




Fanny Jourdan
@fannyjrd.bsky.social
French mathematician doing XAI and Fairness for #NLProc.
Prev: PhD on CS at ANITI Toulouse & MSc on maths at École polytechnique Paris.
https://fanny-jourdan.github.io/
Prev: PhD on CS at ANITI Toulouse & MSc on maths at École polytechnique Paris.
https://fanny-jourdan.github.io/
Merci Gabriele ! 😀
September 19, 2025 at 3:50 PM
Merci Gabriele ! 😀
I remain affiliated with IRT Saint Exupéry in Toulouse, with the goal of strengthening collaborations between the Montréal and Toulouse AI ecosystems.
Looking forward to this new chapter and all the exchanges ahead! 🤩
Looking forward to this new chapter and all the exchanges ahead! 🤩
September 19, 2025 at 2:37 PM
I remain affiliated with IRT Saint Exupéry in Toulouse, with the goal of strengthening collaborations between the Montréal and Toulouse AI ecosystems.
Looking forward to this new chapter and all the exchanges ahead! 🤩
Looking forward to this new chapter and all the exchanges ahead! 🤩
Huge thanks to Jackie Chi Kit Cheung (Mila) and Pablo Piantanida (ÉTS) for the invitation 🙏
September 19, 2025 at 2:37 PM
Huge thanks to Jackie Chi Kit Cheung (Mila) and Pablo Piantanida (ÉTS) for the invitation 🙏
Everything is open access:
📁 Paper → arxiv.org/abs/2504.15941
📁 Dataset → huggingface.co/datasets/Fan...
📂 Code → github.com/fanny-jourda...
✨ Test your model, compare, fork, or build on top. Let’s fix MT together.
10/11
📁 Paper → arxiv.org/abs/2504.15941
📁 Dataset → huggingface.co/datasets/Fan...
📂 Code → github.com/fanny-jourda...
✨ Test your model, compare, fork, or build on top. Let’s fix MT together.
10/11
April 23, 2025 at 3:43 PM
Everything is open access:
📁 Paper → arxiv.org/abs/2504.15941
📁 Dataset → huggingface.co/datasets/Fan...
📂 Code → github.com/fanny-jourda...
✨ Test your model, compare, fork, or build on top. Let’s fix MT together.
10/11
📁 Paper → arxiv.org/abs/2504.15941
📁 Dataset → huggingface.co/datasets/Fan...
📂 Code → github.com/fanny-jourda...
✨ Test your model, compare, fork, or build on top. Let’s fix MT together.
10/11
Prompting helps: moral + linguistic prompts increase inclusive outputs and reduce the male-female gap. But it's no silver bullet: quality can drop, and even the best setup yields proper 🇫🇷 markers (like iel or un.e) in only ≤11% of inclusive cases. We need more than vibes.
9/11
9/11

April 23, 2025 at 3:43 PM
Prompting helps: moral + linguistic prompts increase inclusive outputs and reduce the male-female gap. But it's no silver bullet: quality can drop, and even the best setup yields proper 🇫🇷 markers (like iel or un.e) in only ≤11% of inclusive cases. We need more than vibes.
9/11
9/11
🔍 Singular “they” is hardest. In 246 test cases, models output plural “ils/elles” 50–90 % of the time or gendered “il/elle”. Even with inclusive prompts, “iel” appears only sporadically. Diagnostics matter!
8/11
8/11

April 23, 2025 at 3:43 PM
🔍 Singular “they” is hardest. In 246 test cases, models output plural “ils/elles” 50–90 % of the time or gendered “il/elle”. Even with inclusive prompts, “iel” appears only sporadically. Diagnostics matter!
8/11
8/11
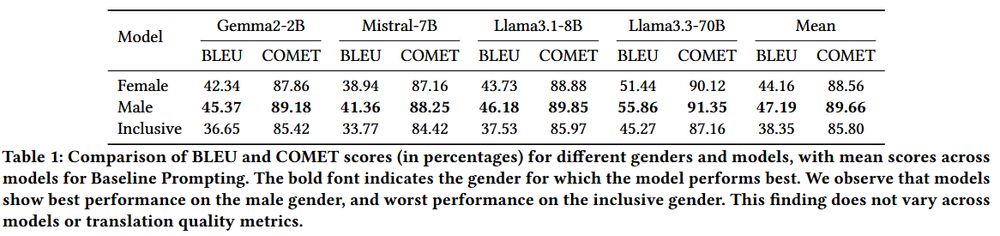
📊 Results: male translations lead, female trail, inclusive dead last—in every configuration. Bias is systemic, not model‑specific.
7/11
7/11

April 23, 2025 at 3:43 PM
📊 Results: male translations lead, female trail, inclusive dead last—in every configuration. Bias is systemic, not model‑specific.
7/11
7/11
🛠️ Benchmarked Gemma‑2B, Mistral‑7B, Llama 3‑8B & 70B under 4 prompts (baseline, moral, linguistic, moral+ling). Metrics: BLEU, COMET and a custom pronoun/agreement checker → 16 slices x 2 scores = deep bias audit!
6/11
6/11
April 23, 2025 at 3:43 PM
🛠️ Benchmarked Gemma‑2B, Mistral‑7B, Llama 3‑8B & 70B under 4 prompts (baseline, moral, linguistic, moral+ling). Metrics: BLEU, COMET and a custom pronoun/agreement checker → 16 slices x 2 scores = deep bias audit!
6/11
6/11
🌈 Inclusive forms follow consistent 🇫🇷 conventions:
• Pronouns: iel (=singular they)
• Determiners: un.e (=a), lea (=the)
• Nouns: étudiant.e (=student), etc.
✅We also provide a mapping dictionary so alternate spellings are valid.
Everything’s open-source (🤗 + GitHub)!
5/11
• Pronouns: iel (=singular they)
• Determiners: un.e (=a), lea (=the)
• Nouns: étudiant.e (=student), etc.
✅We also provide a mapping dictionary so alternate spellings are valid.
Everything’s open-source (🤗 + GitHub)!
5/11
April 23, 2025 at 3:43 PM
🌈 Inclusive forms follow consistent 🇫🇷 conventions:
• Pronouns: iel (=singular they)
• Determiners: un.e (=a), lea (=the)
• Nouns: étudiant.e (=student), etc.
✅We also provide a mapping dictionary so alternate spellings are valid.
Everything’s open-source (🤗 + GitHub)!
5/11
• Pronouns: iel (=singular they)
• Determiners: un.e (=a), lea (=the)
• Nouns: étudiant.e (=student), etc.
✅We also provide a mapping dictionary so alternate spellings are valid.
Everything’s open-source (🤗 + GitHub)!
5/11
Each entry includes:
•Gender: male/female/inclusive → each sentence exists in 3 versions for counterfactual eval
•Ambiguity: ambiguous/unambiguous/long unambiguous → tests contextual understanding
•Stereotype: masc/fem/neutral job → tests stereotype bias
•Occupation: 🇫🇷 masc/fem/incl forms
4/11
•Gender: male/female/inclusive → each sentence exists in 3 versions for counterfactual eval
•Ambiguity: ambiguous/unambiguous/long unambiguous → tests contextual understanding
•Stereotype: masc/fem/neutral job → tests stereotype bias
•Occupation: 🇫🇷 masc/fem/incl forms
4/11
April 23, 2025 at 3:43 PM
Each entry includes:
•Gender: male/female/inclusive → each sentence exists in 3 versions for counterfactual eval
•Ambiguity: ambiguous/unambiguous/long unambiguous → tests contextual understanding
•Stereotype: masc/fem/neutral job → tests stereotype bias
•Occupation: 🇫🇷 masc/fem/incl forms
4/11
•Gender: male/female/inclusive → each sentence exists in 3 versions for counterfactual eval
•Ambiguity: ambiguous/unambiguous/long unambiguous → tests contextual understanding
•Stereotype: masc/fem/neutral job → tests stereotype bias
•Occupation: 🇫🇷 masc/fem/incl forms
4/11
📦 FairTranslate contains 2 418 EN‑FR sentence pairs covering 62 occupations. Every example appears in three gender variants (male, female, inclusive) and carries metadata on stereotype, ambiguity type, and more. All human‑annotated for reliability.
3/11
3/11

April 23, 2025 at 3:43 PM
📦 FairTranslate contains 2 418 EN‑FR sentence pairs covering 62 occupations. Every example appears in three gender variants (male, female, inclusive) and carries metadata on stereotype, ambiguity type, and more. All human‑annotated for reliability.
3/11
3/11
🤔 Most benchmarks for gender bias in machine translation focus on binary gender (male/female). FairTranslate introduces a new resource for evaluating how LLMs handle non-binary gender in English→French, a language where gender is deeply grammaticalized.
2/11
2/11

April 23, 2025 at 3:43 PM
🤔 Most benchmarks for gender bias in machine translation focus on binary gender (male/female). FairTranslate introduces a new resource for evaluating how LLMs handle non-binary gender in English→French, a language where gender is deeply grammaticalized.
2/11
2/11
Very interesting study! (and your name is very pretty too) 🤗
February 23, 2025 at 4:15 PM
Very interesting study! (and your name is very pretty too) 🤗
Not so far from my original goal (and finally I'm happy because I'm having a more concrete impact). 🙌
January 25, 2025 at 1:11 PM
Not so far from my original goal (and finally I'm happy because I'm having a more concrete impact). 🙌