




Kathy Garcia
@gkathy.bsky.social
Computational Cognitive Science PhD at Johns Hopkins with Leyla Isik
| BS @Stanford|
| 🔗 https://garciakathy.github.io/ |
| BS @Stanford|
| 🔗 https://garciakathy.github.io/ |
In follow-up experiments we show this model generalizes better to novel social tasks, and avoids catastrophic forgetting by preserving baseline on action recognition tasks.

October 3, 2025 at 1:48 PM
In follow-up experiments we show this model generalizes better to novel social tasks, and avoids catastrophic forgetting by preserving baseline on action recognition tasks.
After fine-tuning, the video model explains both captures more shared variance with language models AND captures more unique variance in human judgments, indicating it learned both language-like semantics and additional visual social nuances.

October 3, 2025 at 1:48 PM
After fine-tuning, the video model explains both captures more shared variance with language models AND captures more unique variance in human judgments, indicating it learned both language-like semantics and additional visual social nuances.
Despite the task being purely visual, caption embeddings from a language model predict human similarity better than any pretrained video model (e.g., mpnet-base-v2 > TimeSformer-base).

October 3, 2025 at 1:48 PM
Despite the task being purely visual, caption embeddings from a language model predict human similarity better than any pretrained video model (e.g., mpnet-base-v2 > TimeSformer-base).
🚨New preprint w/ @lisik.bsky.social!
Aligning Video Models with Human Social Judgments via Behavior-Guided Fine-Tuning
We introduce a ~49k triplet social video dataset, uncover a modality gap (language > video), and close via novel behavior-guided fine-tuning.
🔗 arxiv.org/abs/2510.01502
Aligning Video Models with Human Social Judgments via Behavior-Guided Fine-Tuning
We introduce a ~49k triplet social video dataset, uncover a modality gap (language > video), and close via novel behavior-guided fine-tuning.
🔗 arxiv.org/abs/2510.01502

October 3, 2025 at 1:48 PM
🚨New preprint w/ @lisik.bsky.social!
Aligning Video Models with Human Social Judgments via Behavior-Guided Fine-Tuning
We introduce a ~49k triplet social video dataset, uncover a modality gap (language > video), and close via novel behavior-guided fine-tuning.
🔗 arxiv.org/abs/2510.01502
Aligning Video Models with Human Social Judgments via Behavior-Guided Fine-Tuning
We introduce a ~49k triplet social video dataset, uncover a modality gap (language > video), and close via novel behavior-guided fine-tuning.
🔗 arxiv.org/abs/2510.01502
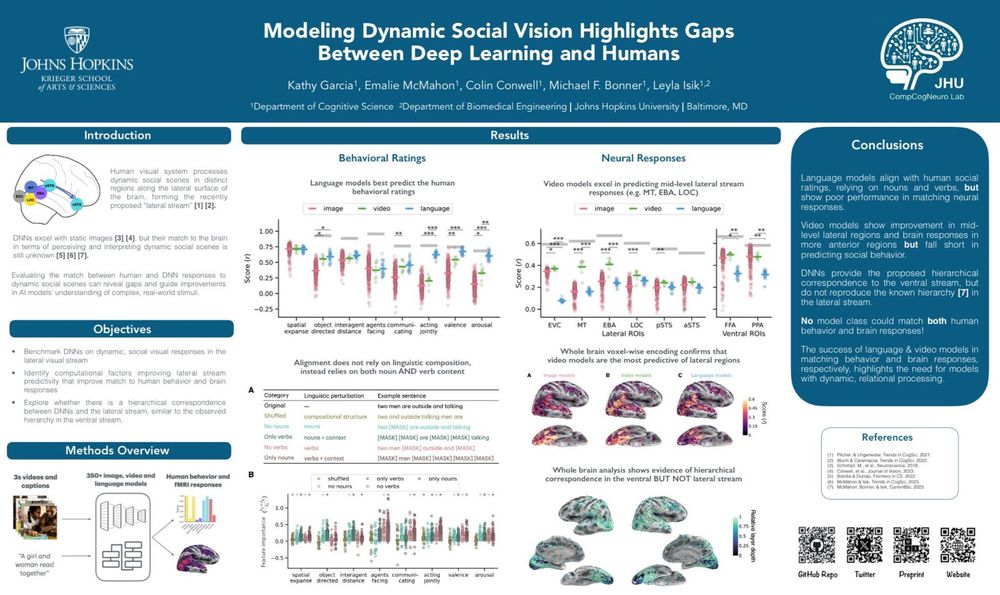
📹 While most model features (like architecture or training objective) did not affect performance, we saw a big advantage for video versus image models along the lateral stream. But no model tested could predict anterior lateral stream responses well. [5/6]

April 23, 2025 at 6:08 PM
📹 While most model features (like architecture or training objective) did not affect performance, we saw a big advantage for video versus image models along the lateral stream. But no model tested could predict anterior lateral stream responses well. [5/6]
🔍 Unlike visual scene features and ventral stream responses, vision models struggled to match human action and social interaction ratings, and did a poor job of predicting brain responses along the recently proposed lateral stream, specialized for social perception. [4/6]


April 23, 2025 at 6:08 PM
🔍 Unlike visual scene features and ventral stream responses, vision models struggled to match human action and social interaction ratings, and did a poor job of predicting brain responses along the recently proposed lateral stream, specialized for social perception. [4/6]
🧠 We benchmarked 350+ image, video, and language models against human behavioral and neural responses to dynamic, social videos. [3/6]

April 23, 2025 at 6:08 PM
🧠 We benchmarked 350+ image, video, and language models against human behavioral and neural responses to dynamic, social videos. [3/6]
🎥 Real-world vision is dynamic, involving complex social interactions. Current AI models provide a good match to humans in static scene vision, but how do they fare with dynamic, social stimuli? 🤔 We set out to explore this! [2/6]

April 23, 2025 at 6:08 PM
🎥 Real-world vision is dynamic, involving complex social interactions. Current AI models provide a good match to humans in static scene vision, but how do they fare with dynamic, social stimuli? 🤔 We set out to explore this! [2/6]
📢 Excited to announce our paper at #ICLR2025: “Modeling dynamic social vision highlights gaps between deep learning and humans”! w/ @emaliemcmahon.bsky.social, Colin Conwell, Mick Bonner, @lisik.bsky.social
📆 Thur, Apr, 24: 3:00-5:30 - Poster session 2 (#64)
📄 bit.ly/4jISKES%E2%8... [1/6]
📆 Thur, Apr, 24: 3:00-5:30 - Poster session 2 (#64)
📄 bit.ly/4jISKES%E2%8... [1/6]
April 23, 2025 at 6:08 PM
📢 Excited to announce our paper at #ICLR2025: “Modeling dynamic social vision highlights gaps between deep learning and humans”! w/ @emaliemcmahon.bsky.social, Colin Conwell, Mick Bonner, @lisik.bsky.social
📆 Thur, Apr, 24: 3:00-5:30 - Poster session 2 (#64)
📄 bit.ly/4jISKES%E2%8... [1/6]
📆 Thur, Apr, 24: 3:00-5:30 - Poster session 2 (#64)
📄 bit.ly/4jISKES%E2%8... [1/6]