



Emmanouil Benetos
@emmanouilb.bsky.social
Reader in Machine Listening, @qmuleecs.bsky.social Queen Mary University of London - research on AI for audio. Website: https://www.seresearch.qmul.ac.uk/cmai/people/ebenetos/
Reposted by Emmanouil Benetos

Peeters, Rafii, Fuentes, Duan, Benetos, Nam, Mitsufuji: Twenty-Five Years of MIR Research: Achievements, Practices, Evaluations, and Future Challenges https://arxiv.org/abs/2511.07205 https://arxiv.org/pdf/2511.07205 https://arxiv.org/html/2511.07205
November 11, 2025 at 6:34 AM
Peeters, Rafii, Fuentes, Duan, Benetos, Nam, Mitsufuji: Twenty-Five Years of MIR Research: Achievements, Practices, Evaluations, and Future Challenges https://arxiv.org/abs/2511.07205 https://arxiv.org/pdf/2511.07205 https://arxiv.org/html/2511.07205
Reposted by Emmanouil Benetos
Termeh Taheri, Yinghao Ma, Emmanouil Benetos: SAR-LM: Symbolic Audio Reasoning with Large Language Models https://arxiv.org/abs/2511.06483 https://arxiv.org/pdf/2511.06483 https://arxiv.org/html/2511.06483
November 11, 2025 at 6:34 AM
Termeh Taheri, Yinghao Ma, Emmanouil Benetos: SAR-LM: Symbolic Audio Reasoning with Large Language Models https://arxiv.org/abs/2511.06483 https://arxiv.org/pdf/2511.06483 https://arxiv.org/html/2511.06483
Reposted by Emmanouil Benetos

📢 Join our Conversational AI Reading Group!
📅 Thursday, Nov 6th | 11 AM - 12 PM EST
🎙 Speaker: Emmanouil Benetos ( @emmanouilb.bsky.social ) - Queen Mary University of London
📖 Topic: "Machine learning paradigms for music and audio understanding"
🔗 Details: (poonehmousavi.github.io/rg)
📅 Thursday, Nov 6th | 11 AM - 12 PM EST
🎙 Speaker: Emmanouil Benetos ( @emmanouilb.bsky.social ) - Queen Mary University of London
📖 Topic: "Machine learning paradigms for music and audio understanding"
🔗 Details: (poonehmousavi.github.io/rg)
Pooneh Mousavi
Homepage of Pooneh Mousavi
poonehmousavi.github.io
November 3, 2025 at 6:48 PM
📢 Join our Conversational AI Reading Group!
📅 Thursday, Nov 6th | 11 AM - 12 PM EST
🎙 Speaker: Emmanouil Benetos ( @emmanouilb.bsky.social ) - Queen Mary University of London
📖 Topic: "Machine learning paradigms for music and audio understanding"
🔗 Details: (poonehmousavi.github.io/rg)
📅 Thursday, Nov 6th | 11 AM - 12 PM EST
🎙 Speaker: Emmanouil Benetos ( @emmanouilb.bsky.social ) - Queen Mary University of London
📖 Topic: "Machine learning paradigms for music and audio understanding"
🔗 Details: (poonehmousavi.github.io/rg)
Reposted by Emmanouil Benetos

🎶 [C4DM Seminar] Advancing Music Experience Through Music Information Research
🕒 3–4 PM, 5th November
📍 TBC
We’re excited to welcome Dr. Masataka Goto, Senior Principal Researcher at the National Institute of Advanced Industrial Science and Technology (AIST), Japan.
🕒 3–4 PM, 5th November
📍 TBC
We’re excited to welcome Dr. Masataka Goto, Senior Principal Researcher at the National Institute of Advanced Industrial Science and Technology (AIST), Japan.
October 31, 2025 at 11:47 AM
🎶 [C4DM Seminar] Advancing Music Experience Through Music Information Research
🕒 3–4 PM, 5th November
📍 TBC
We’re excited to welcome Dr. Masataka Goto, Senior Principal Researcher at the National Institute of Advanced Industrial Science and Technology (AIST), Japan.
🕒 3–4 PM, 5th November
📍 TBC
We’re excited to welcome Dr. Masataka Goto, Senior Principal Researcher at the National Institute of Advanced Industrial Science and Technology (AIST), Japan.
Reposted by Emmanouil Benetos

our inventor @antorrisi.bsky.social with poster on #VocalEcho: Closed-loop system for vocal interactions #BioDCASE at 12:21 CET (11.21 UK time) 🐥 🔀 🤖🎈
Streaming dcase.community/workshop2025...
@c4dm.bsky.social @emmanouilb.bsky.social @preparedmindslab.bsky.social @elisabettaversace.bsky.social
Streaming dcase.community/workshop2025...
@c4dm.bsky.social @emmanouilb.bsky.social @preparedmindslab.bsky.social @elisabettaversace.bsky.social


October 29, 2025 at 10:11 AM
our inventor @antorrisi.bsky.social with poster on #VocalEcho: Closed-loop system for vocal interactions #BioDCASE at 12:21 CET (11.21 UK time) 🐥 🔀 🤖🎈
Streaming dcase.community/workshop2025...
@c4dm.bsky.social @emmanouilb.bsky.social @preparedmindslab.bsky.social @elisabettaversace.bsky.social
Streaming dcase.community/workshop2025...
@c4dm.bsky.social @emmanouilb.bsky.social @preparedmindslab.bsky.social @elisabettaversace.bsky.social
Reposted by Emmanouil Benetos
Aditya Bhattacharjee, Marco Pasini, Emmanouil Benetos: Scalable Evaluation for Audio Identification via Synthetic Latent Fingerprint Generation https://arxiv.org/abs/2509.18620 https://arxiv.org/pdf/2509.18620 https://arxiv.org/html/2509.18620
September 24, 2025 at 6:34 AM
Aditya Bhattacharjee, Marco Pasini, Emmanouil Benetos: Scalable Evaluation for Audio Identification via Synthetic Latent Fingerprint Generation https://arxiv.org/abs/2509.18620 https://arxiv.org/pdf/2509.18620 https://arxiv.org/html/2509.18620
Reposted by Emmanouil Benetos

New preprint on "Computational Hermeneutics," co-authored by too many people to list in one post. TL;DR: GenAI is a cultural technology, and needs to be evaluated in ways that recognize situatedness, plurality, and ambiguity as the conditions of meaning — not noise to be minimized.
Computational Hermeneutics: Evaluating Generative AI as a Cultural Technology
<div>
<div>
<div>
<p>Generative AI (GenAI) systems are increasingly recognized as cultural technologies, yet current evaluation frameworks often treat cul
papers.ssrn.com
August 29, 2025 at 3:41 PM
New preprint on "Computational Hermeneutics," co-authored by too many people to list in one post. TL;DR: GenAI is a cultural technology, and needs to be evaluated in ways that recognize situatedness, plurality, and ambiguity as the conditions of meaning — not noise to be minimized.
Reposted by Emmanouil Benetos
Sungkyun Chang, Simon Dixon, Emmanouil Benetos: RUMAA: Repeat-Aware Unified Music Audio Analysis for Score-Performance Alignment, Transcription, and Mistake Detection https://arxiv.org/abs/2507.12175 https://arxiv.org/pdf/2507.12175 https://arxiv.org/html/2507.12175
July 17, 2025 at 6:35 AM
Sungkyun Chang, Simon Dixon, Emmanouil Benetos: RUMAA: Repeat-Aware Unified Music Audio Analysis for Score-Performance Alignment, Transcription, and Mistake Detection https://arxiv.org/abs/2507.12175 https://arxiv.org/pdf/2507.12175 https://arxiv.org/html/2507.12175
Reposted by Emmanouil Benetos
Ludovic Tuncay, Etienne Labb\'e, Emmanouil Benetos, Thomas Pellegrini: Audio-JEPA: Joint-Embedding Predictive Architecture for Audio Representation Learning https://arxiv.org/abs/2507.02915 https://arxiv.org/pdf/2507.02915 https://arxiv.org/html/2507.02915
July 8, 2025 at 6:34 AM
Ludovic Tuncay, Etienne Labb\'e, Emmanouil Benetos, Thomas Pellegrini: Audio-JEPA: Joint-Embedding Predictive Architecture for Audio Representation Learning https://arxiv.org/abs/2507.02915 https://arxiv.org/pdf/2507.02915 https://arxiv.org/html/2507.02915
Reposted by Emmanouil Benetos

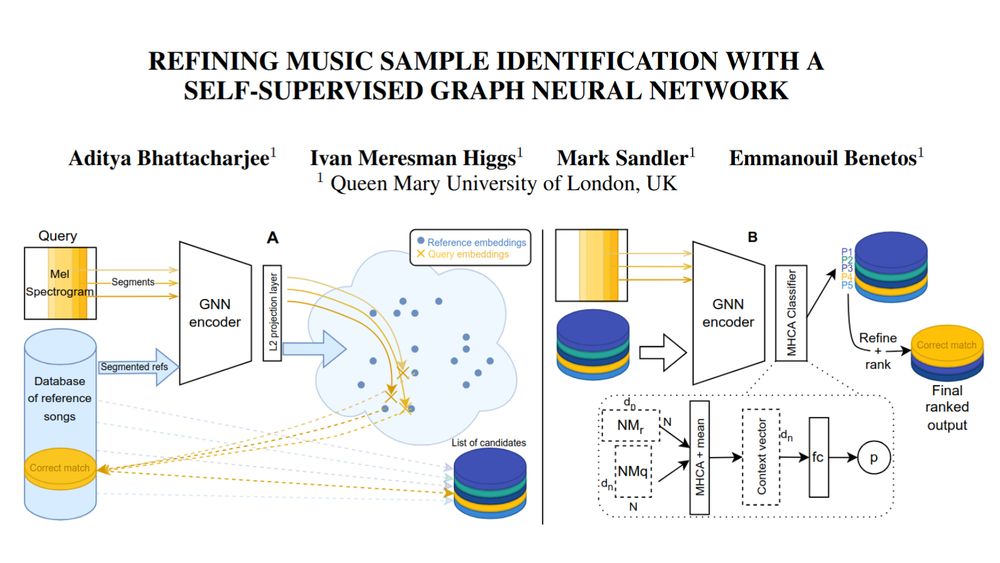
Our paper on automatic sample identification (arxiv.org/abs/2506.14684) was accepted at @ismir_conf 2025! 🎵🎶
We propose an architecture that can detect music samples that have been reused in new compositions, even after pitch-shifting, time-stretching, and other transformations!🧵
We propose an architecture that can detect music samples that have been reused in new compositions, even after pitch-shifting, time-stretching, and other transformations!🧵
June 25, 2025 at 10:45 AM
Our paper on automatic sample identification (arxiv.org/abs/2506.14684) was accepted at @ismir_conf 2025! 🎵🎶
We propose an architecture that can detect music samples that have been reused in new compositions, even after pitch-shifting, time-stretching, and other transformations!🧵
We propose an architecture that can detect music samples that have been reused in new compositions, even after pitch-shifting, time-stretching, and other transformations!🧵
Reposted by Emmanouil Benetos

CMI-Bench, a comprehensive music instruction following benchmark, evaluates audio-text LLMs on diverse MIR tasks, revealing performance gaps compared to supervised models and biases.
CMI-Bench: A Comprehensive Benchmark for Evaluating Music Instruction Following
Yinghao Ma, Siyou Li, Juntao Yu, Emmanouil Benetos, Akira Maezawa
arxiv.org
June 17, 2025 at 8:22 AM
CMI-Bench, a comprehensive music instruction following benchmark, evaluates audio-text LLMs on diverse MIR tasks, revealing performance gaps compared to supervised models and biases.
Reposted by Emmanouil Benetos
🎉 Congrats to Sungkyun Chang, Simon Dixon, and Emmanouil Benetos — their submission earned 2nd place at the 2025 Automatic Music Transcription Challenge! 🥈
ai4musicians.org/transcriptio...
#C4DM #MusicAI #AMTChallenge2025.
ai4musicians.org/transcriptio...
#C4DM #MusicAI #AMTChallenge2025.
Leaderboard
ai4musicians.org
June 6, 2025 at 8:24 AM
🎉 Congrats to Sungkyun Chang, Simon Dixon, and Emmanouil Benetos — their submission earned 2nd place at the 2025 Automatic Music Transcription Challenge! 🥈
ai4musicians.org/transcriptio...
#C4DM #MusicAI #AMTChallenge2025.
ai4musicians.org/transcriptio...
#C4DM #MusicAI #AMTChallenge2025.
Reposted by Emmanouil Benetos
**Lyrics Transcription:** Consistency loss aligns vocal and mixture encoder representations, improving transcription on music mixtures.
Enhancing Lyrics Transcription on Music Mixtures with Consistency Loss
Jiawen Huang, Felipe Sousa, Emir Demirel, Emmanouil Benetos, Igor Gadelha
arxiv.org
June 4, 2025 at 9:02 AM
**Lyrics Transcription:** Consistency loss aligns vocal and mixture encoder representations, improving transcription on music mixtures.
Reposted by Emmanouil Benetos

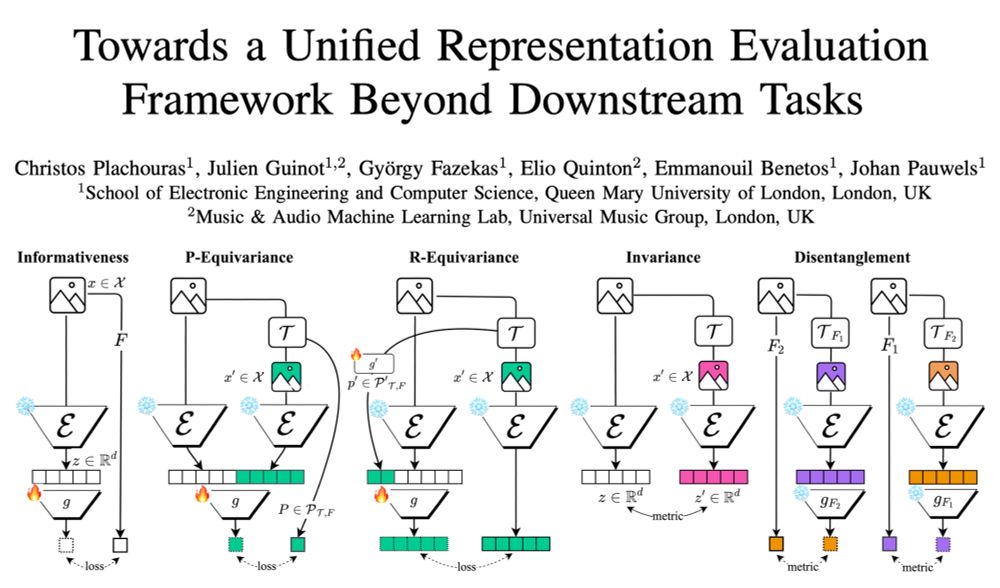
Excited to share our new paper: arxiv.org/abs/2505.06224! We introduce a unified framework for evaluating model representations beyond downstream tasks, and use it to uncover some interesting insights about the structure of representations that challenge conventional wisdom 🔍🧵
May 13, 2025 at 2:15 PM
Excited to share our new paper: arxiv.org/abs/2505.06224! We introduce a unified framework for evaluating model representations beyond downstream tasks, and use it to uncover some interesting insights about the structure of representations that challenge conventional wisdom 🔍🧵
Reposted by Emmanouil Benetos
how much music data do we actually need to pretrain effective music representation learning models? we decided to systematically investigate this in our latest #ICASSP2025 paper with @emmanouilb.bsky.social and Johan Pauwels

April 10, 2025 at 7:56 AM
how much music data do we actually need to pretrain effective music representation learning models? we decided to systematically investigate this in our latest #ICASSP2025 paper with @emmanouilb.bsky.social and Johan Pauwels
Reposted by Emmanouil Benetos
We are very thrilled to share our contributions to this year's ICASSP - 14 papers!
For a list of the articles, please refer to:
www.c4dm.eecs.qmul.ac.uk/news/2025-03...
For a list of the articles, please refer to:
www.c4dm.eecs.qmul.ac.uk/news/2025-03...

As in previous years, the Centre for Digital Music will have a strong presence at the conference, both in terms of numbers and overall impact. The below papers authored or co-authored by C4DM members will be presented at the main ICASSP 2025 track:
www.c4dm.eecs.qmul.ac.uk
March 25, 2025 at 11:31 AM
We are very thrilled to share our contributions to this year's ICASSP - 14 papers!
For a list of the articles, please refer to:
www.c4dm.eecs.qmul.ac.uk/news/2025-03...
For a list of the articles, please refer to:
www.c4dm.eecs.qmul.ac.uk/news/2025-03...
Reposted by Emmanouil Benetos

Exciting research update! EECS PhD students have developed a novel approach that enables large language models (LLMs) to “hear” and “understand” sound - a breakthrough in multimodal generative #AI: www.qmul.ac.uk/eecs/news-an...

EECS PhD researcher pioneers AI that can
www.qmul.ac.uk
March 20, 2025 at 12:22 PM
Exciting research update! EECS PhD students have developed a novel approach that enables large language models (LLMs) to “hear” and “understand” sound - a breakthrough in multimodal generative #AI: www.qmul.ac.uk/eecs/news-an...
Reposted by Emmanouil Benetos
Introduced Audio-FLAN, a large-scale instruction-tuning dataset for unified audio-language models; dataset covers 80 tasks and over 100 million instances, available on HuggingFace and GitHub.
Audio-FLAN: A Preliminary Release
Liumeng Xue, Ziya Zhou, Jiahao Pan, Zixuan Li, Shuai Fan, Yinghao Ma, Sitong Cheng, Dongchao Yang, Haohan Guo, Yujia Xiao, Xinsheng Wang, Zixuan Shen, Chuanbo Zhu, Xinshen Zhang, Tianchi Liu, Ruibin Yuan, Zeyue Tian, Haohe Liu, Emmanouil Benetos, Ge Zhang, Yike Guo, Wei Xue
arxiv.org
February 25, 2025 at 9:12 AM
Introduced Audio-FLAN, a large-scale instruction-tuning dataset for unified audio-language models; dataset covers 80 tasks and over 100 million instances, available on HuggingFace and GitHub.
Reposted by Emmanouil Benetos
Next Tuesday, 3/12 at 2pm, we will host a seminar by Manvi Agarwal on 'Fast Structure-informed Positional Encoding for Music Generation'.
More info at:
www.c4dm.eecs.qmul.ac.uk/news/2024-03...
More info at:
www.c4dm.eecs.qmul.ac.uk/news/2024-03...
November 28, 2024 at 12:42 PM
Next Tuesday, 3/12 at 2pm, we will host a seminar by Manvi Agarwal on 'Fast Structure-informed Positional Encoding for Music Generation'.
More info at:
www.c4dm.eecs.qmul.ac.uk/news/2024-03...
More info at:
www.c4dm.eecs.qmul.ac.uk/news/2024-03...