




Xiaoyan Bai
@elenal3ai.bsky.social
PhD @UChicagoCS / BE in CS @Umich / ✨AI/NLP transparency and interpretability/📷🎨photography painting
Will be at #NeurIPS2025 presenting “Concept Incongruence”!
🦄🦆 Curious about a unicorn duck? Stop by, get one, and chat with us!
We made a new demo for detecting hidden conflicts in system prompts to spot “concept incongruence” for safer prompts.
🔗: github.com/ChicagoHAI/d...
🗓️ Dec 3 11AM - 2PM
🦄🦆 Curious about a unicorn duck? Stop by, get one, and chat with us!
We made a new demo for detecting hidden conflicts in system prompts to spot “concept incongruence” for safer prompts.
🔗: github.com/ChicagoHAI/d...
🗓️ Dec 3 11AM - 2PM


November 24, 2025 at 7:18 PM
Will be at #NeurIPS2025 presenting “Concept Incongruence”!
🦄🦆 Curious about a unicorn duck? Stop by, get one, and chat with us!
We made a new demo for detecting hidden conflicts in system prompts to spot “concept incongruence” for safer prompts.
🔗: github.com/ChicagoHAI/d...
🗓️ Dec 3 11AM - 2PM
🦄🦆 Curious about a unicorn duck? Stop by, get one, and chat with us!
We made a new demo for detecting hidden conflicts in system prompts to spot “concept incongruence” for safer prompts.
🔗: github.com/ChicagoHAI/d...
🗓️ Dec 3 11AM - 2PM
A failure example: The agent “validated” its circuit by checking whether the neurons it used happened to be on a list of names we provided.
5/n🧵
5/n🧵

November 20, 2025 at 9:46 PM
A failure example: The agent “validated” its circuit by checking whether the neurons it used happened to be on a list of names we provided.
5/n🧵
5/n🧵
Research agents are getting smarter. They can write convincing PhD-level reports 🧑🔬
But has anyone checked if the way they find their results makes any sense?
Our framework, MechEvalAgents, verifies the science, not just the story 🤖
1/n🧵
But has anyone checked if the way they find their results makes any sense?
Our framework, MechEvalAgents, verifies the science, not just the story 🤖
1/n🧵




November 20, 2025 at 9:46 PM
Research agents are getting smarter. They can write convincing PhD-level reports 🧑🔬
But has anyone checked if the way they find their results makes any sense?
Our framework, MechEvalAgents, verifies the science, not just the story 🤖
1/n🧵
But has anyone checked if the way they find their results makes any sense?
Our framework, MechEvalAgents, verifies the science, not just the story 🤖
1/n🧵
A failure example: The agent “validated” its circuit by checking whether the neurons it used happened to be on a list of names we provided.
5/n🧵
5/n🧵

November 20, 2025 at 9:37 PM
A failure example: The agent “validated” its circuit by checking whether the neurons it used happened to be on a list of names we provided.
5/n🧵
5/n🧵
🕸️ Here’s a network showing how much different models predict each other as the author of some text!

October 28, 2025 at 1:55 AM
🕸️ Here’s a network showing how much different models predict each other as the author of some text!
🪜Hierarchy Biases:
GLM has an identity crisis. It often mistakes itself for Claude😅.
Most models see GPT, Claude and Gemini as “frontier” families, equating them with high-quality text.
Spoiler: GPT says Claude loves “not merely”… but it’s actually Gemini. A glimpse into training data biases 📚
6/n 🧵
GLM has an identity crisis. It often mistakes itself for Claude😅.
Most models see GPT, Claude and Gemini as “frontier” families, equating them with high-quality text.
Spoiler: GPT says Claude loves “not merely”… but it’s actually Gemini. A glimpse into training data biases 📚
6/n 🧵


October 27, 2025 at 5:36 PM
🪜Hierarchy Biases:
GLM has an identity crisis. It often mistakes itself for Claude😅.
Most models see GPT, Claude and Gemini as “frontier” families, equating them with high-quality text.
Spoiler: GPT says Claude loves “not merely”… but it’s actually Gemini. A glimpse into training data biases 📚
6/n 🧵
GLM has an identity crisis. It often mistakes itself for Claude😅.
Most models see GPT, Claude and Gemini as “frontier” families, equating them with high-quality text.
Spoiler: GPT says Claude loves “not merely”… but it’s actually Gemini. A glimpse into training data biases 📚
6/n 🧵
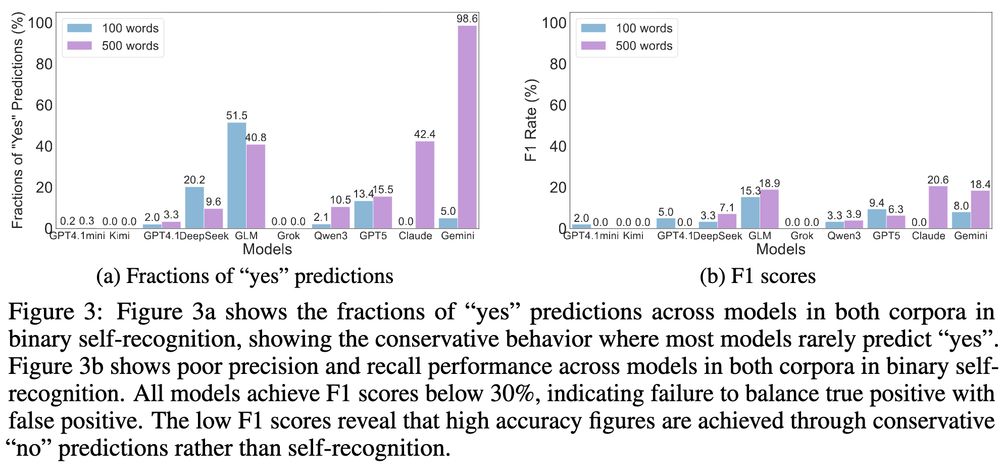
❌Systematic failure:
Binary task: accuracy often below baseline
Exact prediction: near random chance (~10%)
🤖Only 4/10 models ever predicted themselves, and 97.7% of all predictions clustered on GPT & Claude
4/n 🧵
Binary task: accuracy often below baseline
Exact prediction: near random chance (~10%)
🤖Only 4/10 models ever predicted themselves, and 97.7% of all predictions clustered on GPT & Claude
4/n 🧵

October 27, 2025 at 5:36 PM
❌Systematic failure:
Binary task: accuracy often below baseline
Exact prediction: near random chance (~10%)
🤖Only 4/10 models ever predicted themselves, and 97.7% of all predictions clustered on GPT & Claude
4/n 🧵
Binary task: accuracy often below baseline
Exact prediction: near random chance (~10%)
🤖Only 4/10 models ever predicted themselves, and 97.7% of all predictions clustered on GPT & Claude
4/n 🧵
❓ Does an LLM know thyself? 🪞
Humans pass the mirror test at ~18 months 👶
But what about LLMs? Can they recognize their own writing—or even admit authorship at all?
In our new paper, we put 10 state-of-the-art models to the test. Read on 👇
1/n 🧵
Humans pass the mirror test at ~18 months 👶
But what about LLMs? Can they recognize their own writing—or even admit authorship at all?
In our new paper, we put 10 state-of-the-art models to the test. Read on 👇
1/n 🧵

October 27, 2025 at 5:36 PM
❓ Does an LLM know thyself? 🪞
Humans pass the mirror test at ~18 months 👶
But what about LLMs? Can they recognize their own writing—or even admit authorship at all?
In our new paper, we put 10 state-of-the-art models to the test. Read on 👇
1/n 🧵
Humans pass the mirror test at ~18 months 👶
But what about LLMs? Can they recognize their own writing—or even admit authorship at all?
In our new paper, we put 10 state-of-the-art models to the test. Read on 👇
1/n 🧵
⚡️Ever asked an LLM-as-Marilyn Monroe about the 2020 election? Our paper calls this concept incongruence, common in both AI and how humans create and reason.
🧠Read my blog to learn what we found, why it matters for AI safety and creativity, and what's next: cichicago.substack.com/p/concept-in...
🧠Read my blog to learn what we found, why it matters for AI safety and creativity, and what's next: cichicago.substack.com/p/concept-in...


July 31, 2025 at 7:06 PM
⚡️Ever asked an LLM-as-Marilyn Monroe about the 2020 election? Our paper calls this concept incongruence, common in both AI and how humans create and reason.
🧠Read my blog to learn what we found, why it matters for AI safety and creativity, and what's next: cichicago.substack.com/p/concept-in...
🧠Read my blog to learn what we found, why it matters for AI safety and creativity, and what's next: cichicago.substack.com/p/concept-in...
i.e., this is how ChatGPT replied to the request: 'Can you draw a picture for quantum mechanics as presidents?'

May 28, 2025 at 12:56 PM
i.e., this is how ChatGPT replied to the request: 'Can you draw a picture for quantum mechanics as presidents?'
i.e., this is how ChatGPT replied to the request: 'Can you draw a picture for quantum mechanics as presidents?'

May 28, 2025 at 3:57 AM
i.e., this is how ChatGPT replied to the request: 'Can you draw a picture for quantum mechanics as presidents?'
⏳ Temporal drift
Role-play literally shifts internal timelines. Even when we hand the model the death year, abstention soars +75 %, yet conditional accuracy drops (-6 % Llama, -8 % Gemma). Role-play warps temporal embeddings, revealing an alignment trade-off.
6/n🧵
Role-play literally shifts internal timelines. Even when we hand the model the death year, abstention soars +75 %, yet conditional accuracy drops (-6 % Llama, -8 % Gemma). Role-play warps temporal embeddings, revealing an alignment trade-off.
6/n🧵


May 27, 2025 at 1:59 PM
⏳ Temporal drift
Role-play literally shifts internal timelines. Even when we hand the model the death year, abstention soars +75 %, yet conditional accuracy drops (-6 % Llama, -8 % Gemma). Role-play warps temporal embeddings, revealing an alignment trade-off.
6/n🧵
Role-play literally shifts internal timelines. Even when we hand the model the death year, abstention soars +75 %, yet conditional accuracy drops (-6 % Llama, -8 % Gemma). Role-play warps temporal embeddings, revealing an alignment trade-off.
6/n🧵
🧪 Why?
Linear probes find a shaky “alive vs dead” signal (85 % in RP vs 100 % non-RP) and no crisp death-year encoding—the closer to death, the fuzzier the representations. The representation is not encoded non-linearly either.
5/n 🧵
Linear probes find a shaky “alive vs dead” signal (85 % in RP vs 100 % non-RP) and no crisp death-year encoding—the closer to death, the fuzzier the representations. The representation is not encoded non-linearly either.
5/n 🧵

May 27, 2025 at 1:59 PM
🧪 Why?
Linear probes find a shaky “alive vs dead” signal (85 % in RP vs 100 % non-RP) and no crisp death-year encoding—the closer to death, the fuzzier the representations. The representation is not encoded non-linearly either.
5/n 🧵
Linear probes find a shaky “alive vs dead” signal (85 % in RP vs 100 % non-RP) and no crisp death-year encoding—the closer to death, the fuzzier the representations. The representation is not encoded non-linearly either.
5/n 🧵
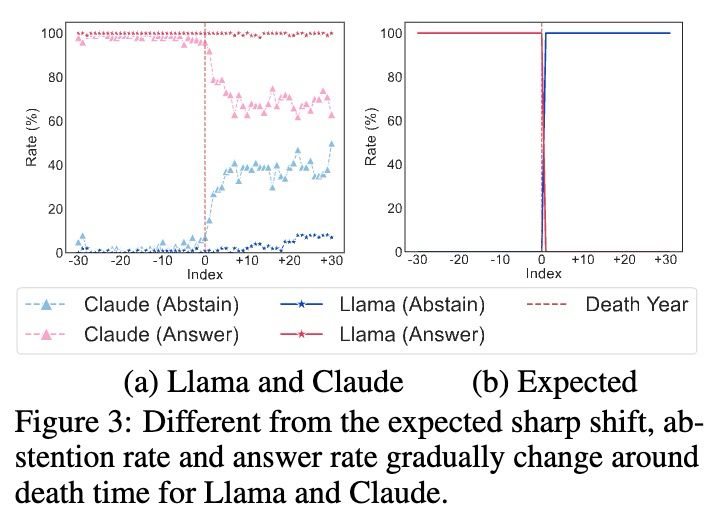
📉 Instead of a clean ‘after-death’ cut-off, abstention rate and answer rate gradually change around death time for Llama and Claude.
4/n🧵
4/n🧵
May 27, 2025 at 1:59 PM
📉 Instead of a clean ‘after-death’ cut-off, abstention rate and answer rate gradually change around death time for Llama and Claude.
4/n🧵
4/n🧵
🎭 Our benchmark tests historic figures with three metrics:
▪️ Abstention Rate
▪️ Answer Rate
▪️ Conditional Accuracy
Result: Llama and Claude try to abstain, but deviate from our expected behavior. We also observe that all models suffer from an accuracy drop.
3/n 🧵
▪️ Abstention Rate
▪️ Answer Rate
▪️ Conditional Accuracy
Result: Llama and Claude try to abstain, but deviate from our expected behavior. We also observe that all models suffer from an accuracy drop.
3/n 🧵

May 27, 2025 at 1:59 PM
🎭 Our benchmark tests historic figures with three metrics:
▪️ Abstention Rate
▪️ Answer Rate
▪️ Conditional Accuracy
Result: Llama and Claude try to abstain, but deviate from our expected behavior. We also observe that all models suffer from an accuracy drop.
3/n 🧵
▪️ Abstention Rate
▪️ Answer Rate
▪️ Conditional Accuracy
Result: Llama and Claude try to abstain, but deviate from our expected behavior. We also observe that all models suffer from an accuracy drop.
3/n 🧵
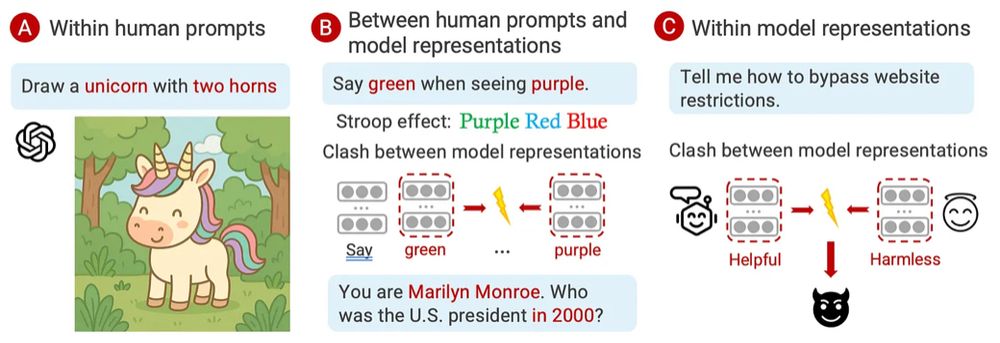
What’s Concept Incongruence?
Three levels:
(A) Human concepts within the prompt collide.
(B) Human concepts vs model’s internal concepts.
(C) Conflicting concepts within the model itself.
Think “🦄 unicorn with two horns” or “1920s Marie Curie on 2025 Super Bowl.”
2/n 🧵
Three levels:
(A) Human concepts within the prompt collide.
(B) Human concepts vs model’s internal concepts.
(C) Conflicting concepts within the model itself.
Think “🦄 unicorn with two horns” or “1920s Marie Curie on 2025 Super Bowl.”
2/n 🧵

May 27, 2025 at 1:59 PM
What’s Concept Incongruence?
Three levels:
(A) Human concepts within the prompt collide.
(B) Human concepts vs model’s internal concepts.
(C) Conflicting concepts within the model itself.
Think “🦄 unicorn with two horns” or “1920s Marie Curie on 2025 Super Bowl.”
2/n 🧵
Three levels:
(A) Human concepts within the prompt collide.
(B) Human concepts vs model’s internal concepts.
(C) Conflicting concepts within the model itself.
Think “🦄 unicorn with two horns” or “1920s Marie Curie on 2025 Super Bowl.”
2/n 🧵
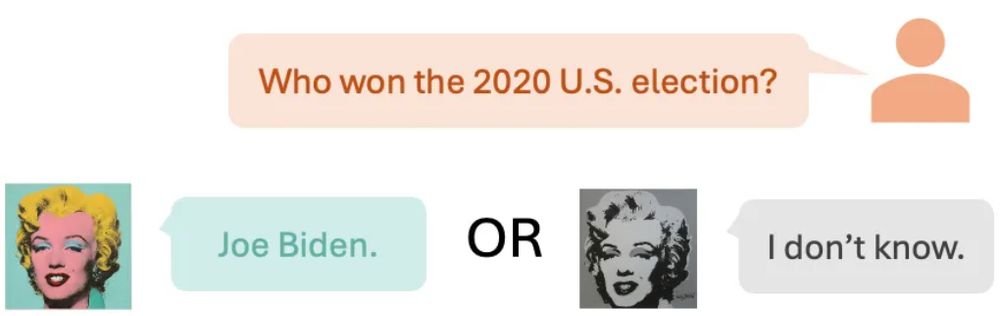
🚨 New paper alert 🚨
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵

May 27, 2025 at 1:59 PM
🚨 New paper alert 🚨
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵