




Jiahai Feng
@fjiahai.bsky.social
AI interp @UC Berkeley | prev. MIT
jiahai-feng.github.io
jiahai-feng.github.io
Reposted by Jiahai Feng

When RLHFed models engage in “reward hacking” it can lead to unsafe/unwanted behavior. But there isn’t a good formal definition of what this means! Our new paper provides a definition AND a method that provably prevents reward hacking in realistic settings, including RLHF. 🧵
December 19, 2024 at 5:17 PM
When RLHFed models engage in “reward hacking” it can lead to unsafe/unwanted behavior. But there isn’t a good formal definition of what this means! Our new paper provides a definition AND a method that provably prevents reward hacking in realistic settings, including RLHF. 🧵
Reposted by Jiahai Feng

Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
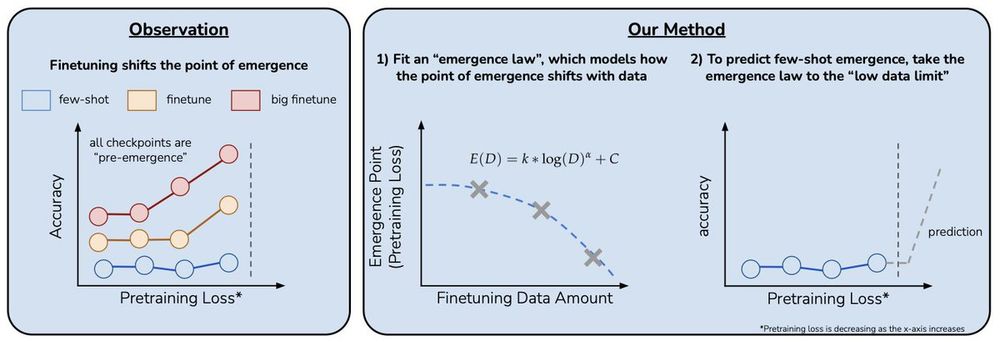
November 26, 2024 at 10:37 PM
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵