


Francesco Asnicar
@fasnicar.bsky.social
Researcher at Dept. CIBIO (Univ. of Trento, Italy), previously postdoc @cibiocm.bsky.social, love music and play keyboards.
What I believe was surprising was that how much a single bacteria species is explaining (and predicting) a single food item (coffee), among all the complexities we have in microbiome studies. And these predictions were not presence/absence but rather with relative abundance values. (2/2)
February 21, 2025 at 5:11 PM
What I believe was surprising was that how much a single bacteria species is explaining (and predicting) a single food item (coffee), among all the complexities we have in microbiome studies. And these predictions were not presence/absence but rather with relative abundance values. (2/2)
Thanks Gabriele for your interest in our work. Indeed, we don't really go into the clinical/medical relevance of Lawsonibacter here. (1/2)
February 21, 2025 at 5:11 PM
Thanks Gabriele for your interest in our work. Indeed, we don't really go into the clinical/medical relevance of Lawsonibacter here. (1/2)
Ciao @mikeneugent.bsky.social from the both us! (unfortunately mine is from the vending machine, the fastest one I could get here!)

December 17, 2024 at 8:11 AM
Ciao @mikeneugent.bsky.social from the both us! (unfortunately mine is from the vending machine, the fastest one I could get here!)
Fantastic event in Goiania! Beautiful audience and nice people! Had a great time, thanks Joao for the invitation and all the organizers for the organization!




November 24, 2024 at 2:33 PM
Fantastic event in Goiania! Beautiful audience and nice people! Had a great time, thanks Joao for the invitation and all the organizers for the organization!
Would love to be included if possible, thanks a lot
November 18, 2024 at 9:05 AM
Would love to be included if possible, thanks a lot
Be aware of common pitfalls when using ML in microbiological studies (Box 2) and hopefully, the simplified checklist when reading, reviewing, or applying ML (Box 3) can help in better understanding the best strategies to use and their evaluation.
6/6
6/6
November 16, 2023 at 1:42 PM
Be aware of common pitfalls when using ML in microbiological studies (Box 2) and hopefully, the simplified checklist when reading, reviewing, or applying ML (Box 3) can help in better understanding the best strategies to use and their evaluation.
6/6
6/6
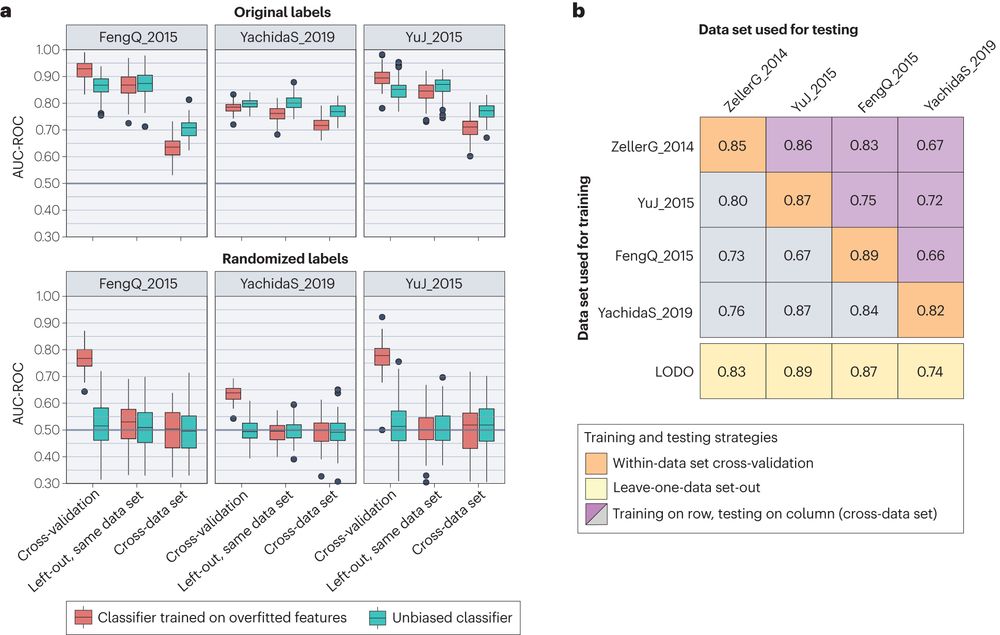
Be careful of overfitting, feature selection and testing within the same data, which could lead to overoptimistic within-dataset and poor performances cross-cohorts.
5/6
5/6
November 16, 2023 at 1:42 PM
Be careful of overfitting, feature selection and testing within the same data, which could lead to overoptimistic within-dataset and poor performances cross-cohorts.
5/6
5/6
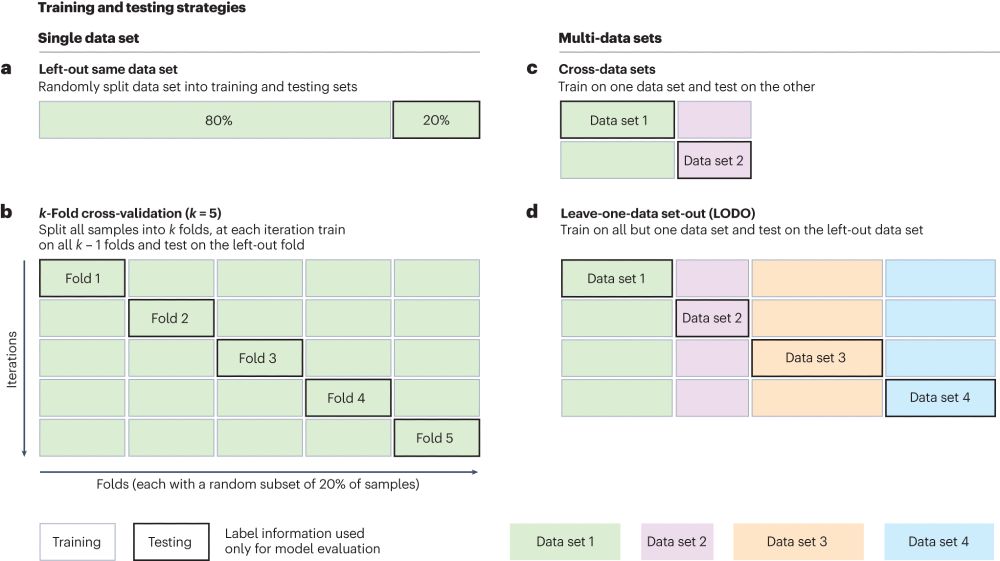
Several strategies are available to accurately estimate ML performances and depend and the data/cohorts availability.
4/6
4/6
November 16, 2023 at 1:42 PM
Several strategies are available to accurately estimate ML performances and depend and the data/cohorts availability.
4/6
4/6
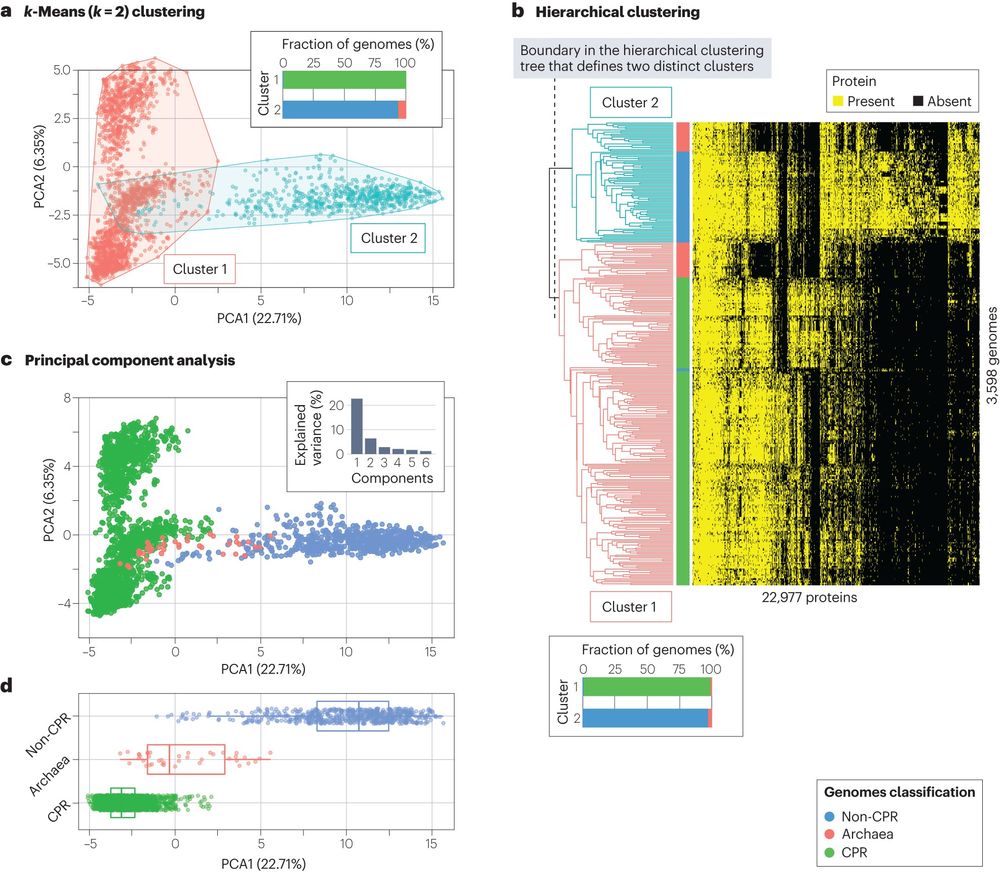
Dimensionality reduction and clustering are two of the most used algorithms in microbiology, and different algorithms will have different results and visualization of high-dimensional data is also a non-easy task.
3/6
3/6
November 16, 2023 at 1:41 PM
Dimensionality reduction and clustering are two of the most used algorithms in microbiology, and different algorithms will have different results and visualization of high-dimensional data is also a non-easy task.
3/6
3/6
A ML workflow involves many small details: difficult to represent in a simplified schema as most are also algorithm-dependent. However, having a clear idea about the process can better help understand how several steps (samples, features, training, prediction) connect.
2/6
2/6
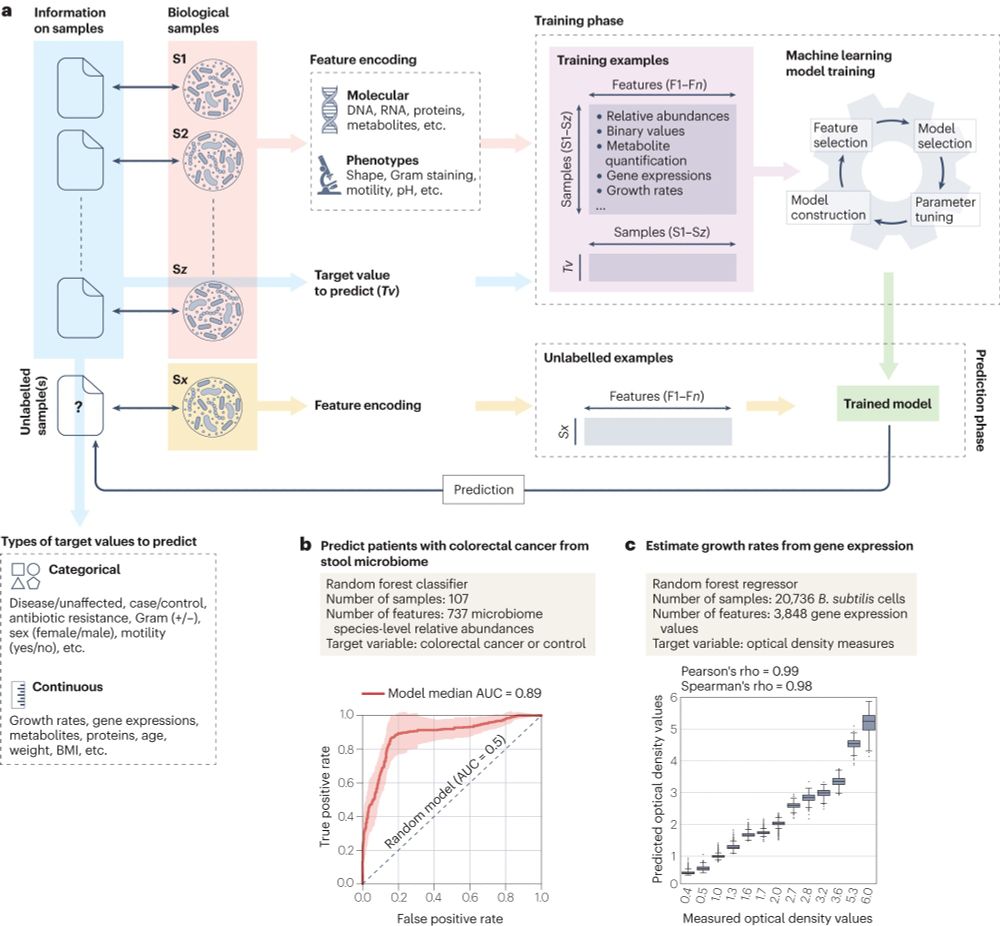
November 16, 2023 at 1:41 PM
A ML workflow involves many small details: difficult to represent in a simplified schema as most are also algorithm-dependent. However, having a clear idea about the process can better help understand how several steps (samples, features, training, prediction) connect.
2/6
2/6