



@gauravadlakha.bsky.social
Reposted

@simonwillison.net Hey, first of all, *thank you* for developing `llm` -- I use it frequently.
So much so that I developed a GTK frontend for it!
It's gotten to the point where perhaps it could be useful for others so I made it into a proper plugin. Feedback welcome!
github.com/icarito/gtk-...
So much so that I developed a GTK frontend for it!
It's gotten to the point where perhaps it could be useful for others so I made it into a proper plugin. Feedback welcome!
github.com/icarito/gtk-...

March 30, 2025 at 6:11 PM
@simonwillison.net Hey, first of all, *thank you* for developing `llm` -- I use it frequently.
So much so that I developed a GTK frontend for it!
It's gotten to the point where perhaps it could be useful for others so I made it into a proper plugin. Feedback welcome!
github.com/icarito/gtk-...
So much so that I developed a GTK frontend for it!
It's gotten to the point where perhaps it could be useful for others so I made it into a proper plugin. Feedback welcome!
github.com/icarito/gtk-...
Reposted


March 25, 2025 at 5:49 PM
I just completed "Mull It Over" - Day 3 - Advent of Code 2024 #AdventOfCode adventofcode.com/2024/day/3
Day 3 - Advent of Code 2024
adventofcode.com
December 31, 2024 at 6:05 AM
I just completed "Mull It Over" - Day 3 - Advent of Code 2024 #AdventOfCode adventofcode.com/2024/day/3
Reposted
You could have designed state of the art positional encoding by Christopher Fleetwood
This post walks you through the step-by-step discovery of state-of-the-art positional encoding in transformer models.
This post walks you through the step-by-step discovery of state-of-the-art positional encoding in transformer models.
December 24, 2024 at 4:13 PM
You could have designed state of the art positional encoding by Christopher Fleetwood
This post walks you through the step-by-step discovery of state-of-the-art positional encoding in transformer models.
This post walks you through the step-by-step discovery of state-of-the-art positional encoding in transformer models.
Reposted

There's also github.com/raphaelmansu...

GitHub - raphaelmansuy/code2prompt: Code2Prompt is a powerful command-line tool that simplifies the process of providing context to Large Language Models (LLMs) by generating a comprehensive Markdown ...
Code2Prompt is a powerful command-line tool that simplifies the process of providing context to Large Language Models (LLMs) by generating a comprehensive Markdown file containing the content of yo...
github.com
December 21, 2024 at 10:51 PM
There's also github.com/raphaelmansu...
Reposted

Quickly turn a GitHub repository into text for LLMs with Gitingest ⚡️ Replace "hub" with "ingest" in any GitHub URL for a text version of the codebase.
gitingest.com
github.com/cyclotruc/gi...
gitingest.com
github.com/cyclotruc/gi...
December 21, 2024 at 8:58 PM
Quickly turn a GitHub repository into text for LLMs with Gitingest ⚡️ Replace "hub" with "ingest" in any GitHub URL for a text version of the codebase.
gitingest.com
github.com/cyclotruc/gi...
gitingest.com
github.com/cyclotruc/gi...
Reposted

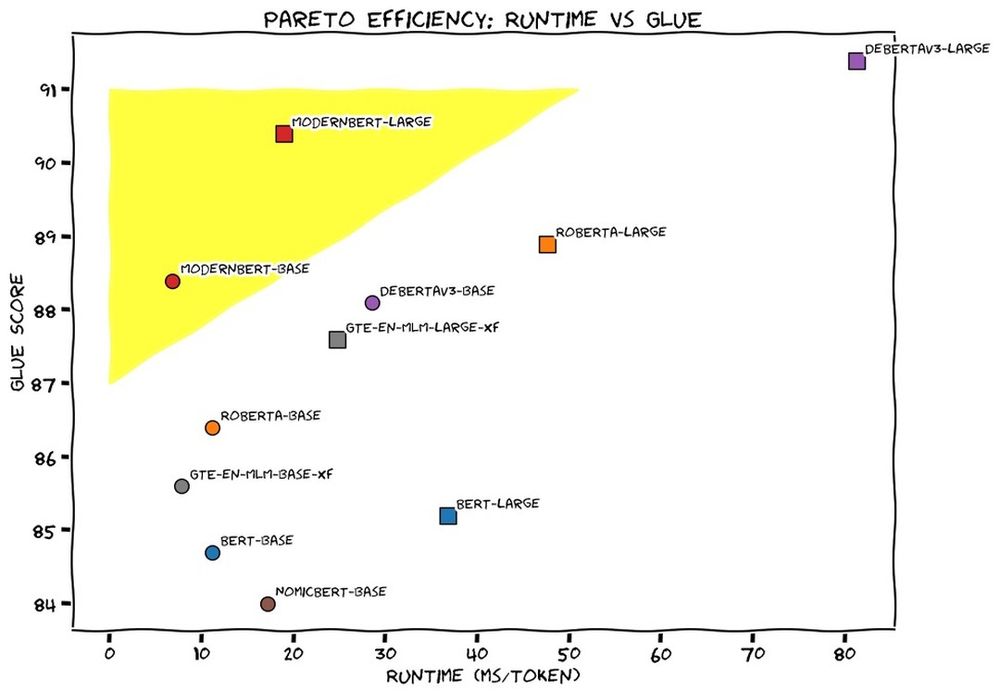
This week we released ModernBERT, the first encoder to reach SOTA on most common benchmarks across language understanding, retrieval, and code, while running twice as fast as DeBERTaV3 on short context and three times faster than NomicBERT & GTE on long context.
December 22, 2024 at 6:12 AM
This week we released ModernBERT, the first encoder to reach SOTA on most common benchmarks across language understanding, retrieval, and code, while running twice as fast as DeBERTaV3 on short context and three times faster than NomicBERT & GTE on long context.
Reposted

New LLM Eval Office Hours, I discuss the importance of doing error analysis before jumping into metrics and tests
Links to notes in the YT description
youtu.be/ZEvXvyY17Ys?...
Links to notes in the YT description
youtu.be/ZEvXvyY17Ys?...

LLM Eval Office Hours #3: The Importance Of Starting With Error Analysis
YouTube video by Hamel Husain
youtu.be
December 22, 2024 at 1:10 AM
New LLM Eval Office Hours, I discuss the importance of doing error analysis before jumping into metrics and tests
Links to notes in the YT description
youtu.be/ZEvXvyY17Ys?...
Links to notes in the YT description
youtu.be/ZEvXvyY17Ys?...
Reposted

This is pretty damn nifty! @hamel.bsky.social @projectjupyter.bsky.social
#datascience #jupyternotebooks
www.answer.ai/posts/2024-1...
#datascience #jupyternotebooks
www.answer.ai/posts/2024-1...

nbsanity - Share Notebooks as Polished Web Pages in Seconds – Answer.AI
Transform your GitHub Jupyter notebooks into beautiful, readable web pages with a single URL change. No setup required.
www.answer.ai
December 20, 2024 at 3:33 PM
This is pretty damn nifty! @hamel.bsky.social @projectjupyter.bsky.social
#datascience #jupyternotebooks
www.answer.ai/posts/2024-1...
#datascience #jupyternotebooks
www.answer.ai/posts/2024-1...
Reposted

Post credits easter egg:
Hey did you wonder what if we trained a bigger model? Where would that take us?
Yeah, us too.
So we're gonna train a "huge" version of this model in 2025. We might need to change the y-axis on this graph…
Hey did you wonder what if we trained a bigger model? Where would that take us?
Yeah, us too.
So we're gonna train a "huge" version of this model in 2025. We might need to change the y-axis on this graph…

December 19, 2024 at 4:45 PM
Post credits easter egg:
Hey did you wonder what if we trained a bigger model? Where would that take us?
Yeah, us too.
So we're gonna train a "huge" version of this model in 2025. We might need to change the y-axis on this graph…
Hey did you wonder what if we trained a bigger model? Where would that take us?
Yeah, us too.
So we're gonna train a "huge" version of this model in 2025. We might need to change the y-axis on this graph…
Reposted
And a special shoutout to PhD student @jackcookjack for his work on eval implementation, which is an often under-appreciated but vitally important area.
(Sorry for using Twitter names, but I don't know everyone's bsky IDs…)
(Sorry for using Twitter names, but I don't know everyone's bsky IDs…)
December 19, 2024 at 4:45 PM
And a special shoutout to PhD student @jackcookjack for his work on eval implementation, which is an often under-appreciated but vitally important area.
(Sorry for using Twitter names, but I don't know everyone's bsky IDs…)
(Sorry for using Twitter names, but I don't know everyone's bsky IDs…)
Reposted
I'll get straight to the point.
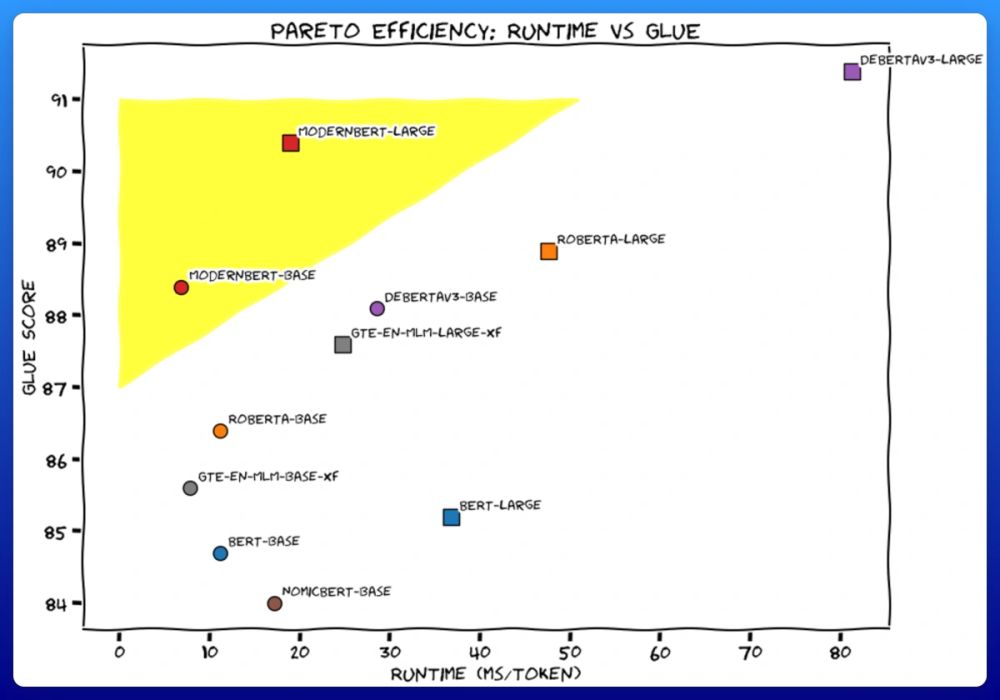
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
December 19, 2024 at 4:45 PM
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
Reposted

Our team at @specstory.com launched our very first product iteration today.
What is it? An extension for @cursor_ai that allows you to save and share your composer and chat history.
Give it a try at marketplace.visualstudio.com/items?itemNa... and let us know what you think!
What is it? An extension for @cursor_ai that allows you to save and share your composer and chat history.
Give it a try at marketplace.visualstudio.com/items?itemNa... and let us know what you think!

December 17, 2024 at 12:12 AM
Our team at @specstory.com launched our very first product iteration today.
What is it? An extension for @cursor_ai that allows you to save and share your composer and chat history.
Give it a try at marketplace.visualstudio.com/items?itemNa... and let us know what you think!
What is it? An extension for @cursor_ai that allows you to save and share your composer and chat history.
Give it a try at marketplace.visualstudio.com/items?itemNa... and let us know what you think!
Reposted

I’m releasing a series of experiment to enhance Retrieval augmented generation using attention scores. colab.research.google.com/drive/1HEUqy... Basic idea is to leverage the internal reading process, as the model goes back and forth to the sources to find information and potential quotes.

December 15, 2024 at 2:35 PM
I’m releasing a series of experiment to enhance Retrieval augmented generation using attention scores. colab.research.google.com/drive/1HEUqy... Basic idea is to leverage the internal reading process, as the model goes back and forth to the sources to find information and potential quotes.
Reposted

If you're interested in @howard.fm's llms.txt (answer.ai/posts/2024-0...) you'll find my post extra interesting. All the demos are of applying Roaming RAG over llms.txt files.
Tell me what you think!
Tell me what you think!
Tired of wrestling with complex RAG pipelines?
🚀 Enter Roaming RAG: a simpler way to make your LLMs find answers in well-structured docs. No vector databases, no headaches—just rich, structured context.
👉 Read how it works: arcturus-labs.com/blog/2024/11...
🚀 Enter Roaming RAG: a simpler way to make your LLMs find answers in well-structured docs. No vector databases, no headaches—just rich, structured context.
👉 Read how it works: arcturus-labs.com/blog/2024/11...
Roaming RAG – Make the Model Find the Answers - Arcturus Labs
Roaming RAG offers a fresh take on Retrieval-Augmented Generation, letting LLMs navigate well-structured documents like a human—exploring outlines and diving into sections to find answers. Forget comp...
arcturus-labs.com
December 6, 2024 at 12:34 AM
If you're interested in @howard.fm's llms.txt (answer.ai/posts/2024-0...) you'll find my post extra interesting. All the demos are of applying Roaming RAG over llms.txt files.
Tell me what you think!
Tell me what you think!