



Eliya Habba
@eliyahabba.bsky.social
PhD student at Hebrew University #HebrewU #NLP
3. Some instances are consistently easy or hard across ALL prompts, no matter how you prompt: models either always succeed or consistently fail.

March 17, 2025 at 2:39 PM
3. Some instances are consistently easy or hard across ALL prompts, no matter how you prompt: models either always succeed or consistently fail.
2. Selecting prompt characteristics (e.g., phrasing, enumerators) based on past examples helps efficiently find optimal prompts.

March 17, 2025 at 2:39 PM
2. Selecting prompt characteristics (e.g., phrasing, enumerators) based on past examples helps efficiently find optimal prompts.
Key findings from 🕊️ DOVE:
1. Prompt sensitivity is HUGE! Performance varies dramatically with small changes (e. g. ➡ OLMo’s accuracy on HellaSwag ranges from 1% to 99%, simply by changing prompt elements like phrasing, enumerators, and answer order).
1. Prompt sensitivity is HUGE! Performance varies dramatically with small changes (e. g. ➡ OLMo’s accuracy on HellaSwag ranges from 1% to 99%, simply by changing prompt elements like phrasing, enumerators, and answer order).

March 17, 2025 at 2:38 PM
Key findings from 🕊️ DOVE:
1. Prompt sensitivity is HUGE! Performance varies dramatically with small changes (e. g. ➡ OLMo’s accuracy on HellaSwag ranges from 1% to 99%, simply by changing prompt elements like phrasing, enumerators, and answer order).
1. Prompt sensitivity is HUGE! Performance varies dramatically with small changes (e. g. ➡ OLMo’s accuracy on HellaSwag ranges from 1% to 99%, simply by changing prompt elements like phrasing, enumerators, and answer order).
Goal: democratize LLM evaluation research and build meaningful, generalizable methods.
Talk to us about data you'd like to contribute or request evaluations you want to see added to 🕊️ DOVE!
Talk to us about data you'd like to contribute or request evaluations you want to see added to 🕊️ DOVE!
March 17, 2025 at 2:38 PM
Goal: democratize LLM evaluation research and build meaningful, generalizable methods.
Talk to us about data you'd like to contribute or request evaluations you want to see added to 🕊️ DOVE!
Talk to us about data you'd like to contribute or request evaluations you want to see added to 🕊️ DOVE!
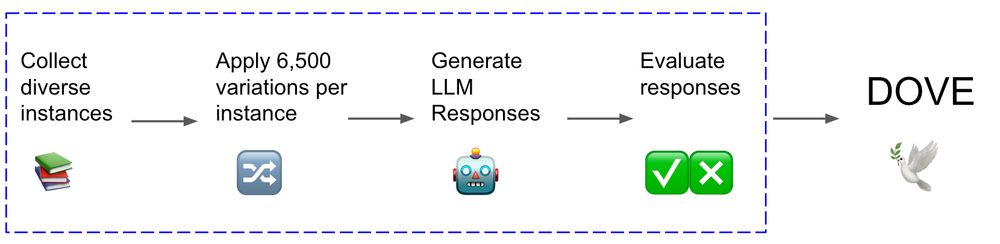
Care about LLM evaluation? 🤖 🤔
We bring you ️️🕊️ DOVE a massive (250M!) collection of LLMs outputs
On different prompts, domains, tokens, models...
Join our community effort to expand it with YOUR model predictions & become a co-author!
We bring you ️️🕊️ DOVE a massive (250M!) collection of LLMs outputs
On different prompts, domains, tokens, models...
Join our community effort to expand it with YOUR model predictions & become a co-author!
March 17, 2025 at 2:37 PM
Care about LLM evaluation? 🤖 🤔
We bring you ️️🕊️ DOVE a massive (250M!) collection of LLMs outputs
On different prompts, domains, tokens, models...
Join our community effort to expand it with YOUR model predictions & become a co-author!
We bring you ️️🕊️ DOVE a massive (250M!) collection of LLMs outputs
On different prompts, domains, tokens, models...
Join our community effort to expand it with YOUR model predictions & become a co-author!