




Eugene Jang @EMNLP
@eugeneonnlp.bsky.social
great list, would love an add!
December 5, 2024 at 6:57 AM
great list, would love an add!
Reposted by Eugene Jang @EMNLP

To paraphrase Dennett (rip 💔), the goal of reviewing is to determine truth, not to conquer your opponent.
Too many reviewers seem to not have internalised this. In my opinion, this is the hardest lesson a reviewer has to learn, and I want to share some thoughts.
Too many reviewers seem to not have internalised this. In my opinion, this is the hardest lesson a reviewer has to learn, and I want to share some thoughts.
November 27, 2024 at 5:25 PM
To paraphrase Dennett (rip 💔), the goal of reviewing is to determine truth, not to conquer your opponent.
Too many reviewers seem to not have internalised this. In my opinion, this is the hardest lesson a reviewer has to learn, and I want to share some thoughts.
Too many reviewers seem to not have internalised this. In my opinion, this is the hardest lesson a reviewer has to learn, and I want to share some thoughts.
Would appreciate an add!
November 20, 2024 at 12:48 PM
Would appreciate an add!
Thanks to coauthors from S2W Inc. (Jin-Woo Chung
, Keuntae Park), and KAIST (professors Kimin Lee
and Seungwon Shin)!
You can find our paper here: arxiv.org/abs/2410.23684 (11/11)
, Keuntae Park), and KAIST (professors Kimin Lee
and Seungwon Shin)!
You can find our paper here: arxiv.org/abs/2410.23684 (11/11)

November 12, 2024 at 5:10 AM
Thanks to coauthors from S2W Inc. (Jin-Woo Chung
, Keuntae Park), and KAIST (professors Kimin Lee
and Seungwon Shin)!
You can find our paper here: arxiv.org/abs/2410.23684 (11/11)
, Keuntae Park), and KAIST (professors Kimin Lee
and Seungwon Shin)!
You can find our paper here: arxiv.org/abs/2410.23684 (11/11)
Trustworthy models require more reliable tokenization, with robustness that extends beyond the training distribution.
Tokenizer research has surged this year. I'm hoping to share that there's more tokenizer-rooted vulnerabilities beyond undertrained tokens. (10/11)
Tokenizer research has surged this year. I'm hoping to share that there's more tokenizer-rooted vulnerabilities beyond undertrained tokens. (10/11)
November 12, 2024 at 5:09 AM
Trustworthy models require more reliable tokenization, with robustness that extends beyond the training distribution.
Tokenizer research has surged this year. I'm hoping to share that there's more tokenizer-rooted vulnerabilities beyond undertrained tokens. (10/11)
Tokenizer research has surged this year. I'm hoping to share that there's more tokenizer-rooted vulnerabilities beyond undertrained tokens. (10/11)
But why?
During training, incomplete tokens can co-occur with only a few tokens due to their syntax.
Since they can resolve to many characters, they will also be trained to be semantically ambiguous.
We hypothesize these factors can cause fragile token representations. (9/11)
During training, incomplete tokens can co-occur with only a few tokens due to their syntax.
Since they can resolve to many characters, they will also be trained to be semantically ambiguous.
We hypothesize these factors can cause fragile token representations. (9/11)
November 12, 2024 at 5:09 AM
But why?
During training, incomplete tokens can co-occur with only a few tokens due to their syntax.
Since they can resolve to many characters, they will also be trained to be semantically ambiguous.
We hypothesize these factors can cause fragile token representations. (9/11)
During training, incomplete tokens can co-occur with only a few tokens due to their syntax.
Since they can resolve to many characters, they will also be trained to be semantically ambiguous.
We hypothesize these factors can cause fragile token representations. (9/11)
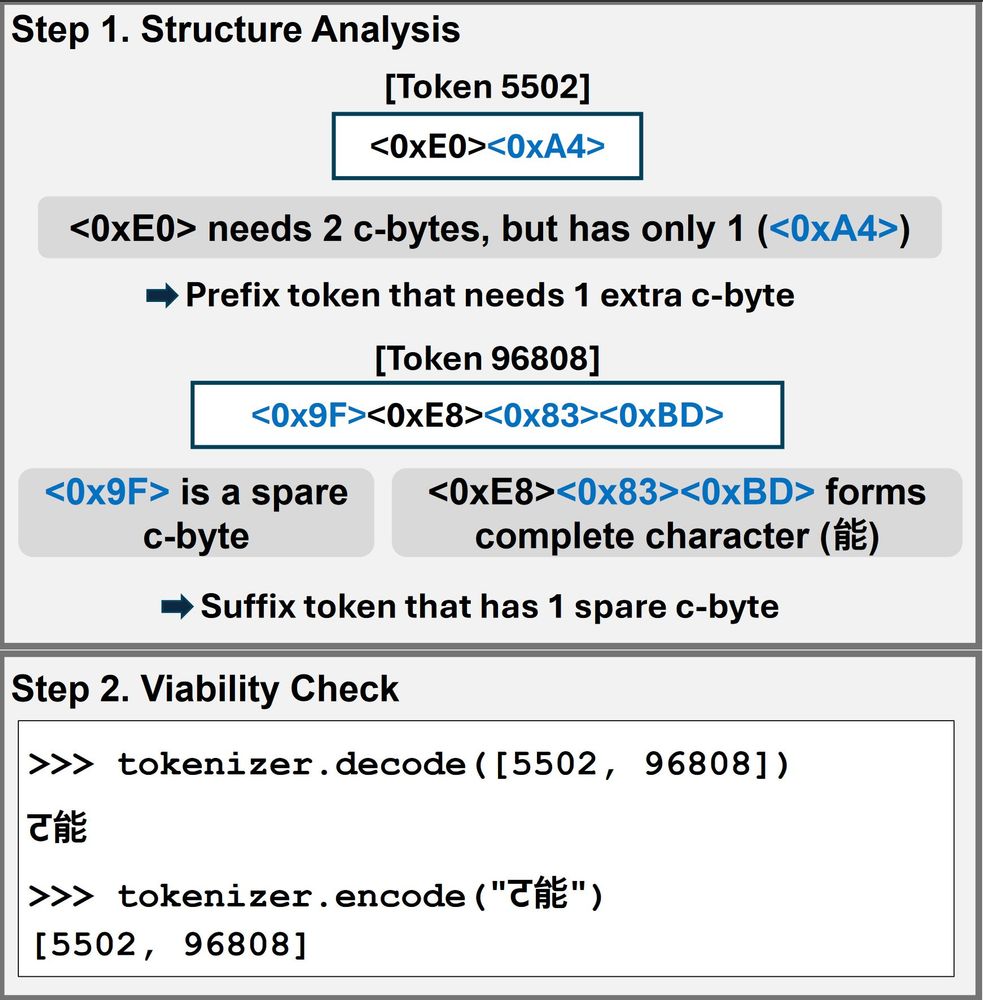
This was very surprising, especially if you consider that the model was trained to never input/output the sequence of "<0x9F>" and "能" together (the tokenizer combines them into a single token.)
Yet, it was more reliable than using the original incomplete tokens. (8/11)
Yet, it was more reliable than using the original incomplete tokens. (8/11)
November 12, 2024 at 5:08 AM
This was very surprising, especially if you consider that the model was trained to never input/output the sequence of "<0x9F>" and "能" together (the tokenizer combines them into a single token.)
Yet, it was more reliable than using the original incomplete tokens. (8/11)
Yet, it was more reliable than using the original incomplete tokens. (8/11)
"But a phrase like ट能 is very OOD. Are you sure these hallucinations are a tokenization problem?"
We think so! When we tokenize the same phrase differently to *avoid* incomplete tokens, the models generally performed much better (including a 93% reduction in Llama3.1). (7/11)
We think so! When we tokenize the same phrase differently to *avoid* incomplete tokens, the models generally performed much better (including a 93% reduction in Llama3.1). (7/11)

November 12, 2024 at 5:08 AM
"But a phrase like ट能 is very OOD. Are you sure these hallucinations are a tokenization problem?"
We think so! When we tokenize the same phrase differently to *avoid* incomplete tokens, the models generally performed much better (including a 93% reduction in Llama3.1). (7/11)
We think so! When we tokenize the same phrase differently to *avoid* incomplete tokens, the models generally performed much better (including a 93% reduction in Llama3.1). (7/11)
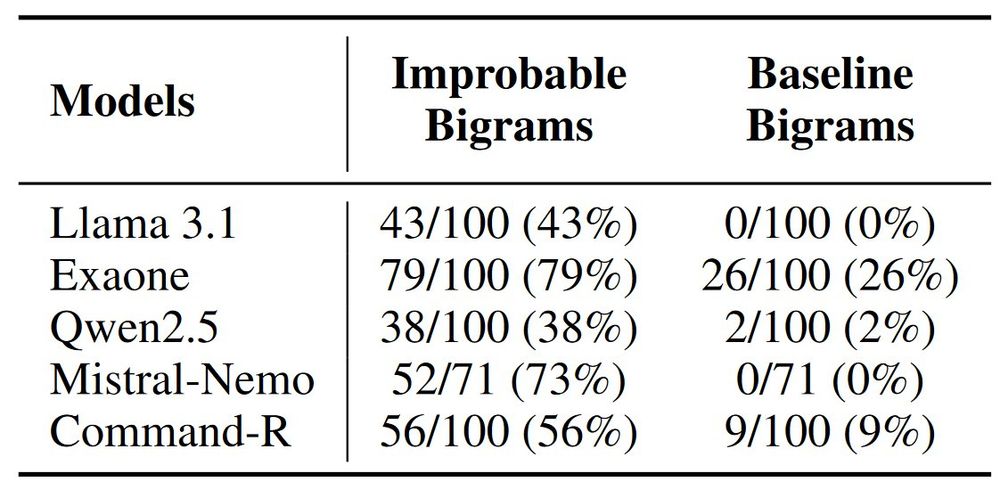
We prepare up to 100 improbable bigrams for each tokenizer, and use comparable complete token bigrams as baselines.
Improbable bigrams were significantly higher to hallucinations.
(For this, we only used trained tokens to remove influence of glitch tokens.) (6/11)
Improbable bigrams were significantly higher to hallucinations.
(For this, we only used trained tokens to remove influence of glitch tokens.) (6/11)
November 12, 2024 at 5:08 AM
We prepare up to 100 improbable bigrams for each tokenizer, and use comparable complete token bigrams as baselines.
Improbable bigrams were significantly higher to hallucinations.
(For this, we only used trained tokens to remove influence of glitch tokens.) (6/11)
Improbable bigrams were significantly higher to hallucinations.
(For this, we only used trained tokens to remove influence of glitch tokens.) (6/11)
We test a model's ability to repeat a target phrase with three different scenarios, which should be doable even for meaningless phrases.
A target phrase is considered hallucinatory only if the model fails to repeat the phrase in all 3 prompts. (5/11)
A target phrase is considered hallucinatory only if the model fails to repeat the phrase in all 3 prompts. (5/11)

November 12, 2024 at 5:08 AM
We test a model's ability to repeat a target phrase with three different scenarios, which should be doable even for meaningless phrases.
A target phrase is considered hallucinatory only if the model fails to repeat the phrase in all 3 prompts. (5/11)
A target phrase is considered hallucinatory only if the model fails to repeat the phrase in all 3 prompts. (5/11)
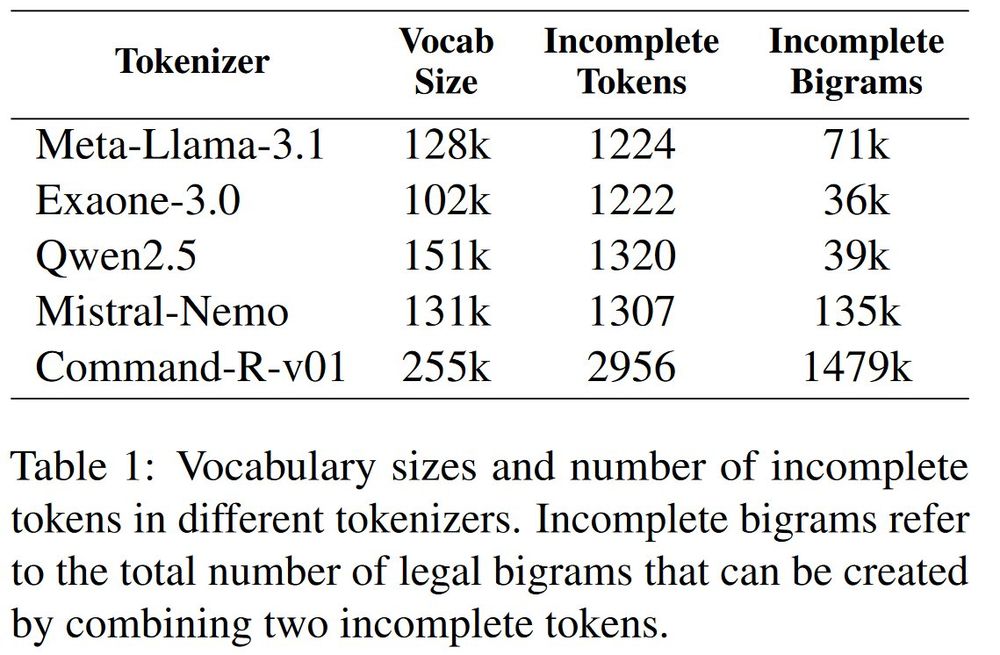
We can analyze each incomplete token's structure based on starting bytes and continuation bytes. We can then find which tokens have complementary structures.
If the pair is re-encodable to the incomplete tokens, it is a legal incomplete bigram. (4/11)
If the pair is re-encodable to the incomplete tokens, it is a legal incomplete bigram. (4/11)
November 12, 2024 at 5:07 AM
We can analyze each incomplete token's structure based on starting bytes and continuation bytes. We can then find which tokens have complementary structures.
If the pair is re-encodable to the incomplete tokens, it is a legal incomplete bigram. (4/11)
If the pair is re-encodable to the incomplete tokens, it is a legal incomplete bigram. (4/11)
ट能 combines two "incomplete tokens" ('<0xE0><0xA4>' and '<0x9F>能').
Such tokens with stray bytes rely on adjacent tokens' stray bytes to resolve as a character.
If two such tokens combine into an "improbable bigram" like ट能, we get a phrase that causes model errors. (3/11)
Such tokens with stray bytes rely on adjacent tokens' stray bytes to resolve as a character.
If two such tokens combine into an "improbable bigram" like ट能, we get a phrase that causes model errors. (3/11)

November 12, 2024 at 5:07 AM
ट能 combines two "incomplete tokens" ('<0xE0><0xA4>' and '<0x9F>能').
Such tokens with stray bytes rely on adjacent tokens' stray bytes to resolve as a character.
If two such tokens combine into an "improbable bigram" like ट能, we get a phrase that causes model errors. (3/11)
Such tokens with stray bytes rely on adjacent tokens' stray bytes to resolve as a character.
If two such tokens combine into an "improbable bigram" like ट能, we get a phrase that causes model errors. (3/11)
You might be familiar with this kind of model behavior from undertrained tokens (SolidGoldMagikarp, $PostalCodesNL). However, what we found was a completely separate phenomenon.
These hallucinatory behaviors persist even when we limit the vocabulary to trained tokens! (2/11)
These hallucinatory behaviors persist even when we limit the vocabulary to trained tokens! (2/11)
November 12, 2024 at 5:07 AM
You might be familiar with this kind of model behavior from undertrained tokens (SolidGoldMagikarp, $PostalCodesNL). However, what we found was a completely separate phenomenon.
These hallucinatory behaviors persist even when we limit the vocabulary to trained tokens! (2/11)
These hallucinatory behaviors persist even when we limit the vocabulary to trained tokens! (2/11)