



Thomas Leitner
@gettalong.bsky.social
(Open source) Software developer, creator of kramdown and HexaPDF, Sci-Fi fan.
You can't generally use an embedded font to add new content (because it usually misses parts in the font data structure; even if usable it might be missing characters).
Viewers work around this by loading the same font from the system paths.
With HexaPDF you need to specify the font yourself.
Viewers work around this by loading the same font from the system paths.
With HexaPDF you need to specify the font yourself.
September 23, 2025 at 3:49 PM
You can't generally use an embedded font to add new content (because it usually misses parts in the font data structure; even if usable it might be missing characters).
Viewers work around this by loading the same font from the system paths.
With HexaPDF you need to specify the font yourself.
Viewers work around this by loading the same font from the system paths.
With HexaPDF you need to specify the font yourself.
Yes!
But did you know that you can even parse arbitrary strings? 😆
Example: github.com/gettalong/he... (used for interleaving and handling file names and options).
But did you know that you can even parse arbitrary strings? 😆
Example: github.com/gettalong/he... (used for interleaving and handling file names and options).

hexapdf/lib/hexapdf/cli/merge.rb at master · gettalong/hexapdf
Versatile PDF creation and manipulation for Ruby. Contribute to gettalong/hexapdf development by creating an account on GitHub.
github.com
June 11, 2025 at 8:29 PM
Yes!
But did you know that you can even parse arbitrary strings? 😆
Example: github.com/gettalong/he... (used for interleaving and handling file names and options).
But did you know that you can even parse arbitrary strings? 😆
Example: github.com/gettalong/he... (used for interleaving and handling file names and options).
Maybe bind ALT-C to a command that sends CTRL-C? Or do something like this: unix.stackexchange.com/questions/78...

how to send keyboard strokes programmatically (like "sendkeys" in Windows) to a Wayland Linux window (KDE/GNOME)?
I'm writing a desktop automation software, which drives a GUI desktop, on linux. It works pretty well, but Wayland is blocking inter-window communication, especially when entering non-ASCII charact...
unix.stackexchange.com
June 10, 2025 at 2:38 PM
Maybe bind ALT-C to a command that sends CTRL-C? Or do something like this: unix.stackexchange.com/questions/78...
* KDE lets you configure which short-cut switches between applications (ALT-Tab) and which between their windows (Alt-`).
* The built-in KDE krunner application is sufficient as launcher for my needs.
* Clipboard history just works in KDE.
* Vim GUI -> gvim
* The built-in KDE krunner application is sufficient as launcher for my needs.
* Clipboard history just works in KDE.
* Vim GUI -> gvim
June 10, 2025 at 2:33 PM
* KDE lets you configure which short-cut switches between applications (ALT-Tab) and which between their windows (Alt-`).
* The built-in KDE krunner application is sufficient as launcher for my needs.
* Clipboard history just works in KDE.
* Vim GUI -> gvim
* The built-in KDE krunner application is sufficient as launcher for my needs.
* Clipboard history just works in KDE.
* Vim GUI -> gvim
If you are using KDE, you should be able to just configure this system-wide for all KDE based apps.

June 10, 2025 at 2:29 PM
If you are using KDE, you should be able to just configure this system-wide for all KDE based apps.
Or just use BreakVer www.taoensso.com/break-versio... and break things like before 😁

BreakVer | Taoensso
www.taoensso.com
June 9, 2025 at 11:08 PM
Or just use BreakVer www.taoensso.com/break-versio... and break things like before 😁
Thanks for the great meetup! And thanks to @hansschnedlitz.com for organizing it and doing the cool Ruby quiz!
June 7, 2025 at 9:45 AM
Thanks for the great meetup! And thanks to @hansschnedlitz.com for organizing it and doing the cool Ruby quiz!
And now the code is available at github.com/gettalong/ve...
It is not yet finished and not really polished etc. but already in a good state.
This will be the basis for still more easily creating PDF documents with HexaPDF 😀
It is not yet finished and not really polished etc. but already in a good state.
This will be the basis for still more easily creating PDF documents with HexaPDF 😀
GitHub - gettalong/versadok: Versatile document creation markup and library
Versatile document creation markup and library. Contribute to gettalong/versadok development by creating an account on GitHub.
github.com
June 2, 2025 at 9:38 PM
And now the code is available at github.com/gettalong/ve...
It is not yet finished and not really polished etc. but already in a good state.
This will be the basis for still more easily creating PDF documents with HexaPDF 😀
It is not yet finished and not really polished etc. but already in a good state.
This will be the basis for still more easily creating PDF documents with HexaPDF 😀
Worked now! And just released the new version - see hexapdf.gettalong.org/documentatio...
Changelog - HexaPDF
hexapdf.gettalong.org
April 24, 2025 at 5:35 AM
Worked now! And just released the new version - see hexapdf.gettalong.org/documentatio...
Array#[]=(e.g. ary[-10, 10] = EMPTY_ARRAY) won't create an additional array but is slower then Array#pop, so I'm staying with the latter.
March 17, 2025 at 10:26 PM
Array#[]=(e.g. ary[-10, 10] = EMPTY_ARRAY) won't create an additional array but is slower then Array#pop, so I'm staying with the latter.
Full benchmark info here gist.github.com/gettalong/b8...

Parsing into AST a file with kramdown vs versadok
Parsing into AST a file with kramdown vs versadok. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
March 12, 2025 at 10:34 PM
Full benchmark info here gist.github.com/gettalong/b8...
Ah, I forgot up that - thank you! You can further optimize it by using a constant empty array and doing `array[from, size] = EMPTY_ARRAY`.
I did a benchmark comparing pop, slice! and your method using benchmark-driver. Interestingly pop was faster even though it creates arrays.
I did a benchmark comparing pop, slice! and your method using benchmark-driver. Interestingly pop was faster even though it creates arrays.
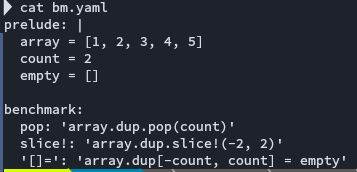
![Warming up --------------------------------------
pop 5.802M i/s - 6.040M times in 1.041085s (172.36ns/i, 187clocks/i)
slice! 4.235M i/s - 4.459M times in 1.052689s (236.11ns/i, 625clocks/i)
[]= 5.158M i/s - 5.168M times in 1.001836s (193.86ns/i, 211clocks/i)
Calculating -------------------------------------
pop 5.946M i/s - 17.406M times in 2.927538s (168.19ns/i, 426clocks/i)
slice! 4.100M i/s - 12.706M times in 3.098945s (243.90ns/i, 738clocks/i)
[]= 5.415M i/s - 15.475M times in 2.857926s (184.68ns/i, 808clocks/i)
Comparison:
pop: 5945557.8 i/s
[]=: 5414702.4 i/s - 1.10x slower
slice!: 4100124.2 i/s - 1.45x slower](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:nmyvn4engnv6gptvqkwoo2bn/bafkreidqmq24qx4mi2bb72vhmh2vb6i32qmddm36masl6twu5qbguk2mfm@jpeg)
March 11, 2025 at 10:41 PM
Ah, I forgot up that - thank you! You can further optimize it by using a constant empty array and doing `array[from, size] = EMPTY_ARRAY`.
I did a benchmark comparing pop, slice! and your method using benchmark-driver. Interestingly pop was faster even though it creates arrays.
I did a benchmark comparing pop, slice! and your method using benchmark-driver. Interestingly pop was faster even though it creates arrays.
Can also recommend weasyprint if you need HTML/CSS -> PDF.
If you want more quality and better conversion, a commercial solution based on PrincePDF is available via www.europdf.eu
And a heads up from me: There will be a markup-to-PDF pipeline for HexaPDF in the near future :-)
If you want more quality and better conversion, a commercial solution based on PrincePDF is available via www.europdf.eu
And a heads up from me: There will be a markup-to-PDF pipeline for HexaPDF in the near future :-)

EuroPDF - create PDFs from HTML, fast and secure!BASH_logo-transparent-bg-bw
www.europdf.eu
January 7, 2025 at 3:39 PM
Can also recommend weasyprint if you need HTML/CSS -> PDF.
If you want more quality and better conversion, a commercial solution based on PrincePDF is available via www.europdf.eu
And a heads up from me: There will be a markup-to-PDF pipeline for HexaPDF in the near future :-)
If you want more quality and better conversion, a commercial solution based on PrincePDF is available via www.europdf.eu
And a heads up from me: There will be a markup-to-PDF pipeline for HexaPDF in the near future :-)
I use unary + for normal UTF-8 encoded strings and "literal".b for binary ones.
December 14, 2024 at 2:52 PM
I use unary + for normal UTF-8 encoded strings and "literal".b for binary ones.
Yes, I also think so. When I wanted to formulate the versioning scheme for HexaPDF, I came across BreakVer 🙂
November 22, 2024 at 2:18 PM
Yes, I also think so. When I wanted to formulate the versioning scheme for HexaPDF, I came across BreakVer 🙂