



Flaviu Cipcigan
@flaviucipcigan.bsky.social
Building AIs for scientific discovery. Discovered antibiotics and materials for carbon capture. Tango dancer. See more at flaviucipcigan.com. Opinions my own.
Super interesting application of program search
Goals are mapped to programs which are embedded in a latent space.
A fitness metric is assigned to the programs and program search is done to synthesise new human-like goals.
Goals are mapped to programs which are embedded in a latent space.
A fitness metric is assigned to the programs and program search is done to synthesise new human-like goals.

February 22, 2025 at 11:53 AM
Super interesting application of program search
Goals are mapped to programs which are embedded in a latent space.
A fitness metric is assigned to the programs and program search is done to synthesise new human-like goals.
Goals are mapped to programs which are embedded in a latent space.
A fitness metric is assigned to the programs and program search is done to synthesise new human-like goals.
Wanna try to guess which of those gets parsed as a string and which as a number? Answer in alt text.
YAML parsing in python is weird.
YAML parsing in python is weird.
![{'lol': ['5.0E6',
'5.0e6',
'5.E6',
'5.e6',
'5E6',
'5e6',
5e-06,
5e-06,
5e-06,
5e-06,
'5E-6',
'5e-6',
5000000.0,
5000000.0,
5000000.0,
5000000.0,
'5E+6',
'5e+6']}](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:ndszovlqz5net2hyllfww2yn/bafkreicua2n2os5acybolmps4wwgr35vh5l3fo2zisz3t3bhqs5efdq7mq@jpeg)
February 17, 2025 at 4:49 PM
Wanna try to guess which of those gets parsed as a string and which as a number? Answer in alt text.
YAML parsing in python is weird.
YAML parsing in python is weird.
Interesting idea to generate responses using diffusion rather than left-to-right auto-regressive models
February 17, 2025 at 12:31 PM
Interesting idea to generate responses using diffusion rather than left-to-right auto-regressive models
Supercomputers - large computer clusters - allow you to work a number of years ahead.
Creating the GUI at PARC seemed like a "waste of FLOPs" but revolutionized computing.
Creating the GUI at PARC seemed like a "waste of FLOPs" but revolutionized computing.

February 15, 2025 at 12:56 PM
Supercomputers - large computer clusters - allow you to work a number of years ahead.
Creating the GUI at PARC seemed like a "waste of FLOPs" but revolutionized computing.
Creating the GUI at PARC seemed like a "waste of FLOPs" but revolutionized computing.
Neat idea! Fine-tuning using majority voting and length filtering generalises a model's capabilities.
Models generalise to slightly harder versions of a problem, and the correct answers are used to bootstrap the next model and the next one and so on.
Models generalise to slightly harder versions of a problem, and the correct answers are used to bootstrap the next model and the next one and so on.

February 13, 2025 at 1:17 PM
Neat idea! Fine-tuning using majority voting and length filtering generalises a model's capabilities.
Models generalise to slightly harder versions of a problem, and the correct answers are used to bootstrap the next model and the next one and so on.
Models generalise to slightly harder versions of a problem, and the correct answers are used to bootstrap the next model and the next one and so on.
Turning the temperature up using R1
Starting to think
gibberish gibberish gibberish
Focus again. Calm up.
🤣
Starting to think
gibberish gibberish gibberish
Focus again. Calm up.
🤣

January 25, 2025 at 6:44 PM
Turning the temperature up using R1
Starting to think
gibberish gibberish gibberish
Focus again. Calm up.
🤣
Starting to think
gibberish gibberish gibberish
Focus again. Calm up.
🤣
Hm, using reasoning models really feels qualitatively different (using @openrouter.bsky.social for inference).
It's fun to see these aha moments and it'd be interesting to understand whether their presence helps.
It's fun to see these aha moments and it'd be interesting to understand whether their presence helps.


January 25, 2025 at 12:26 PM
Hm, using reasoning models really feels qualitatively different (using @openrouter.bsky.social for inference).
It's fun to see these aha moments and it'd be interesting to understand whether their presence helps.
It's fun to see these aha moments and it'd be interesting to understand whether their presence helps.
R1 rewards the model when it uses the correct thinking tags.
At least in that case, it looks like <thinking> is simply a consequence of RL.
At least in that case, it looks like <thinking> is simply a consequence of RL.

January 22, 2025 at 4:34 PM
R1 rewards the model when it uses the correct thinking tags.
At least in that case, it looks like <thinking> is simply a consequence of RL.
At least in that case, it looks like <thinking> is simply a consequence of RL.
Hm, seems that a system prompt telling Claude to "think before answering" is what should create more chains of thoughts.

January 22, 2025 at 4:14 PM
Hm, seems that a system prompt telling Claude to "think before answering" is what should create more chains of thoughts.
Huh, interesting, Claude 3.5 sonnet seems to do hidden CoT in the app.
Could not reproduce with the API tho.
Could not reproduce with the API tho.

January 22, 2025 at 4:03 PM
Huh, interesting, Claude 3.5 sonnet seems to do hidden CoT in the app.
Could not reproduce with the API tho.
Could not reproduce with the API tho.
1.5B distilled model beats 4o and Claude 3.5 Sonnet on hard math problems

January 20, 2025 at 6:33 PM
1.5B distilled model beats 4o and Claude 3.5 Sonnet on hard math problems
If the benchmarks reproduce, seems that even 7B distilled models from R1 outputs beat 4o while even a 1.5B model gets close.
No wonder that OAI keeps the chains of thoughts private!
No wonder that OAI keeps the chains of thoughts private!

January 20, 2025 at 2:25 PM
If the benchmarks reproduce, seems that even 7B distilled models from R1 outputs beat 4o while even a 1.5B model gets close.
No wonder that OAI keeps the chains of thoughts private!
No wonder that OAI keeps the chains of thoughts private!
These "wait, let's go back" moments are also emergent.

January 20, 2025 at 2:11 PM
These "wait, let's go back" moments are also emergent.
Chain of thought gets longer and longer the longer the RL algo runs.

January 20, 2025 at 2:11 PM
Chain of thought gets longer and longer the longer the RL algo runs.
Just doing RL with a reward related to the correctness signal given by a verifier seems to be enough.
Another example of "the model just wants to learn". No need for fancy search - looks like the model will learn the right algo in the chain of thought.
Another example of "the model just wants to learn". No need for fancy search - looks like the model will learn the right algo in the chain of thought.

January 20, 2025 at 2:11 PM
Just doing RL with a reward related to the correctness signal given by a verifier seems to be enough.
Another example of "the model just wants to learn". No need for fancy search - looks like the model will learn the right algo in the chain of thought.
Another example of "the model just wants to learn". No need for fancy search - looks like the model will learn the right algo in the chain of thought.
Interesting result re evolutionary algos for inference time search

January 20, 2025 at 11:45 AM
Interesting result re evolutionary algos for inference time search
NVIDIA's recent Project Digits is in the same category, with 1 FP4 PFLOPS (0.25 FP16 PFLOPS) and 128 GB unified memory at - hopefully - $3000.
Another important feature is NCCL, which is fast inter-GPU communication. Thus, multiple boxes can be used for inference.
Another important feature is NCCL, which is fast inter-GPU communication. Thus, multiple boxes can be used for inference.

January 7, 2025 at 2:50 PM
NVIDIA's recent Project Digits is in the same category, with 1 FP4 PFLOPS (0.25 FP16 PFLOPS) and 128 GB unified memory at - hopefully - $3000.
Another important feature is NCCL, which is fast inter-GPU communication. Thus, multiple boxes can be used for inference.
Another important feature is NCCL, which is fast inter-GPU communication. Thus, multiple boxes can be used for inference.
A good future is one with AIs on every desk.
If that future is to come, we need to catalyse a similar community and similar machines.
The first machine I heard about in this category was Tinybox.
The smallest has 0.7 FP16 PFLOPS and 144GB GPU memory at $15k.
If that future is to come, we need to catalyse a similar community and similar machines.
The first machine I heard about in this category was Tinybox.
The smallest has 0.7 FP16 PFLOPS and 144GB GPU memory at $15k.

January 7, 2025 at 2:50 PM
A good future is one with AIs on every desk.
If that future is to come, we need to catalyse a similar community and similar machines.
The first machine I heard about in this category was Tinybox.
The smallest has 0.7 FP16 PFLOPS and 144GB GPU memory at $15k.
If that future is to come, we need to catalyse a similar community and similar machines.
The first machine I heard about in this category was Tinybox.
The smallest has 0.7 FP16 PFLOPS and 144GB GPU memory at $15k.
In 1975, the Altair 8800 was released at about $3000 (inflation adjusted).
It was programmed using individual switches and its display was a bunch of lights on the front panel.
Nonetheless, the price was low enough to start a hobbyist community and catalyse the PC community.
It was programmed using individual switches and its display was a bunch of lights on the front panel.
Nonetheless, the price was low enough to start a hobbyist community and catalyse the PC community.

January 7, 2025 at 2:50 PM
In 1975, the Altair 8800 was released at about $3000 (inflation adjusted).
It was programmed using individual switches and its display was a bunch of lights on the front panel.
Nonetheless, the price was low enough to start a hobbyist community and catalyse the PC community.
It was programmed using individual switches and its display was a bunch of lights on the front panel.
Nonetheless, the price was low enough to start a hobbyist community and catalyse the PC community.
Comparing vectors of landmarks with a remote database is the first product use of homomorphic encryption I've heard of.
It's a good one!
Privacy-preserving RAG with local LLM and remote documents could be done in a very similar way.
It's a good one!
Privacy-preserving RAG with local LLM and remote documents could be done in a very similar way.

January 5, 2025 at 9:31 PM
Comparing vectors of landmarks with a remote database is the first product use of homomorphic encryption I've heard of.
It's a good one!
Privacy-preserving RAG with local LLM and remote documents could be done in a very similar way.
It's a good one!
Privacy-preserving RAG with local LLM and remote documents could be done in a very similar way.
Another benchmark where o-class models show a jump compared to GPT-class models (arXiv:2406.04520)
Mystery Blocksworld is a block stacking task where the names are randomised, requiring generalisation.
Still plenty of room to go, but clearly the start of a new s curve.
Mystery Blocksworld is a block stacking task where the names are randomised, requiring generalisation.
Still plenty of room to go, but clearly the start of a new s curve.

January 3, 2025 at 6:51 PM
Another benchmark where o-class models show a jump compared to GPT-class models (arXiv:2406.04520)
Mystery Blocksworld is a block stacking task where the names are randomised, requiring generalisation.
Still plenty of room to go, but clearly the start of a new s curve.
Mystery Blocksworld is a block stacking task where the names are randomised, requiring generalisation.
Still plenty of room to go, but clearly the start of a new s curve.
One of the great things about AI is how accessible research tooling is.
Breakthrough labs (this is from OpenAI) are basically GPUs, Python, monitoring, docs, and a chat app.
Even if this post was part in jest, this is a point of joy. We should make sure the culture of openness continues.
Breakthrough labs (this is from OpenAI) are basically GPUs, Python, monitoring, docs, and a chat app.
Even if this post was part in jest, this is a point of joy. We should make sure the culture of openness continues.

December 27, 2024 at 12:37 PM
One of the great things about AI is how accessible research tooling is.
Breakthrough labs (this is from OpenAI) are basically GPUs, Python, monitoring, docs, and a chat app.
Even if this post was part in jest, this is a point of joy. We should make sure the culture of openness continues.
Breakthrough labs (this is from OpenAI) are basically GPUs, Python, monitoring, docs, and a chat app.
Even if this post was part in jest, this is a point of joy. We should make sure the culture of openness continues.
One thing I'd wish to know more about is the type of RL used.
My intuition is that it rhymes with MaxEnt, with code and math verifiers. Like, OREO has similar scaling curves.
My intuition is that it rhymes with MaxEnt, with code and math verifiers. Like, OREO has similar scaling curves.

December 24, 2024 at 4:44 PM
One thing I'd wish to know more about is the type of RL used.
My intuition is that it rhymes with MaxEnt, with code and math verifiers. Like, OREO has similar scaling curves.
My intuition is that it rhymes with MaxEnt, with code and math verifiers. Like, OREO has similar scaling curves.
Nice 5x to 15.6x speed-up of equivariant operations from NVIDIA.

November 20, 2024 at 10:52 AM
Nice 5x to 15.6x speed-up of equivariant operations from NVIDIA.
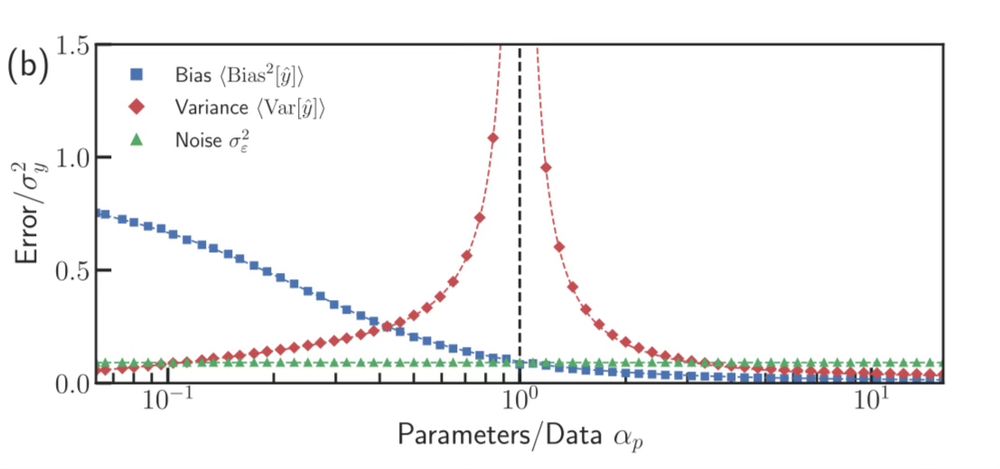
This is a super interesting plot.
ML conventional wisdom is the bias-variance trade-off.
Here is a neural net with a single hidden layer. At first, bias decreases and variance increases.
As you train for longer, you get a phase transition and then *both* decrease.
ML conventional wisdom is the bias-variance trade-off.
Here is a neural net with a single hidden layer. At first, bias decreases and variance increases.
As you train for longer, you get a phase transition and then *both* decrease.
November 18, 2024 at 7:58 PM
This is a super interesting plot.
ML conventional wisdom is the bias-variance trade-off.
Here is a neural net with a single hidden layer. At first, bias decreases and variance increases.
As you train for longer, you get a phase transition and then *both* decrease.
ML conventional wisdom is the bias-variance trade-off.
Here is a neural net with a single hidden layer. At first, bias decreases and variance increases.
As you train for longer, you get a phase transition and then *both* decrease.