




Gabriel Peyré
@gabrielpeyre.bsky.social
To meditate while resting on the beach...
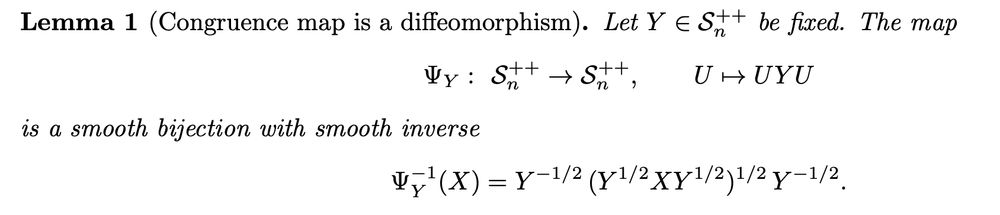
August 9, 2025 at 11:15 AM
To meditate while resting on the beach...
Le prochain Data Science Colloquium à l'ENS, jeudi 12 juin, sera donné par David Louapre d'Ubisoft, "What modern AI and neuroscience can bring to non-playing characters in video games". David c'est bien sûr également le vulgarisateur scientifique de www.youtube.com/scienceetonn...

June 4, 2025 at 7:00 AM
Le prochain Data Science Colloquium à l'ENS, jeudi 12 juin, sera donné par David Louapre d'Ubisoft, "What modern AI and neuroscience can bring to non-playing characters in video games". David c'est bien sûr également le vulgarisateur scientifique de www.youtube.com/scienceetonn...
If one of the two distributions is an isotropic Gaussian, then flow matching is equivalent to a diffusion model. This is known as Tweedie's formula. In particular, the vector field is a gradient vector, as in optimal transport. speakerdeck.com/gpeyre/compu...

May 31, 2025 at 10:16 AM
If one of the two distributions is an isotropic Gaussian, then flow matching is equivalent to a diffusion model. This is known as Tweedie's formula. In particular, the vector field is a gradient vector, as in optimal transport. speakerdeck.com/gpeyre/compu...
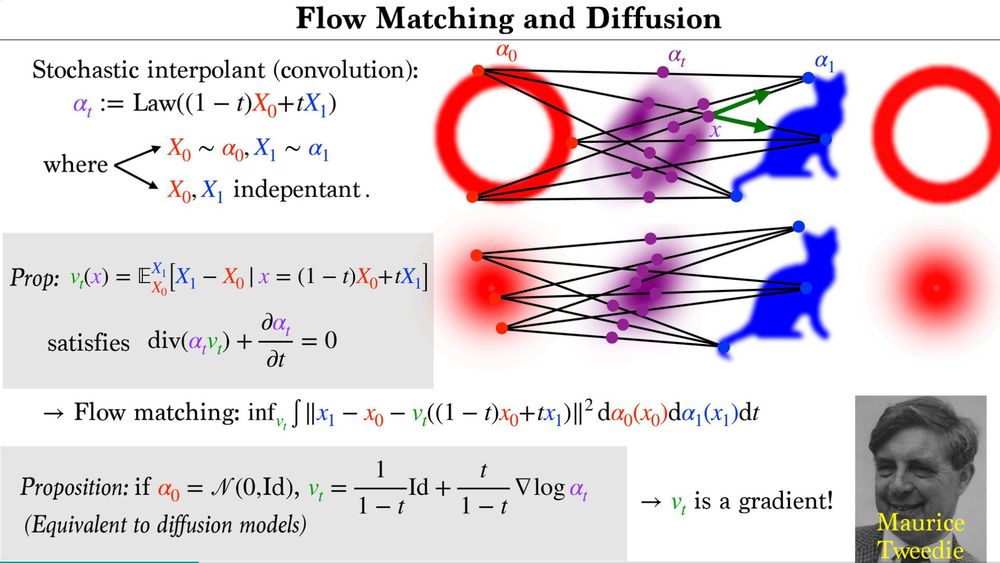
I have cleaned up the notebooks for my course on Optimal Transport for Machine Learners and added links to the slides and lecture notes. github.com/gpeyre/ot4ml
May 25, 2025 at 9:12 AM
I have cleaned up the notebooks for my course on Optimal Transport for Machine Learners and added links to the slides and lecture notes. github.com/gpeyre/ot4ml
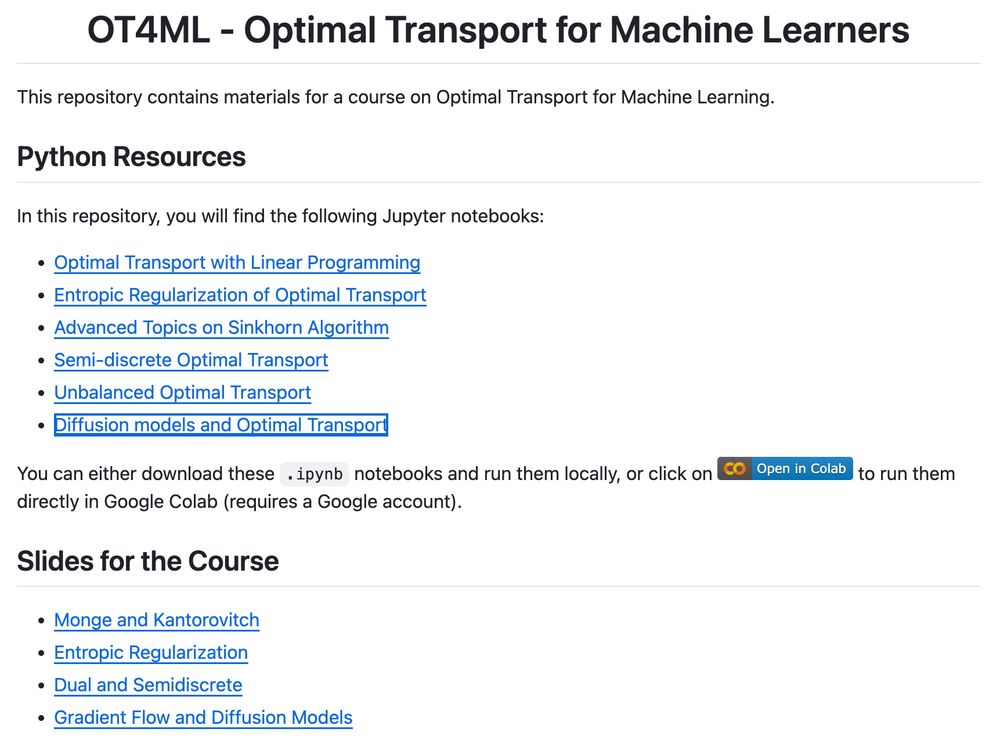
I have updated my slides on the maths of AI by an optimal pairing between AI and maths researchers ... speakerdeck.com/gpeyre/the-m...
May 20, 2025 at 11:21 AM
I have updated my slides on the maths of AI by an optimal pairing between AI and maths researchers ... speakerdeck.com/gpeyre/the-m...
Mon article sur les maths de l’IA est paru dans la gazette de la smf smf.emath.fr/publications...
La version en anglais est sur arxiv
arxiv.org/abs/2501.10465
La version en anglais est sur arxiv
arxiv.org/abs/2501.10465

May 16, 2025 at 10:35 PM
Mon article sur les maths de l’IA est paru dans la gazette de la smf smf.emath.fr/publications...
La version en anglais est sur arxiv
arxiv.org/abs/2501.10465
La version en anglais est sur arxiv
arxiv.org/abs/2501.10465
Futur best seller!

March 28, 2025 at 8:08 AM
Futur best seller!
@vickykalogeiton.bsky.social and @davidpicard.bsky.social updating live there slides to quote my talk just before ... next level presentation!


February 7, 2025 at 11:57 AM
@vickykalogeiton.bsky.social and @davidpicard.bsky.social updating live there slides to quote my talk just before ... next level presentation!
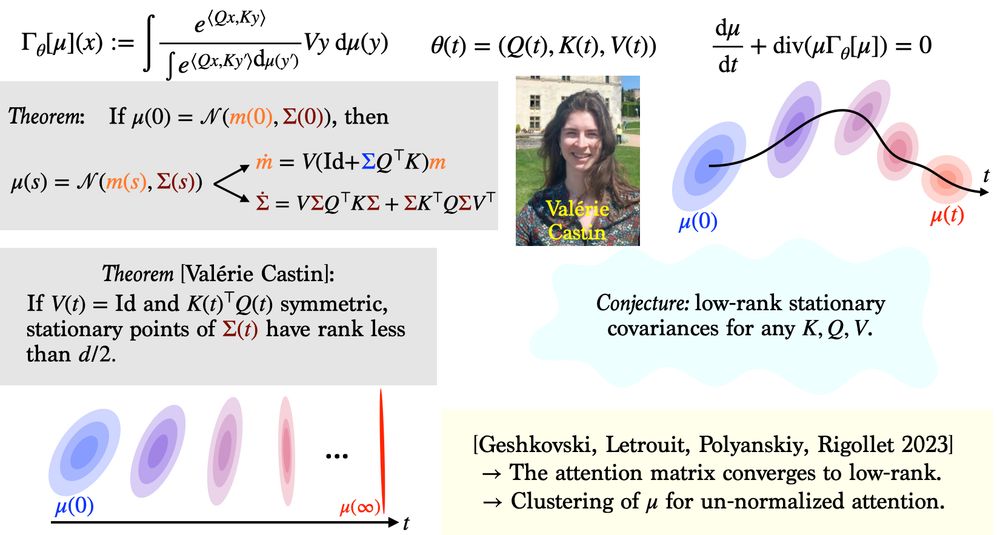
A cute result from Valérie’s work is that Gaussian distributions remain closed under evolution by attentions layers, allowing one to study an ODE in the (mean, covariance) space. In particular, this enables the analysis of the “clustering of tokens” toward low-rank covariances.
February 1, 2025 at 9:54 AM
A cute result from Valérie’s work is that Gaussian distributions remain closed under evolution by attentions layers, allowing one to study an ODE in the (mean, covariance) space. In particular, this enables the analysis of the “clustering of tokens” toward low-rank covariances.
This review paper by @guillaume-garrigos.com on SGD-related algorithms is a fantastic resource, offering elegant, self-contained, and concise proofs in a single, accessible reference. arxiv.org/pdf/2301.11235

January 29, 2025 at 4:15 PM
This review paper by @guillaume-garrigos.com on SGD-related algorithms is a fantastic resource, offering elegant, self-contained, and concise proofs in a single, accessible reference. arxiv.org/pdf/2301.11235
The Mathematics of Artificial Intelligence: In this introductory and highly subjective survey, aimed at a general mathematical audience, I showcase some key theoretical concepts underlying recent advancements in machine learning. arxiv.org/abs/2501.10465

January 22, 2025 at 9:11 AM
The Mathematics of Artificial Intelligence: In this introductory and highly subjective survey, aimed at a general mathematical audience, I showcase some key theoretical concepts underlying recent advancements in machine learning. arxiv.org/abs/2501.10465
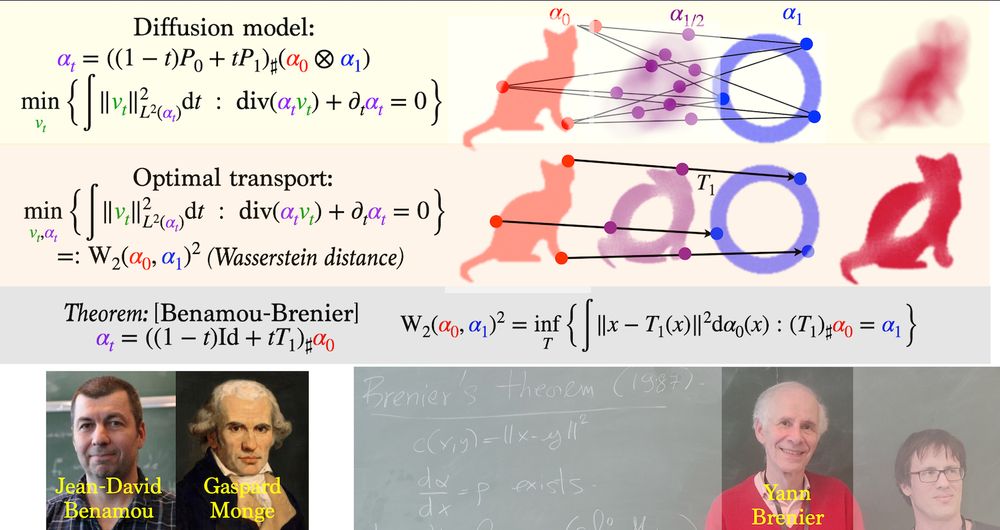
Slides for a general introduction to the use of Optimal Transport methods in learning, with an emphasis on diffusion models, flow matching, training 2 layers neural networks and deep transformers. speakerdeck.com/gpeyre/optim...
January 15, 2025 at 7:08 PM
Slides for a general introduction to the use of Optimal Transport methods in learning, with an emphasis on diffusion models, flow matching, training 2 layers neural networks and deep transformers. speakerdeck.com/gpeyre/optim...
In 1988, John Lafferty introduced what he called the “density manifold,” which corresponds to the Wasserstein metric later studied in depth by Felix Otto in the context of Optimal Transport gradient flows. (Yes, he also later co-developed Conditional Random Fields!) www.jstor.org/stable/2000885

December 14, 2024 at 12:39 PM
In 1988, John Lafferty introduced what he called the “density manifold,” which corresponds to the Wasserstein metric later studied in depth by Felix Otto in the context of Optimal Transport gradient flows. (Yes, he also later co-developed Conditional Random Fields!) www.jstor.org/stable/2000885
This ties into what’s discussed in the section “Fixing up the step functions” of this excellent post:
neuralnetworksanddeeplearning.com/chap4.html.
However, rigorously proving it as Hornik does is IMHO not straightforward.
neuralnetworksanddeeplearning.com/chap4.html.
However, rigorously proving it as Hornik does is IMHO not straightforward.

December 10, 2024 at 6:57 PM
This ties into what’s discussed in the section “Fixing up the step functions” of this excellent post:
neuralnetworksanddeeplearning.com/chap4.html.
However, rigorously proving it as Hornik does is IMHO not straightforward.
neuralnetworksanddeeplearning.com/chap4.html.
However, rigorously proving it as Hornik does is IMHO not straightforward.
This paper by Hornik et al demonstrates the *uniform* approximation universality of 2-layer MLPs with sigmoid activation functions, leveraging that sinusoids can approximate any function through Fourier expansion.
www.cs.cmu.edu/~epxing/Clas...
www.cs.cmu.edu/~epxing/Clas...

December 10, 2024 at 6:57 PM
This paper by Hornik et al demonstrates the *uniform* approximation universality of 2-layer MLPs with sigmoid activation functions, leveraging that sinusoids can approximate any function through Fourier expansion.
www.cs.cmu.edu/~epxing/Clas...
www.cs.cmu.edu/~epxing/Clas...
Sorry for the initial un-animated cat, now corrected!
December 4, 2024 at 5:28 PM
Sorry for the initial un-animated cat, now corrected!
Optimal transport, convolution, and averaging define interpolations between probability distributions. One can find vector fields advecting particles that match these interpolations. They are the Benamou-Brenier, flow-matching, and Dacorogna-Moser fields.

December 4, 2024 at 1:55 PM
Optimal transport, convolution, and averaging define interpolations between probability distributions. One can find vector fields advecting particles that match these interpolations. They are the Benamou-Brenier, flow-matching, and Dacorogna-Moser fields.
I have updated my course notes on Optimal Transport with a new Chapter 9 on Wasserstein flows. It includes 3 illustrative applications: training a 2-layer MLP, deep transformers, and flow-matching generative models. You can access it here: mathematical-tours.github.io/book-sources...

December 4, 2024 at 8:11 AM
I have updated my course notes on Optimal Transport with a new Chapter 9 on Wasserstein flows. It includes 3 illustrative applications: training a 2-layer MLP, deep transformers, and flow-matching generative models. You can access it here: mathematical-tours.github.io/book-sources...
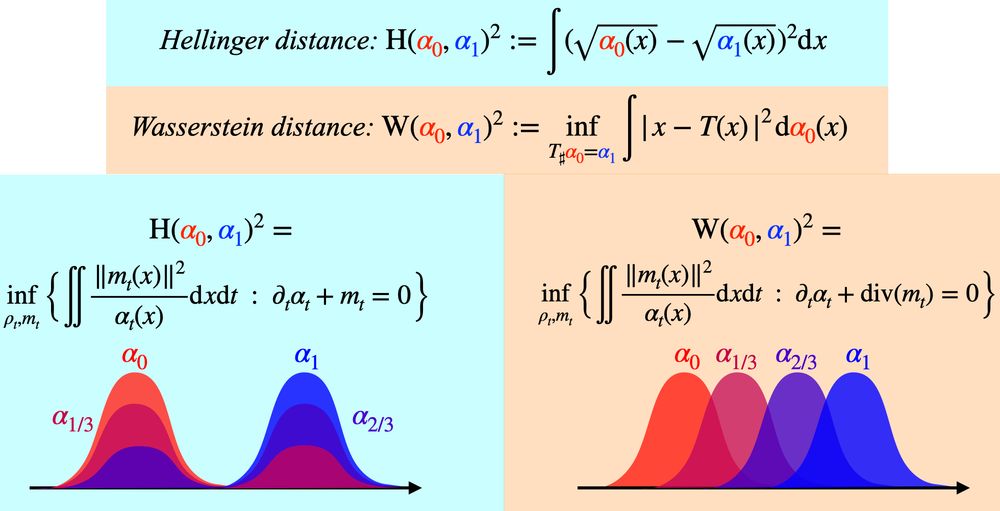
Hellinger and Wasserstein are the two main geodesic distances on probability distributions. While both minimize the same energy, they differ in their interpolation methods: Hellinger focuses on density, whereas Wasserstein emphasizes position displacements.
December 3, 2024 at 5:16 PM
Hellinger and Wasserstein are the two main geodesic distances on probability distributions. While both minimize the same energy, they differ in their interpolation methods: Hellinger focuses on density, whereas Wasserstein emphasizes position displacements.
Optimal transport computes an interpolation between two distributions using an optimal coupling. Flow matching, on the other hand, uses a simpler “independent” coupling, which is the product of the marginals.
December 2, 2024 at 12:46 PM
Optimal transport computes an interpolation between two distributions using an optimal coupling. Flow matching, on the other hand, uses a simpler “independent” coupling, which is the product of the marginals.
A vizualization of the diffusion map to sample 3 Dirac masses (since here the configuration is nearly symmetric, it is very close to the optimal transport).

November 30, 2024 at 4:30 PM
A vizualization of the diffusion map to sample 3 Dirac masses (since here the configuration is nearly symmetric, it is very close to the optimal transport).
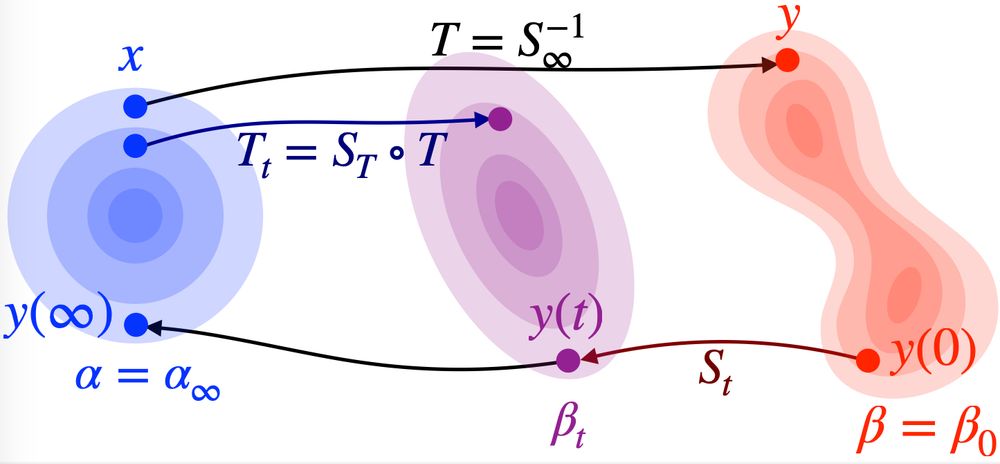
I wrote a summary of the main ingredients of the neat proof by Hugo Lavenant that diffusion models do not generally define optimal transport. github.com/mathematical...
November 30, 2024 at 8:35 AM
I wrote a summary of the main ingredients of the neat proof by Hugo Lavenant that diffusion models do not generally define optimal transport. github.com/mathematical...