




Maha Elbayad
@elbayadm.bsky.social
Research Scientist at FAIR, Meta. 💬 My opinions are my own.
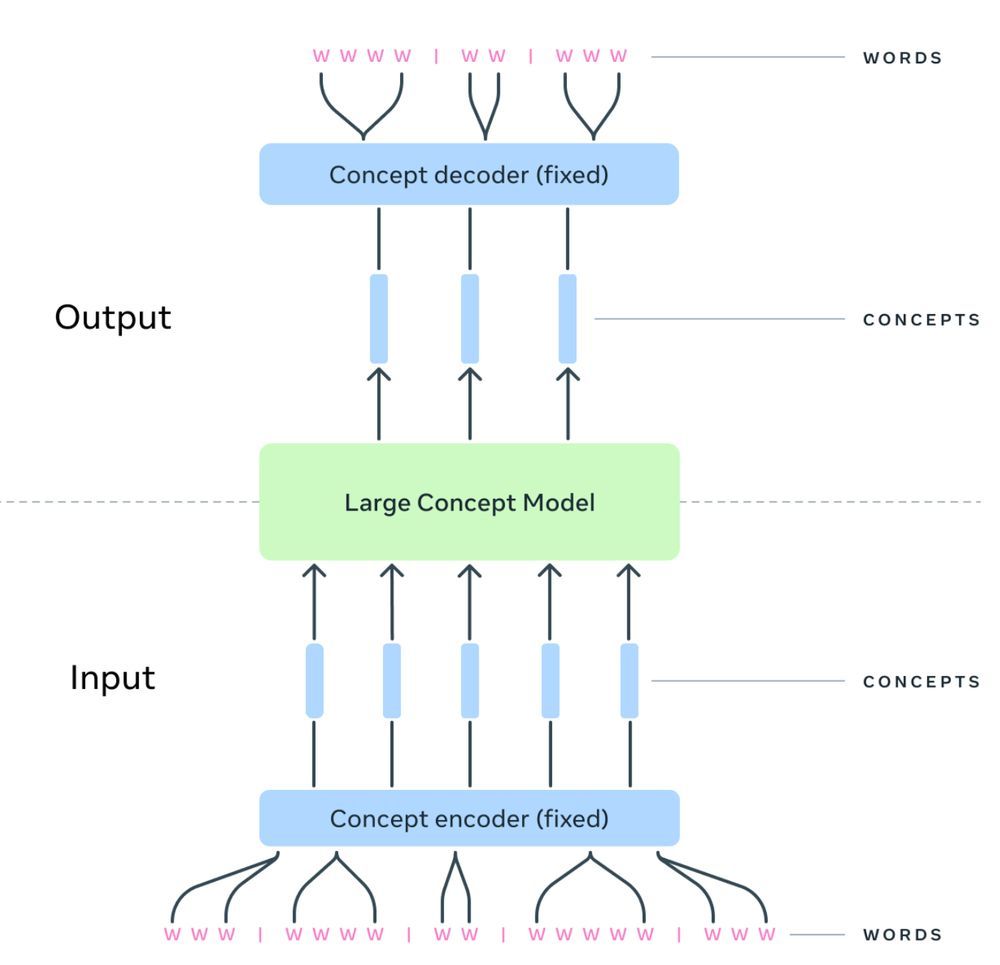
The LCM component here (green) is the only place where we have diffusion, i.e., denoising is only performed at the concept (sentence) level. The concept decoder is a regular subword-level decoder conditioning on a single vector (the sentence vector from the LCM).
December 16, 2024 at 10:05 PM
The LCM component here (green) is the only place where we have diffusion, i.e., denoising is only performed at the concept (sentence) level. The concept decoder is a regular subword-level decoder conditioning on a single vector (the sentence vector from the LCM).
3/3 Figure 13 from the paper shows the flops under different settings of "context size in sentences" & "average length of a sentence". It would definitely be much costlier if we had 1 sentence = 1-5 subwords.

December 16, 2024 at 8:42 PM
3/3 Figure 13 from the paper shows the flops under different settings of "context size in sentences" & "average length of a sentence". It would definitely be much costlier if we had 1 sentence = 1-5 subwords.
2/3 There are no embedding or logits flops in the LCM & the context length is much shorter (a sentence is on average 30 subwords), so a context length of 3000 subwords is only 100 in the LCM. See section 2.5.1 of the paper arxiv.org/abs/2412.08821 for a comparison of inference flops.

Large Concept Models: Language Modeling in a Sentence Representation Space
LLMs have revolutionized the field of artificial intelligence and have emerged as the de-facto tool for many tasks. The current established technology of LLMs is to process input and generate output a...
arxiv.org
December 16, 2024 at 8:42 PM
2/3 There are no embedding or logits flops in the LCM & the context length is much shorter (a sentence is on average 30 subwords), so a context length of 3000 subwords is only 100 in the LCM. See section 2.5.1 of the paper arxiv.org/abs/2412.08821 for a comparison of inference flops.
1/3 Yes. The LCM denoises one concept at a time. A concept once denoised is dispatched to a sentence decoder to generate the corresponding text. No, it does not take 40x the flops of a traditional subword-level decoder.
December 16, 2024 at 8:42 PM
1/3 Yes. The LCM denoises one concept at a time. A concept once denoised is dispatched to a sentence decoder to generate the corresponding text. No, it does not take 40x the flops of a traditional subword-level decoder.
8/ A massive shout-out to the amazing team who made this happen! Loic, Artyom, Paul-Ambroise, David, Tuan and many more awesome collaborators
December 14, 2024 at 6:59 PM
8/ A massive shout-out to the amazing team who made this happen! Loic, Artyom, Paul-Ambroise, David, Tuan and many more awesome collaborators
7/
At FAIR (AI at Meta), we're committed to open research! The training code for our LCMs is freely available. I’m excited about the potential of concept-based language models and what new capabilities they can unlock. github.com/facebookrese...
At FAIR (AI at Meta), we're committed to open research! The training code for our LCMs is freely available. I’m excited about the potential of concept-based language models and what new capabilities they can unlock. github.com/facebookrese...

GitHub - facebookresearch/large_concept_model: Large Concept Models: Language modeling in a sentence representation space
Large Concept Models: Language modeling in a sentence representation space - facebookresearch/large_concept_model
github.com
December 14, 2024 at 6:59 PM
7/
At FAIR (AI at Meta), we're committed to open research! The training code for our LCMs is freely available. I’m excited about the potential of concept-based language models and what new capabilities they can unlock. github.com/facebookrese...
At FAIR (AI at Meta), we're committed to open research! The training code for our LCMs is freely available. I’m excited about the potential of concept-based language models and what new capabilities they can unlock. github.com/facebookrese...
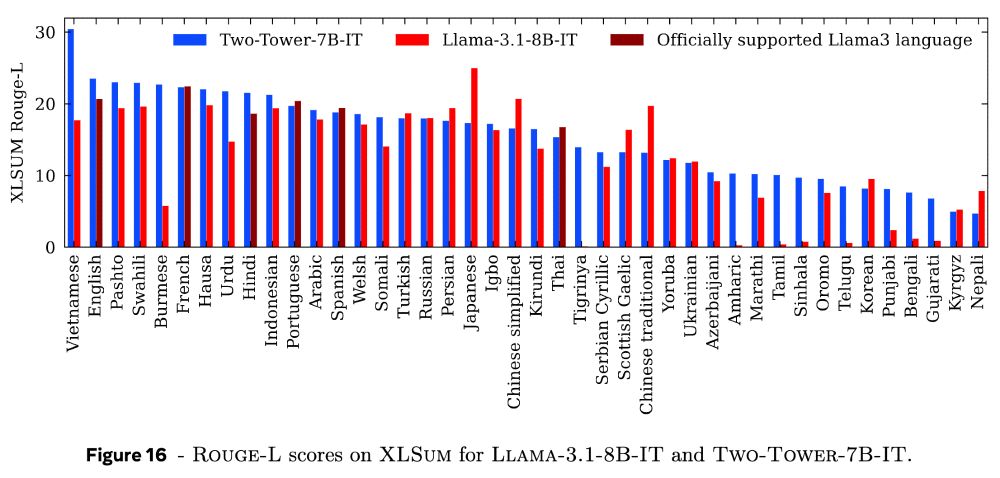
6/ We scale our two-tower diffusion LCM to 7B parameters, achieving competitive summarization performance with similarly sized LLMs. Most importantly, the LCM demonstrates remarkable zero-shot generalization capabilities, effectively handling unseen languages.

December 14, 2024 at 6:59 PM
6/ We scale our two-tower diffusion LCM to 7B parameters, achieving competitive summarization performance with similarly sized LLMs. Most importantly, the LCM demonstrates remarkable zero-shot generalization capabilities, effectively handling unseen languages.
5/ One main challenge of the LCMs was coming up with search algorithms. We use an “end of document” concept and introduce a stopping criterion based on the distance to this special concept. Common inference parameters in diffusion models play a major role too (guidance scale, initial noise, ...)

December 14, 2024 at 6:59 PM
5/ One main challenge of the LCMs was coming up with search algorithms. We use an “end of document” concept and introduce a stopping criterion based on the distance to this special concept. Common inference parameters in diffusion models play a major role too (guidance scale, initial noise, ...)
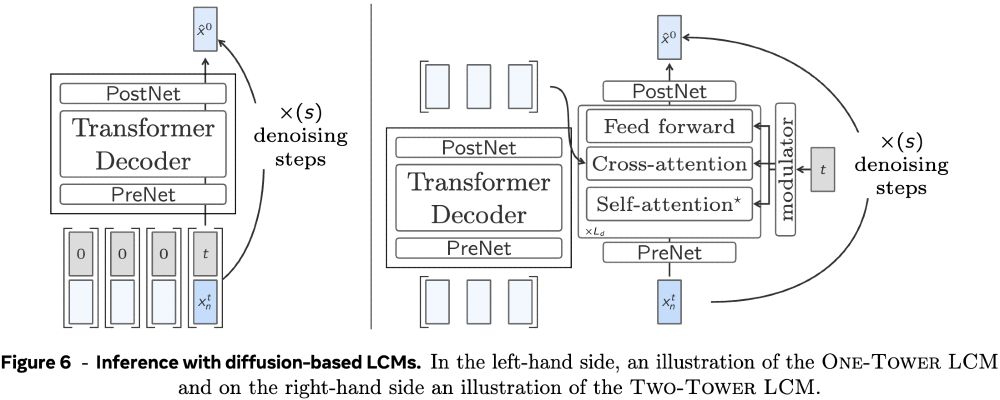
4/ Two diffusion architectures were proposed: “One-Tower” with a single Transformer decoder encoding the context and denoising the next concept at once, and “Two-tower” where we separate context encoding from denoising.
December 14, 2024 at 6:59 PM
4/ Two diffusion architectures were proposed: “One-Tower” with a single Transformer decoder encoding the context and denoising the next concept at once, and “Two-tower” where we separate context encoding from denoising.
3/ We explored different designs for the LCM, a model that can generate the next continuous SONAR embedding conditioned on a sequence of preceding embeddings (MSE regression, diffusion, quantized SONAR). Our study revealed diffusion models to be the most effective approach.
December 14, 2024 at 6:59 PM
3/ We explored different designs for the LCM, a model that can generate the next continuous SONAR embedding conditioned on a sequence of preceding embeddings (MSE regression, diffusion, quantized SONAR). Our study revealed diffusion models to be the most effective approach.
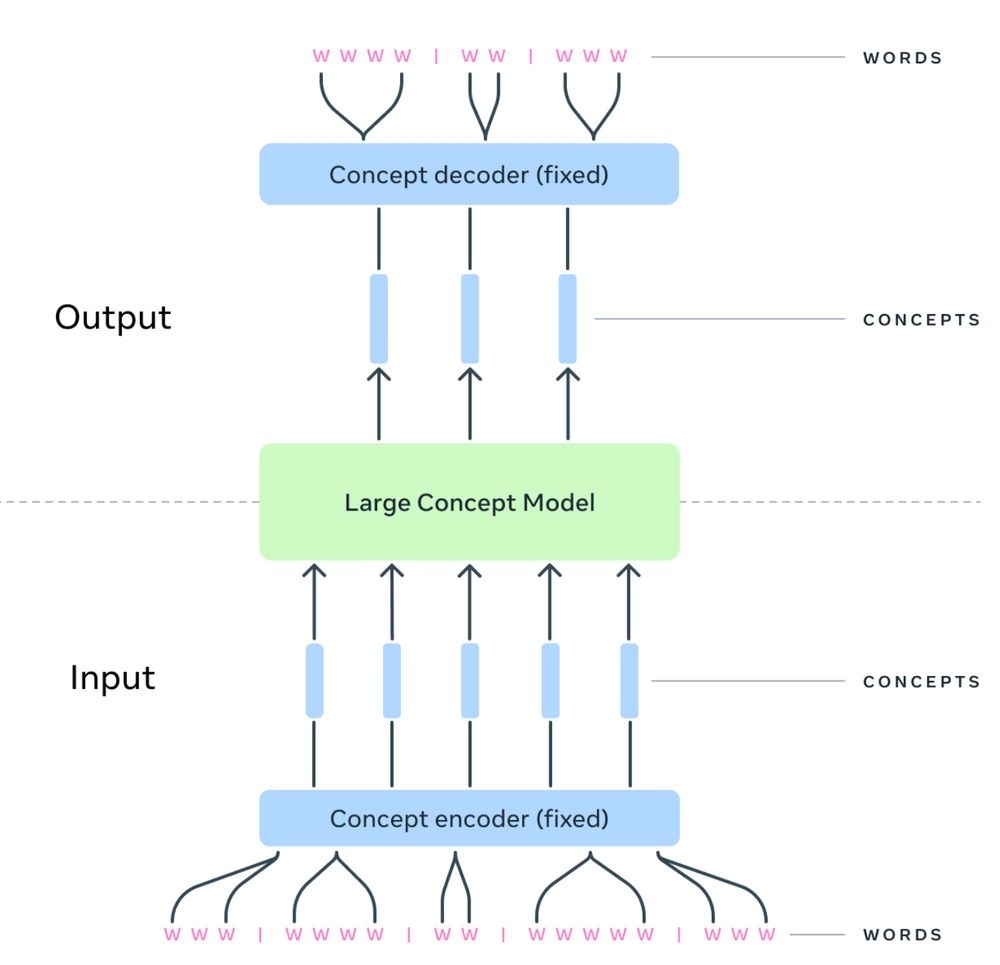
2/ Within the SONAR space, the LCM is trained to predict the next concept in a sequence. The LCM architecture is hierarchical, incorporating SONAR encoders and decoders to seamlessly map into and from the internal space where the LCM performs its computations.
December 14, 2024 at 6:59 PM
2/ Within the SONAR space, the LCM is trained to predict the next concept in a sequence. The LCM architecture is hierarchical, incorporating SONAR encoders and decoders to seamlessly map into and from the internal space where the LCM performs its computations.
1/ LCMs operate at the level of meaning or what we label “concepts”. This corresponds to a sentence in text or an utterance in speech. These units are then embedded into SONAR, a language- and modality-agnostic representation space. github.com/facebookrese...

December 14, 2024 at 6:59 PM
1/ LCMs operate at the level of meaning or what we label “concepts”. This corresponds to a sentence in text or an utterance in speech. These units are then embedded into SONAR, a language- and modality-agnostic representation space. github.com/facebookrese...