



Elie
@eliebak.hf.co
Training LLM's at huggingface | hf.co/science
WOW, Gemini Flash 2.0 is really impressive. Wondering about the size of this supposedly smol model.
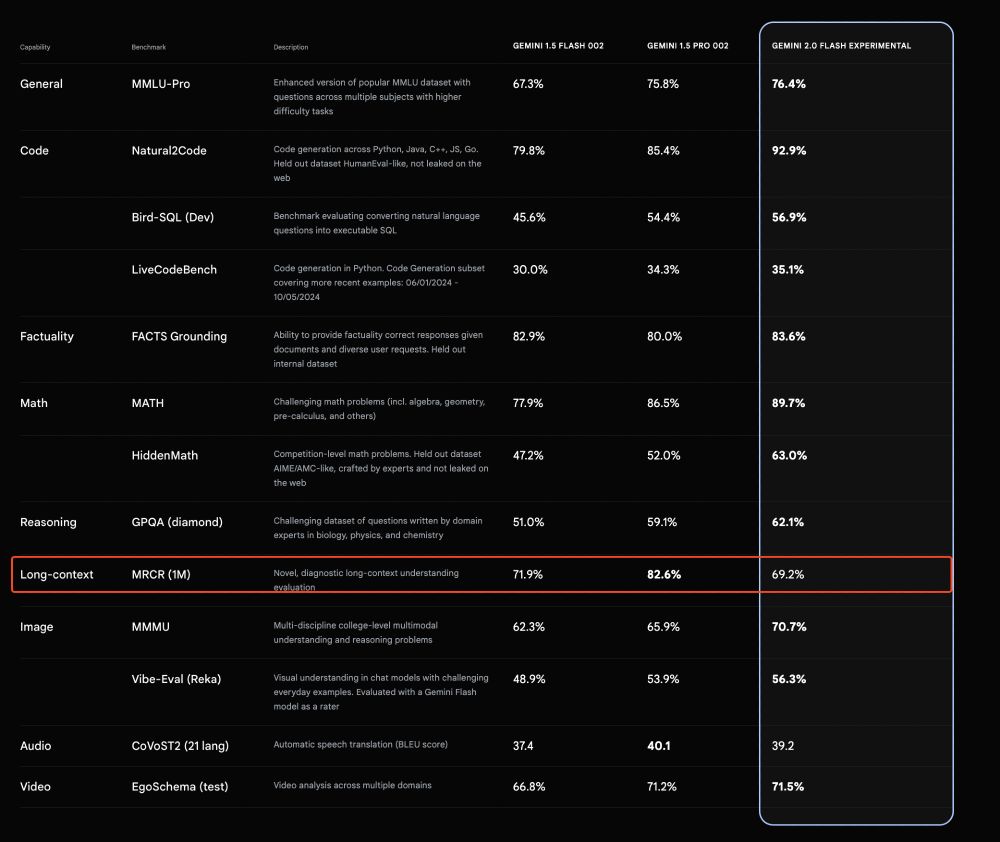
One odd thing is that the model seems to lose some ability with long contexts compared to Flash 1.5. If any google friends could share insights, I'd love to hear them!
One odd thing is that the model seems to lose some ability with long contexts compared to Flash 1.5. If any google friends could share insights, I'd love to hear them!
December 11, 2024 at 4:19 PM
WOW, Gemini Flash 2.0 is really impressive. Wondering about the size of this supposedly smol model.
One odd thing is that the model seems to lose some ability with long contexts compared to Flash 1.5. If any google friends could share insights, I'd love to hear them!
One odd thing is that the model seems to lose some ability with long contexts compared to Flash 1.5. If any google friends could share insights, I'd love to hear them!
Google patent on "Training of large neural network". 😮
I don't know if this give much information but by going quickly through it seems that:
- They are not only using "causal language modeling task" as a pre-training task but also "span corruption" and "prefix modeling". (ref [0805]-[0091])
I don't know if this give much information but by going quickly through it seems that:
- They are not only using "causal language modeling task" as a pre-training task but also "span corruption" and "prefix modeling". (ref [0805]-[0091])

December 3, 2024 at 11:11 AM
Google patent on "Training of large neural network". 😮
I don't know if this give much information but by going quickly through it seems that:
- They are not only using "causal language modeling task" as a pre-training task but also "span corruption" and "prefix modeling". (ref [0805]-[0091])
I don't know if this give much information but by going quickly through it seems that:
- They are not only using "causal language modeling task" as a pre-training task but also "span corruption" and "prefix modeling". (ref [0805]-[0091])
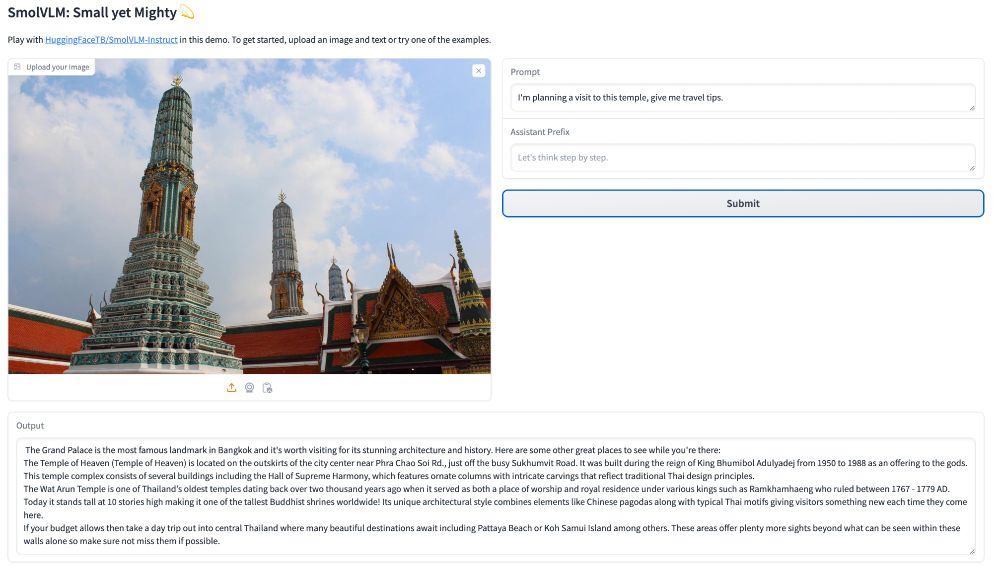
The SmolLM series has a new member: say hi to SmolVLM! 🤏
It uses a preliminary 16k context version of SmolLM2 to tackle long-context vision documents and higher-res images.
And yes, we’re cooking up versions with bigger context lengths. 👨🍳
Try it yourself here: huggingface.co/spaces/Huggi...
It uses a preliminary 16k context version of SmolLM2 to tackle long-context vision documents and higher-res images.
And yes, we’re cooking up versions with bigger context lengths. 👨🍳
Try it yourself here: huggingface.co/spaces/Huggi...
November 26, 2024 at 4:47 PM
The SmolLM series has a new member: say hi to SmolVLM! 🤏
It uses a preliminary 16k context version of SmolLM2 to tackle long-context vision documents and higher-res images.
And yes, we’re cooking up versions with bigger context lengths. 👨🍳
Try it yourself here: huggingface.co/spaces/Huggi...
It uses a preliminary 16k context version of SmolLM2 to tackle long-context vision documents and higher-res images.
And yes, we’re cooking up versions with bigger context lengths. 👨🍳
Try it yourself here: huggingface.co/spaces/Huggi...
Hey babe, wake up, we just dropped a new SmolLM 🫡
Fully open-source. We’ll release a blog post soon to detail how we trained it. I'm also super excited about all the demos that will come in the next few days, especially looking forward for people to test it with entropix 🐸
Fully open-source. We’ll release a blog post soon to detail how we trained it. I'm also super excited about all the demos that will come in the next few days, especially looking forward for people to test it with entropix 🐸

October 31, 2024 at 7:35 PM
Hey babe, wake up, we just dropped a new SmolLM 🫡
Fully open-source. We’ll release a blog post soon to detail how we trained it. I'm also super excited about all the demos that will come in the next few days, especially looking forward for people to test it with entropix 🐸
Fully open-source. We’ll release a blog post soon to detail how we trained it. I'm also super excited about all the demos that will come in the next few days, especially looking forward for people to test it with entropix 🐸