




Franck Iutzeler
@franck-iutzeler.bsky.social
Professor of applied mathematics at the University of Toulouse
Website: www.iutzeler.org
Website: www.iutzeler.org
Paper ( #ICML 2025 ) arxiv.org/abs/2503.16398
See also our previous work the invariant distribution of SGD ( #ICML 2024 ) arxiv.org/abs/2406.09241
See also our previous work the invariant distribution of SGD ( #ICML 2024 ) arxiv.org/abs/2406.09241
June 18, 2025 at 1:59 PM
Paper ( #ICML 2025 ) arxiv.org/abs/2503.16398
See also our previous work the invariant distribution of SGD ( #ICML 2024 ) arxiv.org/abs/2406.09241
See also our previous work the invariant distribution of SGD ( #ICML 2024 ) arxiv.org/abs/2406.09241
🔧 Technical approach: Building on our previous paper on the invariant measures of SGD, we leverage large deviations theory (Freidlin-Wentzell) to obtain matching upper/lower bounds on the hitting time to a neighborhood of the global minima.
June 18, 2025 at 1:59 PM
🔧 Technical approach: Building on our previous paper on the invariant measures of SGD, we leverage large deviations theory (Freidlin-Wentzell) to obtain matching upper/lower bounds on the hitting time to a neighborhood of the global minima.
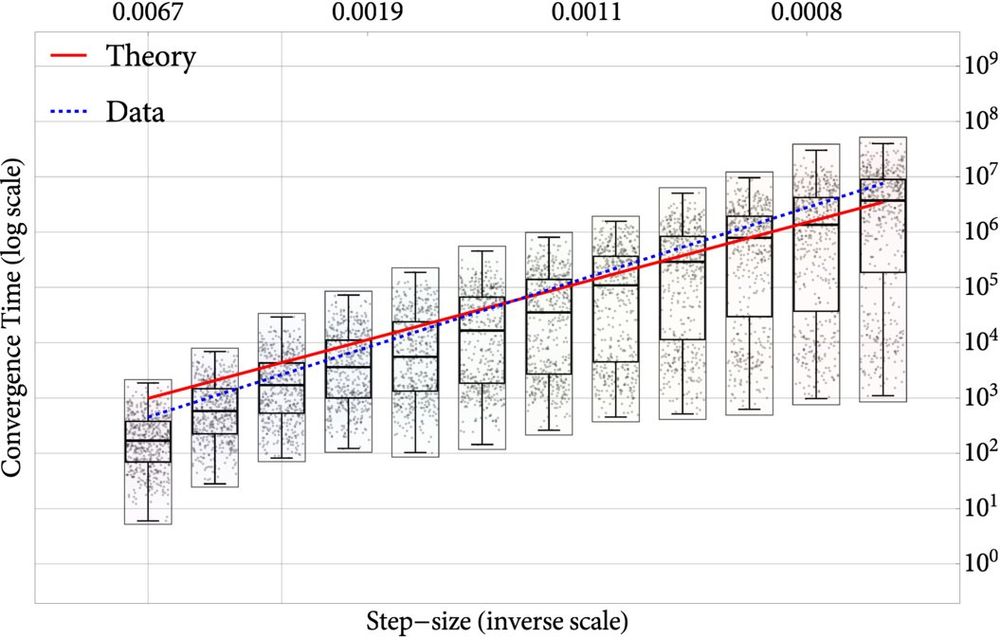
📊 Here's how it looks on a standard non-convex example. We plot the log of the global convergence time as a function of the step-size. Our theory predicts a linear relationship and the slope of this line (red). R² = 0.97 for theory vs 0.99 for data fit ✔️
June 18, 2025 at 1:59 PM
📊 Here's how it looks on a standard non-convex example. We plot the log of the global convergence time as a function of the step-size. Our theory predicts a linear relationship and the slope of this line (red). R² = 0.97 for theory vs 0.99 for data fit ✔️
🔗 Our quantity E captures the interplay between geometry and SGD convergence, enabling transfer from loss landscape literature to convergence guarantees.
💡 Key consequence: Our results explain how the favorable properties of the landscape of NNs drive SGD's convergence
💡 Key consequence: Our results explain how the favorable properties of the landscape of NNs drive SGD's convergence
June 18, 2025 at 1:59 PM
🔗 Our quantity E captures the interplay between geometry and SGD convergence, enabling transfer from loss landscape literature to convergence guarantees.
💡 Key consequence: Our results explain how the favorable properties of the landscape of NNs drive SGD's convergence
💡 Key consequence: Our results explain how the favorable properties of the landscape of NNs drive SGD's convergence
🌄 The key quantity E is a geometric measure of what makes optimization hard, eg:
• When f has no spurious minima → E = 0 → sub-exponential convergence
• Even more: E can be controlled by the depth of spurious minima - shallow minima → small E → fast convergence 🚀
• When f has no spurious minima → E = 0 → sub-exponential convergence
• Even more: E can be controlled by the depth of spurious minima - shallow minima → small E → fast convergence 🚀
June 18, 2025 at 1:59 PM
🌄 The key quantity E is a geometric measure of what makes optimization hard, eg:
• When f has no spurious minima → E = 0 → sub-exponential convergence
• Even more: E can be controlled by the depth of spurious minima - shallow minima → small E → fast convergence 🚀
• When f has no spurious minima → E = 0 → sub-exponential convergence
• Even more: E can be controlled by the depth of spurious minima - shallow minima → small E → fast convergence 🚀
🔑 Main result: we find that the mean time τ to hit a global minimum starting from x is
𝔼[τ] ≈ exp(E(x) / η)
where:
• η = (constant) step size of SGD
• E(x) = energy-like function that captures the geometry of the non-convex landscape and the statistics of the noise
𝔼[τ] ≈ exp(E(x) / η)
where:
• η = (constant) step size of SGD
• E(x) = energy-like function that captures the geometry of the non-convex landscape and the statistics of the noise
June 18, 2025 at 1:59 PM
🔑 Main result: we find that the mean time τ to hit a global minimum starting from x is
𝔼[τ] ≈ exp(E(x) / η)
where:
• η = (constant) step size of SGD
• E(x) = energy-like function that captures the geometry of the non-convex landscape and the statistics of the noise
𝔼[τ] ≈ exp(E(x) / η)
where:
• η = (constant) step size of SGD
• E(x) = energy-like function that captures the geometry of the non-convex landscape and the statistics of the noise
🎯 The challenge: Most SGD theory gives local guarantees or requires special structure (overparameterization, specific models, etc).
We ask: for ANY smooth non-convex function, how much time does SGD need to reach the global optimum (escaping all spurious minima along the way)?
We ask: for ANY smooth non-convex function, how much time does SGD need to reach the global optimum (escaping all spurious minima along the way)?
June 18, 2025 at 1:59 PM
🎯 The challenge: Most SGD theory gives local guarantees or requires special structure (overparameterization, specific models, etc).
We ask: for ANY smooth non-convex function, how much time does SGD need to reach the global optimum (escaping all spurious minima along the way)?
We ask: for ANY smooth non-convex function, how much time does SGD need to reach the global optimum (escaping all spurious minima along the way)?
Reposted by Franck Iutzeler

lets using fucking git plz
May 14, 2025 at 12:14 PM
lets using fucking git plz