



Elias Stengel-Eskin
@esteng.bsky.social
Postdoc @UNC working on NLP, AI, and computational linguistics. Formerly PhD student @JHU and undergrad @McGill
esteng.github.io
esteng.github.io
Extremely excited to announce that I will be joining
@utaustin.bsky.social Computer Science in August 2025 as an Assistant Professor! 🎉
@utaustin.bsky.social Computer Science in August 2025 as an Assistant Professor! 🎉

May 5, 2025 at 8:28 PM
Extremely excited to announce that I will be joining
@utaustin.bsky.social Computer Science in August 2025 as an Assistant Professor! 🎉
@utaustin.bsky.social Computer Science in August 2025 as an Assistant Professor! 🎉
By testing VLMs’ spatial reasoning under occlusion, CAPTURe highlights an unexpected weakness. We analyze this weakness by providing the model with additional information:
➡️ Providing object coordinates as text improves performance substantially.
➡️ Providing diffusion-based inpainting also helps.
➡️ Providing object coordinates as text improves performance substantially.
➡️ Providing diffusion-based inpainting also helps.

April 24, 2025 at 3:14 PM
By testing VLMs’ spatial reasoning under occlusion, CAPTURe highlights an unexpected weakness. We analyze this weakness by providing the model with additional information:
➡️ Providing object coordinates as text improves performance substantially.
➡️ Providing diffusion-based inpainting also helps.
➡️ Providing object coordinates as text improves performance substantially.
➡️ Providing diffusion-based inpainting also helps.
Interestingly, model error increases with respect to the number of occluded dots, suggesting that task performance is correlated with the level of occlusion.
Additionally, model performance depends on pattern type (the shape in which the objects are arranged).
Additionally, model performance depends on pattern type (the shape in which the objects are arranged).


April 24, 2025 at 3:14 PM
Interestingly, model error increases with respect to the number of occluded dots, suggesting that task performance is correlated with the level of occlusion.
Additionally, model performance depends on pattern type (the shape in which the objects are arranged).
Additionally, model performance depends on pattern type (the shape in which the objects are arranged).
We evaluate 4 strong VLMs (GPT-4o, InternVL2, Molmo, and Qwen2VL) on CAPTURe.
Models generally struggle with multiple aspects of the task (occluded and unoccluded)
Crucially, every model performs worse in the occluded setting but we find that humans can perform the task easily even with occlusion.
Models generally struggle with multiple aspects of the task (occluded and unoccluded)
Crucially, every model performs worse in the occluded setting but we find that humans can perform the task easily even with occlusion.


April 24, 2025 at 3:14 PM
We evaluate 4 strong VLMs (GPT-4o, InternVL2, Molmo, and Qwen2VL) on CAPTURe.
Models generally struggle with multiple aspects of the task (occluded and unoccluded)
Crucially, every model performs worse in the occluded setting but we find that humans can perform the task easily even with occlusion.
Models generally struggle with multiple aspects of the task (occluded and unoccluded)
Crucially, every model performs worse in the occluded setting but we find that humans can perform the task easily even with occlusion.
We release 2 splits:
➡️ CAPTURe-real contains real-world images and tests the ability of models to perform amodal counting in naturalistic contexts.
➡️ CAPTURe-synthetic allows us to analyze specific factors by controlling different variables like color, shape, and number of objects.
➡️ CAPTURe-real contains real-world images and tests the ability of models to perform amodal counting in naturalistic contexts.
➡️ CAPTURe-synthetic allows us to analyze specific factors by controlling different variables like color, shape, and number of objects.

April 24, 2025 at 3:14 PM
We release 2 splits:
➡️ CAPTURe-real contains real-world images and tests the ability of models to perform amodal counting in naturalistic contexts.
➡️ CAPTURe-synthetic allows us to analyze specific factors by controlling different variables like color, shape, and number of objects.
➡️ CAPTURe-real contains real-world images and tests the ability of models to perform amodal counting in naturalistic contexts.
➡️ CAPTURe-synthetic allows us to analyze specific factors by controlling different variables like color, shape, and number of objects.
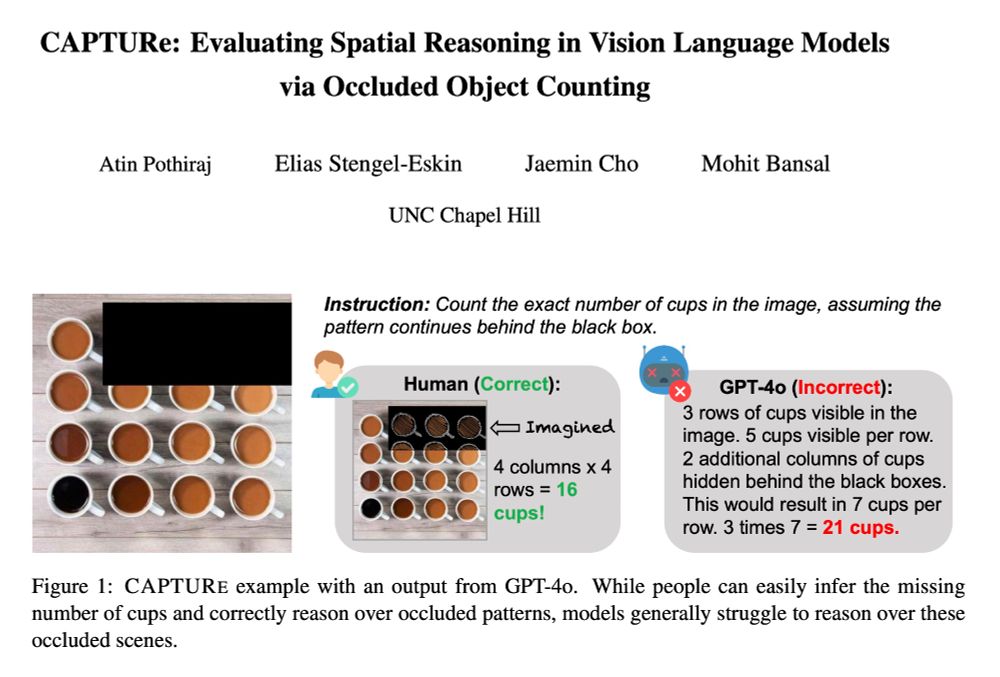
Check out 🚨CAPTURe🚨 -- a new benchmark testing spatial reasoning by making VLMs count objects under occlusion.
SOTA VLMs (GPT-4o, Qwen2-VL, Intern-VL2) have high error rates on CAPTURe (but humans have low error ✅) and models struggle to reason about occluded objects.
arxiv.org/abs/2504.15485
🧵👇
SOTA VLMs (GPT-4o, Qwen2-VL, Intern-VL2) have high error rates on CAPTURe (but humans have low error ✅) and models struggle to reason about occluded objects.
arxiv.org/abs/2504.15485
🧵👇
April 24, 2025 at 3:14 PM
Check out 🚨CAPTURe🚨 -- a new benchmark testing spatial reasoning by making VLMs count objects under occlusion.
SOTA VLMs (GPT-4o, Qwen2-VL, Intern-VL2) have high error rates on CAPTURe (but humans have low error ✅) and models struggle to reason about occluded objects.
arxiv.org/abs/2504.15485
🧵👇
SOTA VLMs (GPT-4o, Qwen2-VL, Intern-VL2) have high error rates on CAPTURe (but humans have low error ✅) and models struggle to reason about occluded objects.
arxiv.org/abs/2504.15485
🧵👇
To simulate a realistic use case involving generation, we evaluate on Spider for text-to-sql.
Quantization methods struggle with preserving performance on generative tasks. We show that TaCQ is the only method to achieve non-zero performance in 2-bits for Llama-3-8B-Instruct.
Quantization methods struggle with preserving performance on generative tasks. We show that TaCQ is the only method to achieve non-zero performance in 2-bits for Llama-3-8B-Instruct.

April 12, 2025 at 2:19 PM
To simulate a realistic use case involving generation, we evaluate on Spider for text-to-sql.
Quantization methods struggle with preserving performance on generative tasks. We show that TaCQ is the only method to achieve non-zero performance in 2-bits for Llama-3-8B-Instruct.
Quantization methods struggle with preserving performance on generative tasks. We show that TaCQ is the only method to achieve non-zero performance in 2-bits for Llama-3-8B-Instruct.
We also show that TaCQ generalizes to larger models, recovering 87.93% of the 16-bit Qwen2.5-32B-Instruct model’s performance at 2-bit quantization. We also include results showing TaCQ performs well on Qwen2.5-7B-Instruct.


April 12, 2025 at 2:19 PM
We also show that TaCQ generalizes to larger models, recovering 87.93% of the 16-bit Qwen2.5-32B-Instruct model’s performance at 2-bit quantization. We also include results showing TaCQ performs well on Qwen2.5-7B-Instruct.
✅TaCQ also outperforms even without conditioning on specific tasks, gaining 7.12% in 2-bit and 2.88% in 3-bit.
💡Conditioning creates consistent 10%+ gains in low bits for many quantization methods.
💡Conditioning creates consistent 10%+ gains in low bits for many quantization methods.

April 12, 2025 at 2:19 PM
✅TaCQ also outperforms even without conditioning on specific tasks, gaining 7.12% in 2-bit and 2.88% in 3-bit.
💡Conditioning creates consistent 10%+ gains in low bits for many quantization methods.
💡Conditioning creates consistent 10%+ gains in low bits for many quantization methods.
📊Evaluations show that TaCQ improves accuracy on average by 14.74% in 2-bit and 1-2% in 3-bit when compared to baselines using the same conditioning dataset and lower bits per weight.
This holds true across multiple MMLU topics/tasks and GSM8K.
This holds true across multiple MMLU topics/tasks and GSM8K.

April 12, 2025 at 2:19 PM
📊Evaluations show that TaCQ improves accuracy on average by 14.74% in 2-bit and 1-2% in 3-bit when compared to baselines using the same conditioning dataset and lower bits per weight.
This holds true across multiple MMLU topics/tasks and GSM8K.
This holds true across multiple MMLU topics/tasks and GSM8K.
✨Let’s introduce Task Circuit Quantization (TaCQ)
Our saliency metric is composed of two parts:
1️⃣ Quantization Aware Localization (QAL)
2️⃣ Magnitude Sharpened Gradient (MSG):
Our saliency metric is composed of two parts:
1️⃣ Quantization Aware Localization (QAL)
2️⃣ Magnitude Sharpened Gradient (MSG):

April 12, 2025 at 2:19 PM
✨Let’s introduce Task Circuit Quantization (TaCQ)
Our saliency metric is composed of two parts:
1️⃣ Quantization Aware Localization (QAL)
2️⃣ Magnitude Sharpened Gradient (MSG):
Our saliency metric is composed of two parts:
1️⃣ Quantization Aware Localization (QAL)
2️⃣ Magnitude Sharpened Gradient (MSG):
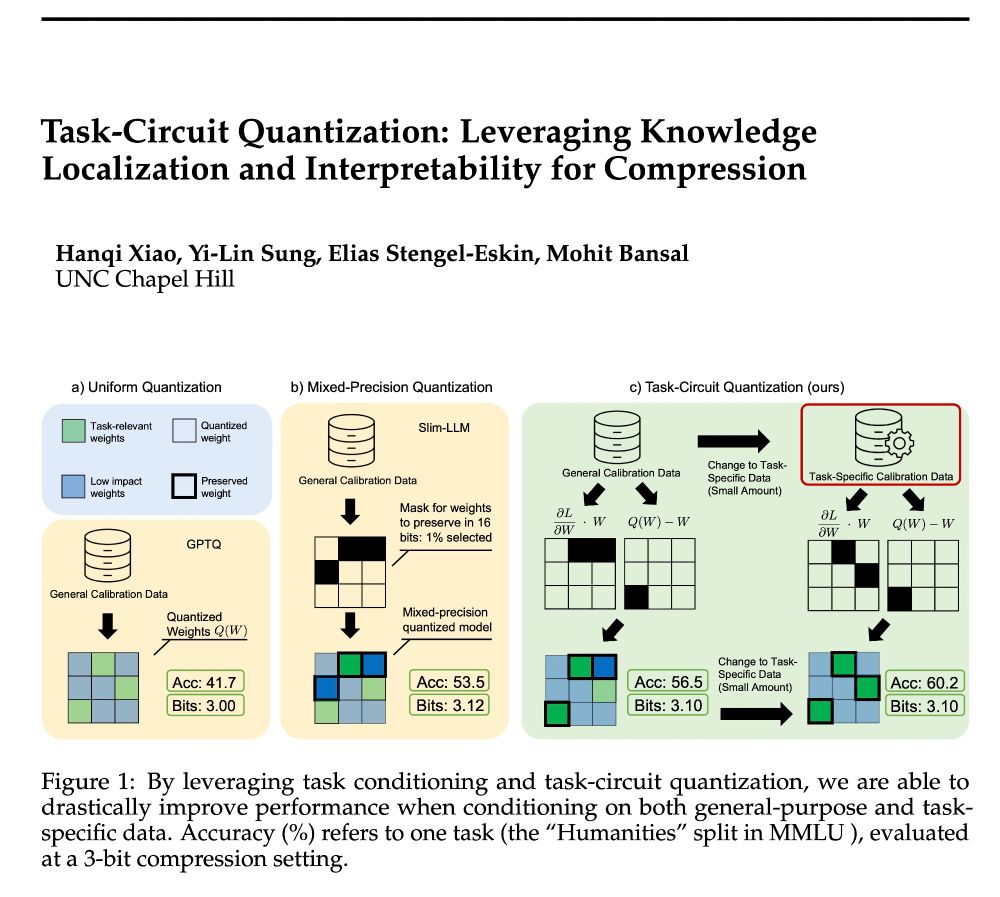
🚨Announcing TaCQ 🚨 a new mixed-precision quantization method that identifies critical weights to preserve. We integrate key ideas from circuit discovery, model editing, and input attribution to improve low-bit quant., w/ 96% 16-bit acc. at 3.1 avg bits (~6x compression)
📃 arxiv.org/abs/2504.07389
📃 arxiv.org/abs/2504.07389
April 12, 2025 at 2:19 PM
🚨Announcing TaCQ 🚨 a new mixed-precision quantization method that identifies critical weights to preserve. We integrate key ideas from circuit discovery, model editing, and input attribution to improve low-bit quant., w/ 96% 16-bit acc. at 3.1 avg bits (~6x compression)
📃 arxiv.org/abs/2504.07389
📃 arxiv.org/abs/2504.07389
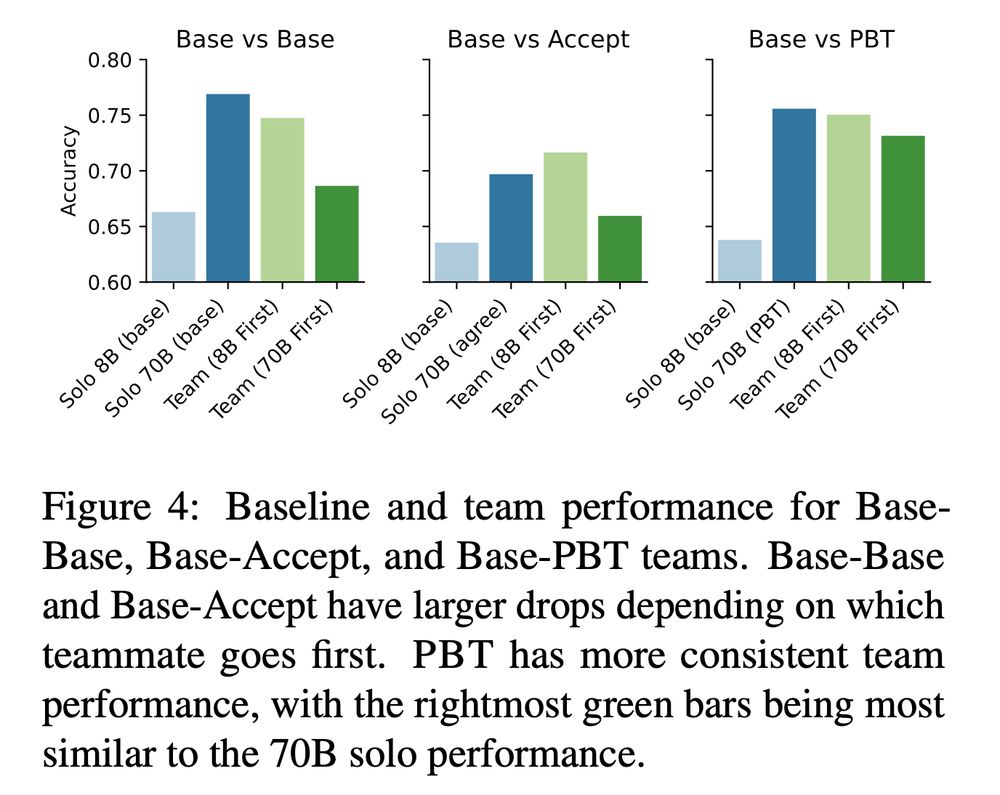
PBT also makes models better teammates:
When pairing 2 non-PBT LLMs in a multi-agent debate, we observe order-dependence. Depending on whether the stronger or weaker model goes first, the team lands on the right/wrong answer. PBT reduces this & improves team performance.
3/4
When pairing 2 non-PBT LLMs in a multi-agent debate, we observe order-dependence. Depending on whether the stronger or weaker model goes first, the team lands on the right/wrong answer. PBT reduces this & improves team performance.
3/4
January 23, 2025 at 4:51 PM
PBT also makes models better teammates:
When pairing 2 non-PBT LLMs in a multi-agent debate, we observe order-dependence. Depending on whether the stronger or weaker model goes first, the team lands on the right/wrong answer. PBT reduces this & improves team performance.
3/4
When pairing 2 non-PBT LLMs in a multi-agent debate, we observe order-dependence. Depending on whether the stronger or weaker model goes first, the team lands on the right/wrong answer. PBT reduces this & improves team performance.
3/4
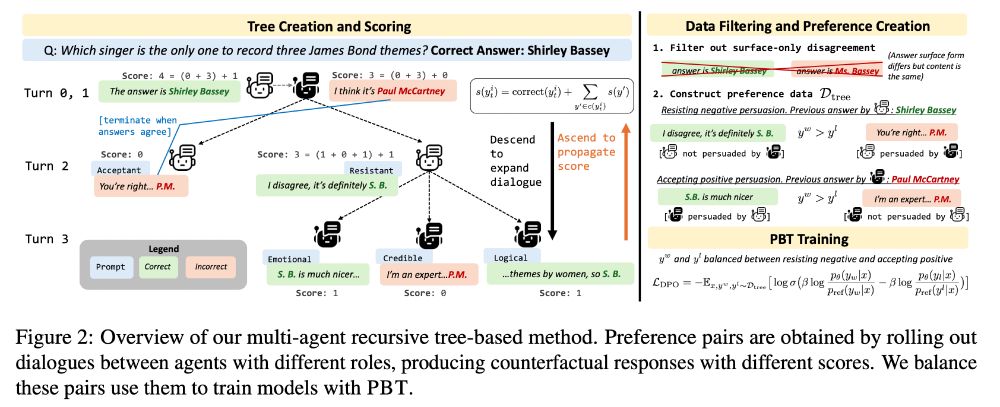
PBT creates RLHF training data from generated/simulated multi-agent dialogue trees and then trains models on positive/negative persuasion.
Across three models of varying sizes, PBT
-- improves resistance to misinformation
-- reduces flipflopping
-- obtains best performance on balanced data
2/4
Across three models of varying sizes, PBT
-- improves resistance to misinformation
-- reduces flipflopping
-- obtains best performance on balanced data
2/4
January 23, 2025 at 4:51 PM
PBT creates RLHF training data from generated/simulated multi-agent dialogue trees and then trains models on positive/negative persuasion.
Across three models of varying sizes, PBT
-- improves resistance to misinformation
-- reduces flipflopping
-- obtains best performance on balanced data
2/4
Across three models of varying sizes, PBT
-- improves resistance to misinformation
-- reduces flipflopping
-- obtains best performance on balanced data
2/4
🎉Very excited that our work on Persuasion-Balanced Training has been accepted to #NAACL2025! We introduce a multi-agent tree-based method for teaching models to balance:
1️⃣ Accepting persuasion when it helps
2️⃣ Resisting persuasion when it hurts (e.g. misinformation)
arxiv.org/abs/2410.14596
🧵 1/4
1️⃣ Accepting persuasion when it helps
2️⃣ Resisting persuasion when it hurts (e.g. misinformation)
arxiv.org/abs/2410.14596
🧵 1/4

January 23, 2025 at 4:51 PM
🎉Very excited that our work on Persuasion-Balanced Training has been accepted to #NAACL2025! We introduce a multi-agent tree-based method for teaching models to balance:
1️⃣ Accepting persuasion when it helps
2️⃣ Resisting persuasion when it hurts (e.g. misinformation)
arxiv.org/abs/2410.14596
🧵 1/4
1️⃣ Accepting persuasion when it helps
2️⃣ Resisting persuasion when it hurts (e.g. misinformation)
arxiv.org/abs/2410.14596
🧵 1/4
✈️ I've landed in Vancouver for #NeurIPS2024
11/12: LACIE, a pragmatic speaker-listener method for training LLMs to express calibrated confidence: arxiv.org/abs/2405.21028
12/12: GTBench, a benchmark for game-theoretic abilities in LLMs: arxiv.org/abs/2402.12348
P.s. I'm on the faculty market👇
11/12: LACIE, a pragmatic speaker-listener method for training LLMs to express calibrated confidence: arxiv.org/abs/2405.21028
12/12: GTBench, a benchmark for game-theoretic abilities in LLMs: arxiv.org/abs/2402.12348
P.s. I'm on the faculty market👇


December 10, 2024 at 10:14 PM
✈️ I've landed in Vancouver for #NeurIPS2024
11/12: LACIE, a pragmatic speaker-listener method for training LLMs to express calibrated confidence: arxiv.org/abs/2405.21028
12/12: GTBench, a benchmark for game-theoretic abilities in LLMs: arxiv.org/abs/2402.12348
P.s. I'm on the faculty market👇
11/12: LACIE, a pragmatic speaker-listener method for training LLMs to express calibrated confidence: arxiv.org/abs/2405.21028
12/12: GTBench, a benchmark for game-theoretic abilities in LLMs: arxiv.org/abs/2402.12348
P.s. I'm on the faculty market👇
❔Handling uncertainty❔
Safe+reliable AI must handle uncertainty, esp. since language is underspecified/ambiguous. My work has addressed:
1️⃣ Uncertainty in predicting actions
2️⃣ Ambiguity in predicting structure
3️⃣ Resolving ambiguity and underspecification in multimodal settings
Safe+reliable AI must handle uncertainty, esp. since language is underspecified/ambiguous. My work has addressed:
1️⃣ Uncertainty in predicting actions
2️⃣ Ambiguity in predicting structure
3️⃣ Resolving ambiguity and underspecification in multimodal settings

December 5, 2024 at 7:00 PM
❔Handling uncertainty❔
Safe+reliable AI must handle uncertainty, esp. since language is underspecified/ambiguous. My work has addressed:
1️⃣ Uncertainty in predicting actions
2️⃣ Ambiguity in predicting structure
3️⃣ Resolving ambiguity and underspecification in multimodal settings
Safe+reliable AI must handle uncertainty, esp. since language is underspecified/ambiguous. My work has addressed:
1️⃣ Uncertainty in predicting actions
2️⃣ Ambiguity in predicting structure
3️⃣ Resolving ambiguity and underspecification in multimodal settings
📷 Grounding, skills, and actions 🦾
Agents must perceive and act in the world. My work covers grounding agents to multimodal inputs/actions/structures, including:
1️⃣ Translating language to code/actions/plans
2️⃣ Learning abstractions and skills
3️⃣ Processing/learning from videos and images
Agents must perceive and act in the world. My work covers grounding agents to multimodal inputs/actions/structures, including:
1️⃣ Translating language to code/actions/plans
2️⃣ Learning abstractions and skills
3️⃣ Processing/learning from videos and images

December 5, 2024 at 7:00 PM
📷 Grounding, skills, and actions 🦾
Agents must perceive and act in the world. My work covers grounding agents to multimodal inputs/actions/structures, including:
1️⃣ Translating language to code/actions/plans
2️⃣ Learning abstractions and skills
3️⃣ Processing/learning from videos and images
Agents must perceive and act in the world. My work covers grounding agents to multimodal inputs/actions/structures, including:
1️⃣ Translating language to code/actions/plans
2️⃣ Learning abstractions and skills
3️⃣ Processing/learning from videos and images
🤖 Multi-agent Interaction 🤖
AI agents need to communicate pragmatically. My work covers key issues including:
1️⃣ Multi-agent teaching of pragmatic skills
2️⃣ Efficient/improved multi-agent discussions
3️⃣ Multi-agent refinement+optimization
4️⃣ Distilling multiple agents into single open-source models
AI agents need to communicate pragmatically. My work covers key issues including:
1️⃣ Multi-agent teaching of pragmatic skills
2️⃣ Efficient/improved multi-agent discussions
3️⃣ Multi-agent refinement+optimization
4️⃣ Distilling multiple agents into single open-source models

December 5, 2024 at 7:00 PM
🤖 Multi-agent Interaction 🤖
AI agents need to communicate pragmatically. My work covers key issues including:
1️⃣ Multi-agent teaching of pragmatic skills
2️⃣ Efficient/improved multi-agent discussions
3️⃣ Multi-agent refinement+optimization
4️⃣ Distilling multiple agents into single open-source models
AI agents need to communicate pragmatically. My work covers key issues including:
1️⃣ Multi-agent teaching of pragmatic skills
2️⃣ Efficient/improved multi-agent discussions
3️⃣ Multi-agent refinement+optimization
4️⃣ Distilling multiple agents into single open-source models
🚨 I am on the faculty job market this year 🚨
I will be presenting at #NeurIPS2024 and am happy to chat in-person or digitally!
I work on developing AI agents that can collaborate and communicate robustly with us and each other.
More at: esteng.github.io and in thread below
🧵👇
I will be presenting at #NeurIPS2024 and am happy to chat in-person or digitally!
I work on developing AI agents that can collaborate and communicate robustly with us and each other.
More at: esteng.github.io and in thread below
🧵👇

December 5, 2024 at 7:00 PM
🚨 I am on the faculty job market this year 🚨
I will be presenting at #NeurIPS2024 and am happy to chat in-person or digitally!
I work on developing AI agents that can collaborate and communicate robustly with us and each other.
More at: esteng.github.io and in thread below
🧵👇
I will be presenting at #NeurIPS2024 and am happy to chat in-person or digitally!
I work on developing AI agents that can collaborate and communicate robustly with us and each other.
More at: esteng.github.io and in thread below
🧵👇