




Greg Woodin
@gregwoodin.bsky.social
Research Fellow in Data Sciences at UCL 📖 💬
Multimodality, numbers, iconicity, metaphor, gesture 🤏 🔢
#rstats #python #datascience #openscience 💻 🔓
https://www.gregwoodin.co.uk/
https://scholar.google.co.uk/citations?user=7x
Multimodality, numbers, iconicity, metaphor, gesture 🤏 🔢
#rstats #python #datascience #openscience 💻 🔓
https://www.gregwoodin.co.uk/
https://scholar.google.co.uk/citations?user=7x
My research/conference visit to Marseille and Aix is coming to a close and it's been a real adventure. Feel very grateful to be able to do things like this as part of my job. Lots of interesting conversations, great food, sightseeing, and productive collaboration. Hope to see you again soon 👋🏻




October 2, 2025 at 1:38 PM
My research/conference visit to Marseille and Aix is coming to a close and it's been a real adventure. Feel very grateful to be able to do things like this as part of my job. Lots of interesting conversations, great food, sightseeing, and productive collaboration. Hope to see you again soon 👋🏻
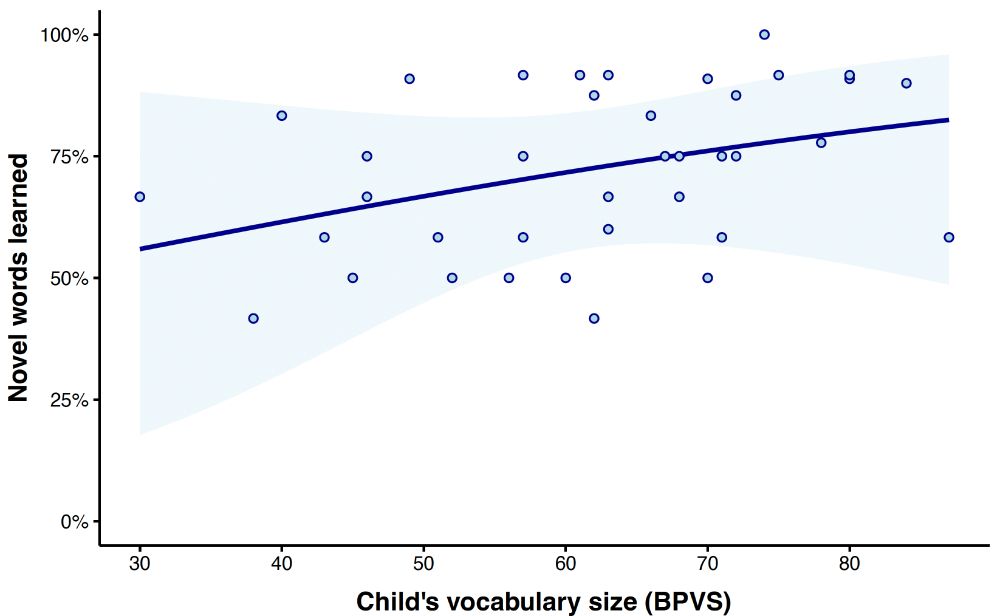
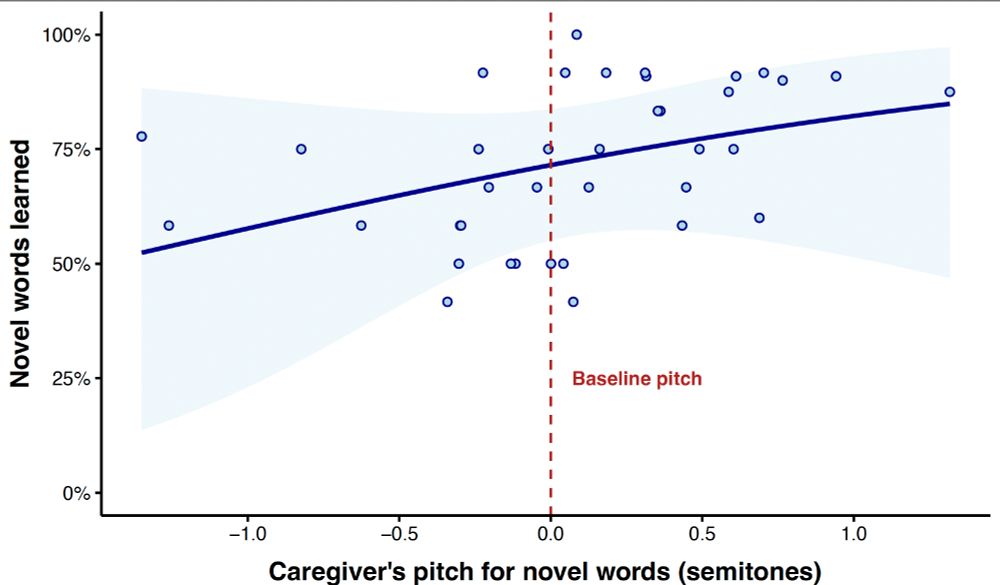
Some of the predictor-specific trends for word learning... The speaking rate finding continues to puzzle us!


September 25, 2025 at 4:20 PM
Some of the predictor-specific trends for word learning... The speaking rate finding continues to puzzle us!
Some graphs to pique your interest... and also because converting to PDF corrupted the picture quality on the slides 😅

September 25, 2025 at 4:17 PM
Some graphs to pique your interest... and also because converting to PDF corrupted the picture quality on the slides 😅
Pleased that my new chapter that will be published in the International Encyclopedia of Language and Linguistics has now been published online: www.sciencedirect.com/science/arti...

July 28, 2025 at 11:38 AM
Pleased that my new chapter that will be published in the International Encyclopedia of Language and Linguistics has now been published online: www.sciencedirect.com/science/arti...
Pleased that my paper with @gabriellavigliocco.bsky.social, @fourtassi.bsky.social, Yan Gu, and Stefano James has been accepted as a talk at this year's Embodied and Situated Language Processing conference at Aix-Marseille University. Abstract below 👇

July 15, 2025 at 8:52 AM
Pleased that my paper with @gabriellavigliocco.bsky.social, @fourtassi.bsky.social, Yan Gu, and Stefano James has been accepted as a talk at this year's Embodied and Situated Language Processing conference at Aix-Marseille University. Abstract below 👇
Currently wrapping up work on a Statistical Consultancy project for @marahjaraisy.bsky.social's investigation into the Kufr Qassem deaf community, focusing on semiotic strategies used for tracking referents in signed narratives, part of @adamcschembri.bsky.social's ERC-funded SignMorph grant. (1/4)

June 1, 2025 at 4:44 PM
Currently wrapping up work on a Statistical Consultancy project for @marahjaraisy.bsky.social's investigation into the Kufr Qassem deaf community, focusing on semiotic strategies used for tracking referents in signed narratives, part of @adamcschembri.bsky.social's ERC-funded SignMorph grant. (1/4)
Pleased to have my first solo publication, 'Iconicity in language and communication', accepted for print in the International Encyclopedia of Language and Linguistics, 3rd Edition. 😌

May 14, 2025 at 10:23 AM
Pleased to have my first solo publication, 'Iconicity in language and communication', accepted for print in the International Encyclopedia of Language and Linguistics, 3rd Edition. 😌
Anyone else get Solero vibes? Crazy how colours can trigger such strong associations/feelings.

March 25, 2025 at 10:37 AM
Anyone else get Solero vibes? Crazy how colours can trigger such strong associations/feelings.
Thanks for having me! If you couldn't make it, the slides can be downloaded at osf.io/p2h95.

March 19, 2025 at 2:20 PM
Thanks for having me! If you couldn't make it, the slides can be downloaded at osf.io/p2h95.
This Wednesday (19th March) at 1pm GMT, I'll be virtually presenting this work, co-authored with @bodowinter.bsky.social and @lordlorson.bsky.social, at the University of Edinburgh's Psycholinguistics Coffee meeting. DM me or email me at gawoodin@gmail.com for the URL! ☺️

March 17, 2025 at 9:11 AM
This Wednesday (19th March) at 1pm GMT, I'll be virtually presenting this work, co-authored with @bodowinter.bsky.social and @lordlorson.bsky.social, at the University of Edinburgh's Psycholinguistics Coffee meeting. DM me or email me at gawoodin@gmail.com for the URL! ☺️
Thanks! This basic regex I wrote is pretty accurate (92.5%), with a higher rate of false positives (12.5%) than negatives (2.5%). I tried ChatGPT as well and it was just as accurate, although it didn't make exactly the same mistakes. Most of the questions are marked with question marks as well.

February 19, 2025 at 10:58 AM
Thanks! This basic regex I wrote is pretty accurate (92.5%), with a higher rate of false positives (12.5%) than negatives (2.5%). I tried ChatGPT as well and it was just as accurate, although it didn't make exactly the same mistakes. Most of the questions are marked with question marks as well.
I will be presenting this work at @davidmsidhu.bsky.social's Cognition, Language, Sound Symbolism, Iconicity (CLaSSI) Lab this Thursday (6th) at 17:00 GMT. Feel free to send either of us a DM or email and we'll get back to you with the Zoom link ☺️

February 3, 2025 at 3:11 PM
I will be presenting this work at @davidmsidhu.bsky.social's Cognition, Language, Sound Symbolism, Iconicity (CLaSSI) Lab this Thursday (6th) at 17:00 GMT. Feel free to send either of us a DM or email and we'll get back to you with the Zoom link ☺️
Really enjoyed visiting @gabriellavigliocco.bsky.social and my new colleagues in the Language and Cognition Lab today! I presented a new paper examining round number frequencies, indefinite hyperbolic numbers (e.g., 'umpteen', 'squillion'), and rounding in jigsaw puzzles. Take a look: osf.io/kga4c

January 17, 2025 at 9:00 PM
Really enjoyed visiting @gabriellavigliocco.bsky.social and my new colleagues in the Language and Cognition Lab today! I presented a new paper examining round number frequencies, indefinite hyperbolic numbers (e.g., 'umpteen', 'squillion'), and rounding in jigsaw puzzles. Take a look: osf.io/kga4c
Log frequencies of 'N seconds' and 'N minutes' in COCA for numbers 1–60, showing clear overrepresentation of multiples of 5. Strikingly similar patterns across the two scales. Radar plots superimposed on a clockface. Getting creative with it! 😅 I love this part of my job.

December 4, 2024 at 11:09 AM
Log frequencies of 'N seconds' and 'N minutes' in COCA for numbers 1–60, showing clear overrepresentation of multiples of 5. Strikingly similar patterns across the two scales. Radar plots superimposed on a clockface. Getting creative with it! 😅 I love this part of my job.
Here's a sneak preview of what I'm working on: a bumper paper comprising five analyses showcasing the prevalence of imprecision in number use. Numerical language is often vague, despite affording precision.

November 29, 2024 at 1:37 PM
Here's a sneak preview of what I'm working on: a bumper paper comprising five analyses showcasing the prevalence of imprecision in number use. Numerical language is often vague, despite affording precision.
As a caveat to this trend, measurements—especially larger, unround ones—were relatively more likely to be represented as numerals. It is possible that the representational format of a number acts as a probabilistic cue that helps people interpret how a number is used. (10/11) 👇

November 20, 2024 at 9:46 AM
As a caveat to this trend, measurements—especially larger, unround ones—were relatively more likely to be represented as numerals. It is possible that the representational format of a number acts as a probabilistic cue that helps people interpret how a number is used. (10/11) 👇
In writing, cardinals were generally more often represented as number words (e.g., 'twenty million people', 'one hundred centimeters'), whereas ordinals and nominals were more often represented as numerals (e.g., 'the year 2000', 'bus number 23'). (9/11) 👇

November 20, 2024 at 9:46 AM
In writing, cardinals were generally more often represented as number words (e.g., 'twenty million people', 'one hundred centimeters'), whereas ordinals and nominals were more often represented as numerals (e.g., 'the year 2000', 'bus number 23'). (9/11) 👇
Compared to other registers (speech, fiction, magazines, newspapers), academic writing contained a relatively lower proportion of measurements, and a higher proportion of ordinals (e.g., publication dates) and nominals (e.g., author contact information). (8/11) 👇

November 20, 2024 at 9:46 AM
Compared to other registers (speech, fiction, magazines, newspapers), academic writing contained a relatively lower proportion of measurements, and a higher proportion of ordinals (e.g., publication dates) and nominals (e.g., author contact information). (8/11) 👇
Only for cardinals did round numbers (operationalised as multiples of 5), which are associated with approximation, increase with magnitude. Thus, imprecise language use may reflect increasing imprecision of the approximate number system at higher magnitudes. (7/11) 👇

November 20, 2024 at 9:46 AM
Only for cardinals did round numbers (operationalised as multiples of 5), which are associated with approximation, increase with magnitude. Thus, imprecise language use may reflect increasing imprecision of the approximate number system at higher magnitudes. (7/11) 👇
In fact, cardinals were dominant for every order of magnitude except for 1,000–10,000, where ordinals dominated, which were mostly years, e.g., 1989, 2000. (5/11) 👇

November 20, 2024 at 9:46 AM
In fact, cardinals were dominant for every order of magnitude except for 1,000–10,000, where ordinals dominated, which were mostly years, e.g., 1989, 2000. (5/11) 👇
Cardinals were dominant—both 'pure' cardinals (sets) and measurements (scales)—followed by ordinals, and then nominals. Measurements were more common than pure cardinals. (3/11) 👇

November 20, 2024 at 9:46 AM
Cardinals were dominant—both 'pure' cardinals (sets) and measurements (scales)—followed by ordinals, and then nominals. Measurements were more common than pure cardinals. (3/11) 👇
We manually annotated 3,600 concordance lines containing numbers from 0 to 1 billion in the Corpus of Contemporary American English. We decided whether numbers were cardinal (quantifying), ordinal (ordering), or nominal (naming). (2/11) 👇

November 20, 2024 at 9:46 AM
We manually annotated 3,600 concordance lines containing numbers from 0 to 1 billion in the Corpus of Contemporary American English. We decided whether numbers were cardinal (quantifying), ordinal (ordering), or nominal (naming). (2/11) 👇
It's out—my new #openaccess paper with Bodo Winter in Cognitive Science (@cogscisociety.bsky.social) 🥳. Thread 👇 (1/11)
onlinelibrary.wiley.com/doi/10.1111/...
onlinelibrary.wiley.com/doi/10.1111/...

November 20, 2024 at 9:46 AM
It's out—my new #openaccess paper with Bodo Winter in Cognitive Science (@cogscisociety.bsky.social) 🥳. Thread 👇 (1/11)
onlinelibrary.wiley.com/doi/10.1111/...
onlinelibrary.wiley.com/doi/10.1111/...