



Erin Young
@erinyoung.bsky.social
Public Health #Bioinformatician. Wants to sequence ALL THE THINGS. Personal account with alternative spellings and grammar structures. She/her
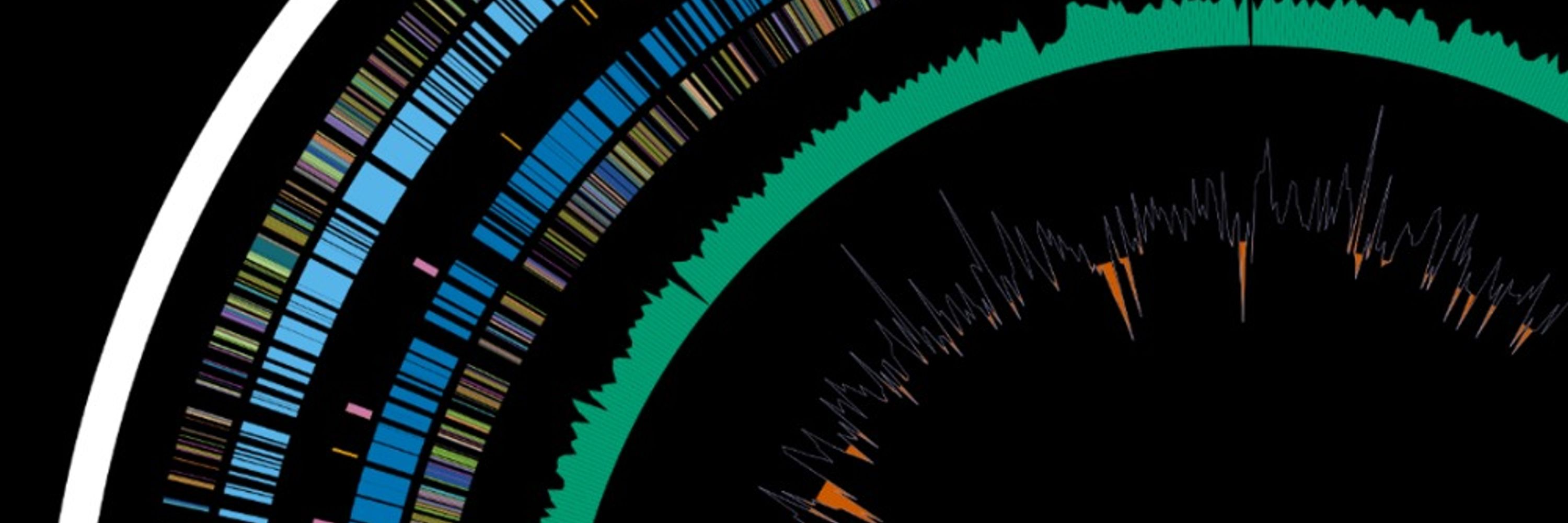
And the cluster link
Isolates SNP Tree Viewer -
Pathogen Detection - NCBI
Isolates SNP Tree Viewer
www.ncbi.nlm.nih.gov
October 17, 2025 at 5:35 PM
And the cluster link
Good idea, but there's more documentation about conda, and a lot of people I work with use the command line less than 5 hours per month.
October 17, 2025 at 3:19 PM
Good idea, but there's more documentation about conda, and a lot of people I work with use the command line less than 5 hours per month.
I personally think it's because each amino acid change gets its own number
October 16, 2025 at 6:27 PM
I personally think it's because each amino acid change gets its own number
It'd really shift my way of thinking if it didn't
September 29, 2025 at 5:05 PM
It'd really shift my way of thinking if it didn't
I think you misunderstand. There is a lot of coverage for these samples. So much so that it is hard to see bubbles or other aberrations.

September 23, 2025 at 8:46 PM
I think you misunderstand. There is a lot of coverage for these samples. So much so that it is hard to see bubbles or other aberrations.
How is this method simpler than what I attempted?
September 23, 2025 at 7:48 PM
How is this method simpler than what I attempted?
All 33 million+ reads were mapped with bbmap (all non-mapped reads were excluded prior to trimming the primers)
September 23, 2025 at 7:38 PM
All 33 million+ reads were mapped with bbmap (all non-mapped reads were excluded prior to trimming the primers)
So, in summary, if high coverage samples aren't getting assigned lineages, I recommend subsampling them or adjusting the `samtools mpileup` command.
September 23, 2025 at 6:01 PM
So, in summary, if high coverage samples aren't getting assigned lineages, I recommend subsampling them or adjusting the `samtools mpileup` command.
I really solved my dilemma (after too many hours trouble shooting it) by adding the `-d 0` flag to `samtools mpileup`, which uses a lot of memory but produced adequate consensus fasta files.
/
/
September 23, 2025 at 6:01 PM
I really solved my dilemma (after too many hours trouble shooting it) by adding the `-d 0` flag to `samtools mpileup`, which uses a lot of memory but produced adequate consensus fasta files.
/
/
Instead it turns out that `bbmap` was allowing for very large insert sizes, some of which spanned the majority of the genome. These, for whatever reason, were given priority for `samtools mpileup` (which gets piped into `ivar consensus`) /
September 23, 2025 at 6:01 PM
Instead it turns out that `bbmap` was allowing for very large insert sizes, some of which spanned the majority of the genome. These, for whatever reason, were given priority for `samtools mpileup` (which gets piped into `ivar consensus`) /
The most irritating part is that each of these 18 would generate a consensus that could be used for determining lineage if I subsampled them. I was worried about contamination, but these had all had human reads removed. /
September 23, 2025 at 6:01 PM
The most irritating part is that each of these 18 would generate a consensus that could be used for determining lineage if I subsampled them. I was worried about contamination, but these had all had human reads removed. /
Just remember to deactivate your environment when finished.
Popular bioinformatic tools have conda recipes, so conda helps make installing bioinformatic tools less painful.
Popular bioinformatic tools have conda recipes, so conda helps make installing bioinformatic tools less painful.
August 28, 2025 at 5:24 PM
Just remember to deactivate your environment when finished.
Popular bioinformatic tools have conda recipes, so conda helps make installing bioinformatic tools less painful.
Popular bioinformatic tools have conda recipes, so conda helps make installing bioinformatic tools less painful.
6. Install stuff
I recommend installing tools in their own environment.
Something like
`conda create -n seqkit seqkit`
will install seqkit in a new conda environment named seqkit.
This environment can be turned on or activated with
`conda activate seqkit` /
I recommend installing tools in their own environment.
Something like
`conda create -n seqkit seqkit`
will install seqkit in a new conda environment named seqkit.
This environment can be turned on or activated with
`conda activate seqkit` /
August 28, 2025 at 5:24 PM
6. Install stuff
I recommend installing tools in their own environment.
Something like
`conda create -n seqkit seqkit`
will install seqkit in a new conda environment named seqkit.
This environment can be turned on or activated with
`conda activate seqkit` /
I recommend installing tools in their own environment.
Something like
`conda create -n seqkit seqkit`
will install seqkit in a new conda environment named seqkit.
This environment can be turned on or activated with
`conda activate seqkit` /
5. Add some extra channels to conda.
I recommend conda-forge and bioconda
Something like this
`conda config --add channels conda-forge`
or this
`conda config --add channels bioconda`
Channels are where different conda packages are stored. Adding channels helps conda find packages to install. /
I recommend conda-forge and bioconda
Something like this
`conda config --add channels conda-forge`
or this
`conda config --add channels bioconda`
Channels are where different conda packages are stored. Adding channels helps conda find packages to install. /
August 28, 2025 at 5:24 PM
5. Add some extra channels to conda.
I recommend conda-forge and bioconda
Something like this
`conda config --add channels conda-forge`
or this
`conda config --add channels bioconda`
Channels are where different conda packages are stored. Adding channels helps conda find packages to install. /
I recommend conda-forge and bioconda
Something like this
`conda config --add channels conda-forge`
or this
`conda config --add channels bioconda`
Channels are where different conda packages are stored. Adding channels helps conda find packages to install. /
There are some people who then recommend installing mamba (or similar) with something like `conda install mamba`, which I think is fine. These tools perform similar tasks to conda, but are often faster. I let "more advanced" users explore these options and tend to keep everything "conda". /
August 28, 2025 at 5:24 PM
There are some people who then recommend installing mamba (or similar) with something like `conda install mamba`, which I think is fine. These tools perform similar tasks to conda, but are often faster. I let "more advanced" users explore these options and tend to keep everything "conda". /
4. Activate conda
Something like source `~/miniconda3/bin/activate`, or just log out and log back in
Now you have conda! /
Something like source `~/miniconda3/bin/activate`, or just log out and log back in
Now you have conda! /
August 28, 2025 at 5:24 PM
4. Activate conda
Something like source `~/miniconda3/bin/activate`, or just log out and log back in
Now you have conda! /
Something like source `~/miniconda3/bin/activate`, or just log out and log back in
Now you have conda! /
3. Use bash (or whatever shell is being used) to run the downloaded script
`bash Miniconda3-latest-Linux-x86_64.sh`
Set all prompts with relevant information, and, yes, you want a line in your ~/.bashrc file
/
`bash Miniconda3-latest-Linux-x86_64.sh`
Set all prompts with relevant information, and, yes, you want a line in your ~/.bashrc file
/
August 28, 2025 at 5:24 PM
3. Use bash (or whatever shell is being used) to run the downloaded script
`bash Miniconda3-latest-Linux-x86_64.sh`
Set all prompts with relevant information, and, yes, you want a line in your ~/.bashrc file
/
`bash Miniconda3-latest-Linux-x86_64.sh`
Set all prompts with relevant information, and, yes, you want a line in your ~/.bashrc file
/