




Eoin Travers
@eointravers.bsky.social
I'm a Data Scientist, working on responsible AI for mental health.
Posting about data, AI, evals, and cognitive science.
eointravers.com
🇮🇪
Posting about data, AI, evals, and cognitive science.
eointravers.com
🇮🇪

April 6, 2025 at 7:13 PM
I'm on the job market, and like many, I hate LinkedIn. So I've done what any product-oriented data scientist would: built my own workflow. With browser automation/scraping, data pipelines, structured LLM outputs, and a fun way of using @notion.com as a UI.
eointravers.com/blog/job-scr...
eointravers.com/blog/job-scr...

March 24, 2025 at 2:47 PM
I'm on the job market, and like many, I hate LinkedIn. So I've done what any product-oriented data scientist would: built my own workflow. With browser automation/scraping, data pipelines, structured LLM outputs, and a fun way of using @notion.com as a UI.
eointravers.com/blog/job-scr...
eointravers.com/blog/job-scr...
For one-in-three, it’s ~70.4%. One-in-four, ~68.4%. As n increases, the answer gets closer and closer to
1−1/e ≈ 63.2%, where e is Euler’s number.
en.wikipedia.org/wiki/E_(math...
Why 1-1/e? Honestly, you would have to ask someone better at maths than me, but I think it’s a pretty cool result.
1−1/e ≈ 63.2%, where e is Euler’s number.
en.wikipedia.org/wiki/E_(math...
Why 1-1/e? Honestly, you would have to ask someone better at maths than me, but I think it’s a pretty cool result.

March 20, 2025 at 11:50 AM
For one-in-three, it’s ~70.4%. One-in-four, ~68.4%. As n increases, the answer gets closer and closer to
1−1/e ≈ 63.2%, where e is Euler’s number.
en.wikipedia.org/wiki/E_(math...
Why 1-1/e? Honestly, you would have to ask someone better at maths than me, but I think it’s a pretty cool result.
1−1/e ≈ 63.2%, where e is Euler’s number.
en.wikipedia.org/wiki/E_(math...
Why 1-1/e? Honestly, you would have to ask someone better at maths than me, but I think it’s a pretty cool result.

March 20, 2025 at 11:50 AM
Humble-brag:
Over the past two years at Unmind, I got to build two AI features: Nova AI wellbeing coach, and AI practitioner matching. It's lovely to see both get a call out in Fast Company's list of the most innovative companies in the workplace for 2025.
www.fastcompany.com/91270254/wor...
Over the past two years at Unmind, I got to build two AI features: Nova AI wellbeing coach, and AI practitioner matching. It's lovely to see both get a call out in Fast Company's list of the most innovative companies in the workplace for 2025.
www.fastcompany.com/91270254/wor...

March 19, 2025 at 5:19 PM
Humble-brag:
Over the past two years at Unmind, I got to build two AI features: Nova AI wellbeing coach, and AI practitioner matching. It's lovely to see both get a call out in Fast Company's list of the most innovative companies in the workplace for 2025.
www.fastcompany.com/91270254/wor...
Over the past two years at Unmind, I got to build two AI features: Nova AI wellbeing coach, and AI practitioner matching. It's lovely to see both get a call out in Fast Company's list of the most innovative companies in the workplace for 2025.
www.fastcompany.com/91270254/wor...

Automation frameworks for testing like Selenium (selenium-python.readthedocs.io/index.html) are underrated as a way of quickly prototyping new AI-driven UXs. For example, this script, (<1hr work with Cursor) will open a dedicated browswer that saves every job ad I open to a database [...]


March 10, 2025 at 4:47 PM
Automation frameworks for testing like Selenium (selenium-python.readthedocs.io/index.html) are underrated as a way of quickly prototyping new AI-driven UXs. For example, this script, (<1hr work with Cursor) will open a dedicated browswer that saves every job ad I open to a database [...]
This is nice. I got sidetracked by this, and accidentally spent 10 minutes ALMOST figuring out how to make this compatible with `+` and `|` operators. Make of that what you will.

March 6, 2025 at 9:02 PM
This is nice. I got sidetracked by this, and accidentally spent 10 minutes ALMOST figuring out how to make this compatible with `+` and `|` operators. Make of that what you will.
YES! I've been planning to write more about the importance of this stuff (largely, to be fair, for selfish reasons, since I'm a psycho methods-to-AI person, and I'm on the job market).
eointravers.com/blog/convo-e...
eointravers.com/blog/convo-e...

March 5, 2025 at 12:59 PM
YES! I've been planning to write more about the importance of this stuff (largely, to be fair, for selfish reasons, since I'm a psycho methods-to-AI person, and I'm on the job market).
eointravers.com/blog/convo-e...
eointravers.com/blog/convo-e...
TLDR: conversations are graphs, and each node contains a) a prompt guiding what the chatbot should say, and b) possible classifications for the user's resposne, dictating which node we go to next.
That's most of what you need!
That's most of what you need!

February 19, 2025 at 12:50 PM
TLDR: conversations are graphs, and each node contains a) a prompt guiding what the chatbot should say, and b) possible classifications for the user's resposne, dictating which node we go to next.
That's most of what you need!
That's most of what you need!
A fun post.
LLM prompt-based chatbots are easy and flexible, but hard to control. Rule-based bots give you control, but require more manual work and are inflexible. Is there a middle ground? Yes, and it involves graphs.
eointravers.com/blog/structu...
LLM prompt-based chatbots are easy and flexible, but hard to control. Rule-based bots give you control, but require more manual work and are inflexible. Is there a middle ground? Yes, and it involves graphs.
eointravers.com/blog/structu...

February 19, 2025 at 12:50 PM
A fun post.
LLM prompt-based chatbots are easy and flexible, but hard to control. Rule-based bots give you control, but require more manual work and are inflexible. Is there a middle ground? Yes, and it involves graphs.
eointravers.com/blog/structu...
LLM prompt-based chatbots are easy and flexible, but hard to control. Rule-based bots give you control, but require more manual work and are inflexible. Is there a middle ground? Yes, and it involves graphs.
eointravers.com/blog/structu...



LinkedIn, subscribing to the "Just make it a RAG chatbot" school of thought when it comes to AI features. 🥲


February 18, 2025 at 11:40 AM
LinkedIn, subscribing to the "Just make it a RAG chatbot" school of thought when it comes to AI features. 🥲
ref 4 (Argyle) seems to be suggesting generalising from LLMs to humans. Sorry for the rabbit hole, my question is just: Who is openly saying we should study LLMs in place of humans, so I can avoid them? Thanks!

February 18, 2025 at 11:29 AM
ref 4 (Argyle) seems to be suggesting generalising from LLMs to humans. Sorry for the rabbit hole, my question is just: Who is openly saying we should study LLMs in place of humans, so I can avoid them? Thanks!
As it happens, the original post (that, and my impending unemployment) prompted me to dig up and finish a similar piece I had been working on a few months ago, so I'm piggy-backing and sharing it here as well: eointravers.com/blog/ai-tran...

February 11, 2025 at 12:44 PM
As it happens, the original post (that, and my impending unemployment) prompted me to dig up and finish a similar piece I had been working on a few months ago, so I'm piggy-backing and sharing it here as well: eointravers.com/blog/ai-tran...
I go through my four main approaches: Testing individual mesages in isolation, testing messages with specified context, simulating conversations with a list of canned user messages, and full-blown LLM-on-LLM conversation simulation.




February 10, 2025 at 10:28 PM
I go through my four main approaches: Testing individual mesages in isolation, testing messages with specified context, simulating conversations with a list of canned user messages, and full-blown LLM-on-LLM conversation simulation.
New post: Evaluating Multi-Step Conversational AI is Hard (eointravers.com/blog/convo-e...)
TL;DR: Everyone [1] agrees that evals are crucial, but no one really knows how to do them for chatbots. I'm trying.
[1]: Well, e.g. @eugeneyan.com, @hamel.bsky.social, the other authors of applied-llms.org
TL;DR: Everyone [1] agrees that evals are crucial, but no one really knows how to do them for chatbots. I'm trying.
[1]: Well, e.g. @eugeneyan.com, @hamel.bsky.social, the other authors of applied-llms.org

February 10, 2025 at 10:28 PM
New post: Evaluating Multi-Step Conversational AI is Hard (eointravers.com/blog/convo-e...)
TL;DR: Everyone [1] agrees that evals are crucial, but no one really knows how to do them for chatbots. I'm trying.
[1]: Well, e.g. @eugeneyan.com, @hamel.bsky.social, the other authors of applied-llms.org
TL;DR: Everyone [1] agrees that evals are crucial, but no one really knows how to do them for chatbots. I'm trying.
[1]: Well, e.g. @eugeneyan.com, @hamel.bsky.social, the other authors of applied-llms.org
[I'm doing some messing around with docs.bsky.app, and this is a placeholder post]

February 6, 2025 at 2:14 PM
[I'm doing some messing around with docs.bsky.app, and this is a placeholder post]
I started writing some notes on how I think about the process of iterating on LLM prompts, and didn't know where to stop. The result? 2,500 words of possibly deranged thoughts social-technical systems, RL, product development, and more.
eointravers.com/blog/llm-pro...
eointravers.com/blog/llm-pro...

January 31, 2025 at 3:41 PM
I started writing some notes on how I think about the process of iterating on LLM prompts, and didn't know where to stop. The result? 2,500 words of possibly deranged thoughts social-technical systems, RL, product development, and more.
eointravers.com/blog/llm-pro...
eointravers.com/blog/llm-pro...
Currently experimenting with:
Using state machines to process LLM streaming outputs on the fly.
Using state machines to process LLM streaming outputs on the fly.



January 13, 2025 at 8:42 AM
Currently experimenting with:
Using state machines to process LLM streaming outputs on the fly.
Using state machines to process LLM streaming outputs on the fly.
Regularizing the subject estimates towards the group mean doesn't affect power though, it just improves estimates of subject-level parameters (I had the wrong intuition about this as well, but simulated it away).



December 30, 2024 at 5:55 PM
Regularizing the subject estimates towards the group mean doesn't affect power though, it just improves estimates of subject-level parameters (I had the wrong intuition about this as well, but simulated it away).
Consistent with the above, if we assume that "walking" doesn't include boarding a ferry to continental Europe, it's not possible to walk 500 miles from Leith in a straight line. They don't know where her door is, they're scouring the country to find it.

December 16, 2024 at 12:29 PM
Consistent with the above, if we assume that "walking" doesn't include boarding a ferry to continental Europe, it's not possible to walk 500 miles from Leith in a straight line. They don't know where her door is, they're scouring the country to find it.
There's always something to be said for good old ordering on the outcome variable.
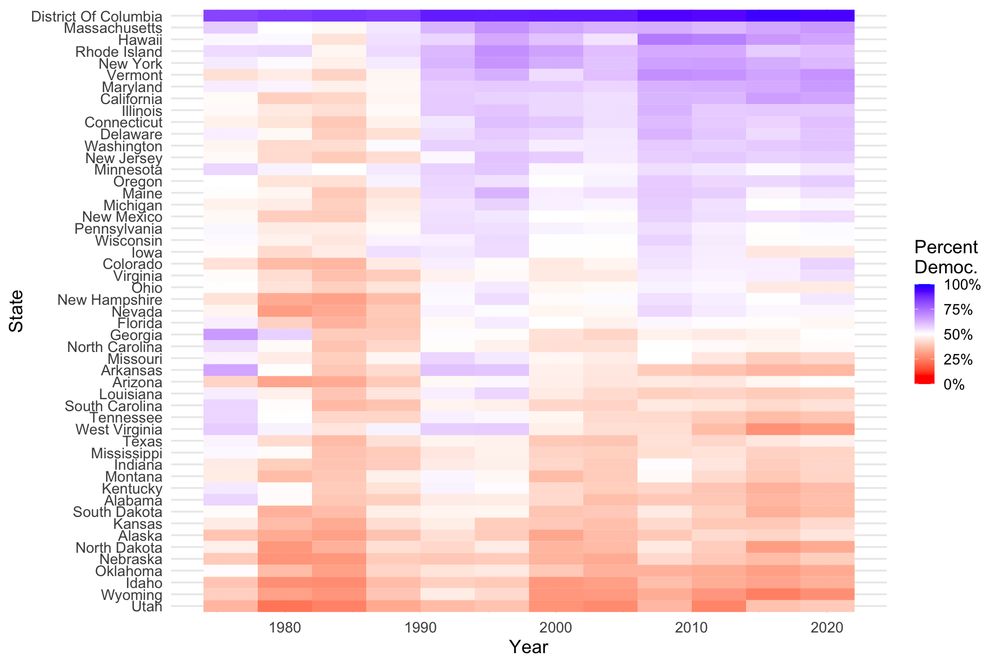
December 1, 2024 at 6:37 PM
There's always something to be said for good old ordering on the outcome variable.
Finally, tools can be configured to return different agents, letting us change (temporarily, or until further notice)
the agent that the user is interacting with (a "swarm" of agents, etc.).
the agent that the user is interacting with (a "swarm" of agents, etc.).



November 23, 2024 at 12:54 PM
Finally, tools can be configured to return different agents, letting us change (temporarily, or until further notice)
the agent that the user is interacting with (a "swarm" of agents, etc.).
the agent that the user is interacting with (a "swarm" of agents, etc.).