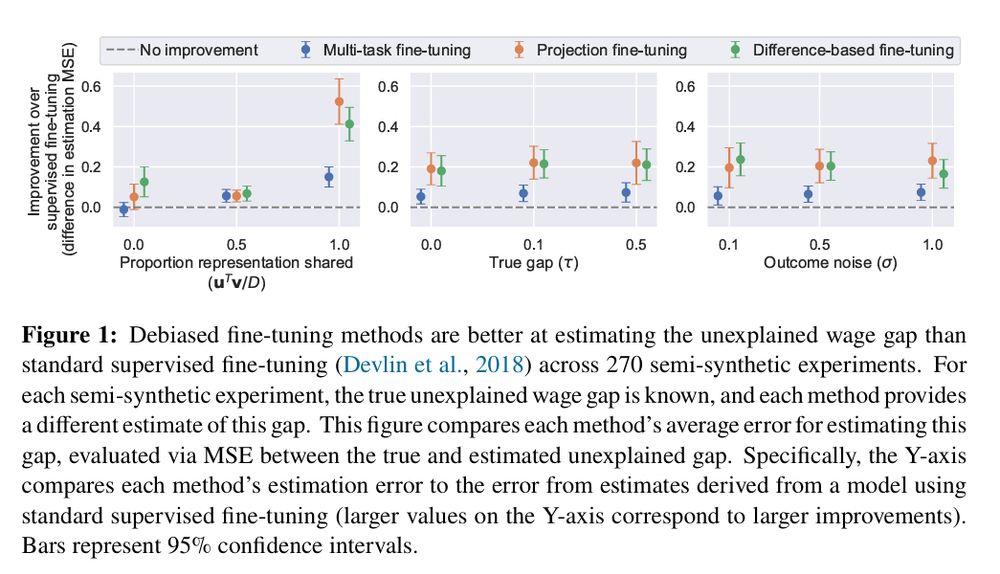
This result motivates new fine-tuning strategies.
We consider 3 strategies similar to methods from the causal estimation literature. E.g. optimize representations to predict the *difference* in male-female wages instead of individual wages.
All perform well on synthetic data.
We consider 3 strategies similar to methods from the causal estimation literature. E.g. optimize representations to predict the *difference* in male-female wages instead of individual wages.
All perform well on synthetic data.
June 30, 2025 at 12:16 PM
This result motivates new fine-tuning strategies.
We consider 3 strategies similar to methods from the causal estimation literature. E.g. optimize representations to predict the *difference* in male-female wages instead of individual wages.
All perform well on synthetic data.
We consider 3 strategies similar to methods from the causal estimation literature. E.g. optimize representations to predict the *difference* in male-female wages instead of individual wages.
All perform well on synthetic data.
New result: Fast + consistent estimates are possible even if a representation drops info
Two main fine-tuning conditions:
1. Representation only drops info that isn't correlated w/ both wage & gender
2. Representation is simple enough that it’s easy to model wage & gender from it
Two main fine-tuning conditions:
1. Representation only drops info that isn't correlated w/ both wage & gender
2. Representation is simple enough that it’s easy to model wage & gender from it

June 30, 2025 at 12:16 PM
New result: Fast + consistent estimates are possible even if a representation drops info
Two main fine-tuning conditions:
1. Representation only drops info that isn't correlated w/ both wage & gender
2. Representation is simple enough that it’s easy to model wage & gender from it
Two main fine-tuning conditions:
1. Representation only drops info that isn't correlated w/ both wage & gender
2. Representation is simple enough that it’s easy to model wage & gender from it
Foundation models are usually fine-tuned to make predictions (like wages).
But representations fine-tuned this way can induce omitted variable bias: the gap adjusted for full history can be different from the gap adjusted for the representation of job history.
But representations fine-tuned this way can induce omitted variable bias: the gap adjusted for full history can be different from the gap adjusted for the representation of job history.

June 30, 2025 at 12:16 PM
Foundation models are usually fine-tuned to make predictions (like wages).
But representations fine-tuned this way can induce omitted variable bias: the gap adjusted for full history can be different from the gap adjusted for the representation of job history.
But representations fine-tuned this way can induce omitted variable bias: the gap adjusted for full history can be different from the gap adjusted for the representation of job history.
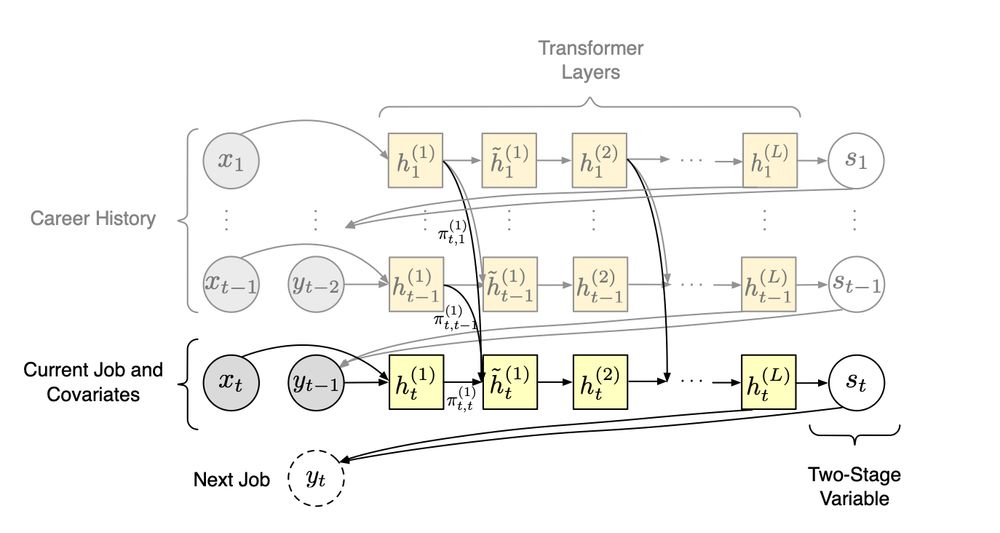
We use CAREER, a foundation model of job histories. It’s pretrained on resumes but its representations can be fine-tuned on the smaller datasets used to estimate wage gaps.
June 30, 2025 at 12:16 PM
We use CAREER, a foundation model of job histories. It’s pretrained on resumes but its representations can be fine-tuned on the smaller datasets used to estimate wage gaps.
Ex.: estimating the gender wage gap between men & women with the same job histories.
A large literature decomposes wage gaps into two parts: the part “explained” by gender gaps in observed characteristics (e.g. education, experience), and the part that’s “unexplained.”
A large literature decomposes wage gaps into two parts: the part “explained” by gender gaps in observed characteristics (e.g. education, experience), and the part that’s “unexplained.”

June 30, 2025 at 12:16 PM
Ex.: estimating the gender wage gap between men & women with the same job histories.
A large literature decomposes wage gaps into two parts: the part “explained” by gender gaps in observed characteristics (e.g. education, experience), and the part that’s “unexplained.”
A large literature decomposes wage gaps into two parts: the part “explained” by gender gaps in observed characteristics (e.g. education, experience), and the part that’s “unexplained.”
Foundation models make great predictions. How should we use them for estimation problems in social science?
New PNAS paper @susanathey.bsky.social & @keyonv.bsky.social & @Blei Lab:
Bad news: Good predictions ≠ good estimates.
Good news: Good estimates possible by fine-tuning models differently 🧵
New PNAS paper @susanathey.bsky.social & @keyonv.bsky.social & @Blei Lab:
Bad news: Good predictions ≠ good estimates.
Good news: Good estimates possible by fine-tuning models differently 🧵

June 30, 2025 at 12:16 PM
Foundation models make great predictions. How should we use them for estimation problems in social science?
New PNAS paper @susanathey.bsky.social & @keyonv.bsky.social & @Blei Lab:
Bad news: Good predictions ≠ good estimates.
Good news: Good estimates possible by fine-tuning models differently 🧵
New PNAS paper @susanathey.bsky.social & @keyonv.bsky.social & @Blei Lab:
Bad news: Good predictions ≠ good estimates.
Good news: Good estimates possible by fine-tuning models differently 🧵
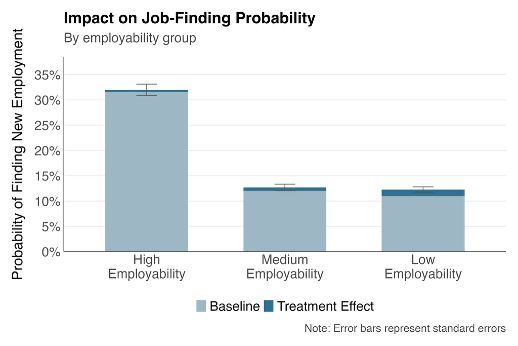
Who benefited most? The boost was greatest for learners with the lowest initial job prospects
May 22, 2025 at 3:03 PM
Who benefited most? The boost was greatest for learners with the lowest initial job prospects
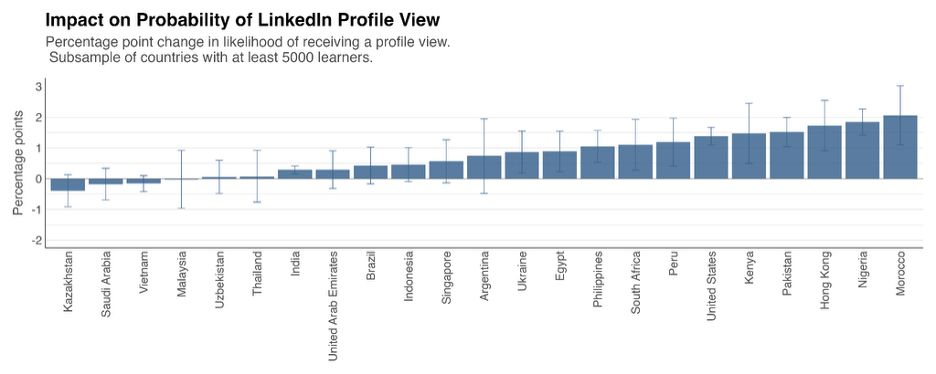
After learners earned a certificate, we randomly assigned a subset to the treatment group who got a prompt to easily add their new credential to LinkedIn. The nudge worked. Treated learners added credentials to their LinkedIn accounts, and these certificates received visits from LinkedIn
May 22, 2025 at 3:03 PM
After learners earned a certificate, we randomly assigned a subset to the treatment group who got a prompt to easily add their new credential to LinkedIn. The nudge worked. Treated learners added credentials to their LinkedIn accounts, and these certificates received visits from LinkedIn
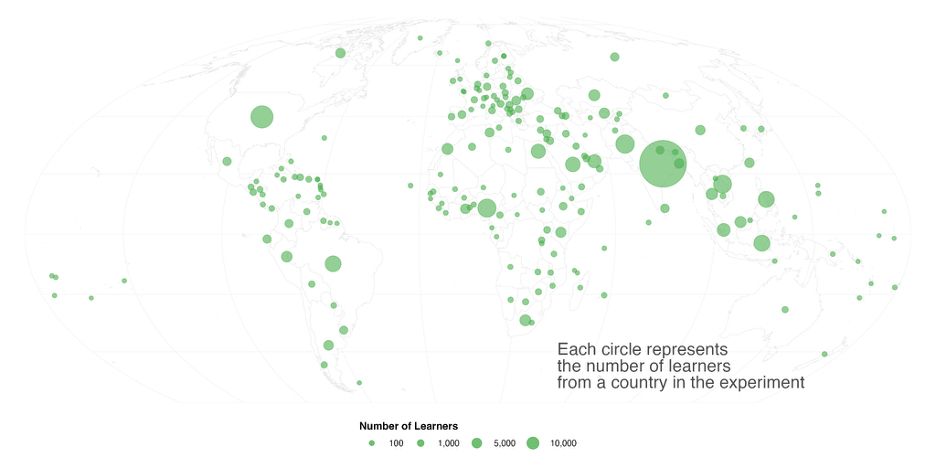
We ran a global, randomized trial with ~800,000 Coursera learners who had earned certificates, and who either came from a developing country or had no college degree. Do they get more jobs if they link to their (verified) Coursera certificate on LinkedIn?
May 22, 2025 at 3:03 PM
We ran a global, randomized trial with ~800,000 Coursera learners who had earned certificates, and who either came from a developing country or had no college degree. Do they get more jobs if they link to their (verified) Coursera certificate on LinkedIn?
Who benefited most? The boost was greatest for learners with the lowest initial job prospects.
May 22, 2025 at 2:55 PM
Who benefited most? The boost was greatest for learners with the lowest initial job prospects.
After learners earned a certificate, we randomly assigned a subset to the treatment group who got a prompt to easily add their new credential to LinkedIn. The nudge worked. Treated learners added credentials to their LinkedIn accounts, and these certificates received visits from LinkedIn
May 22, 2025 at 2:55 PM
After learners earned a certificate, we randomly assigned a subset to the treatment group who got a prompt to easily add their new credential to LinkedIn. The nudge worked. Treated learners added credentials to their LinkedIn accounts, and these certificates received visits from LinkedIn
We ran a global, randomized trial with ~800,000 Coursera learners who had earned certificates, and who either came from a developing country or had no college degree. Do they get more jobs if they link to their (verified) Coursera certificate on LinkedIn?
May 22, 2025 at 2:55 PM
We ran a global, randomized trial with ~800,000 Coursera learners who had earned certificates, and who either came from a developing country or had no college degree. Do they get more jobs if they link to their (verified) Coursera certificate on LinkedIn?