




@eify.bsky.social
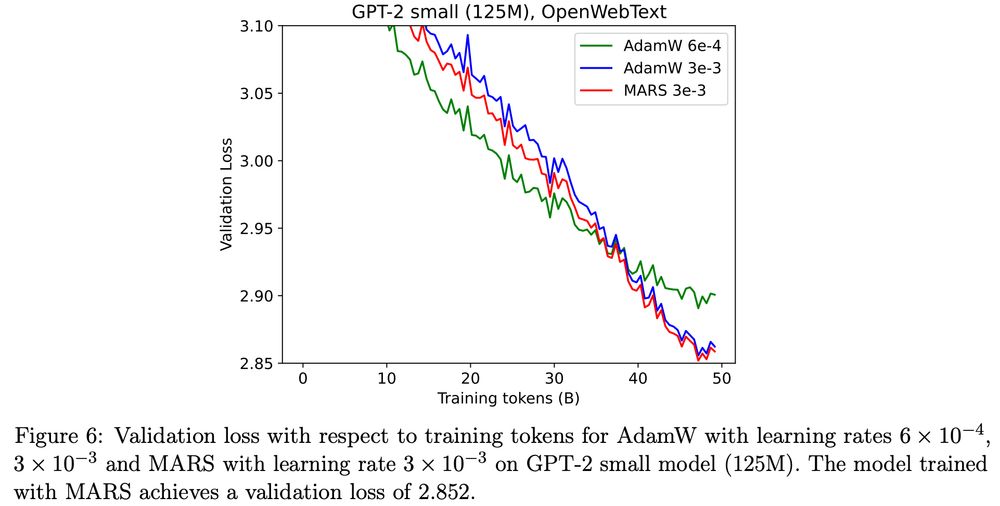
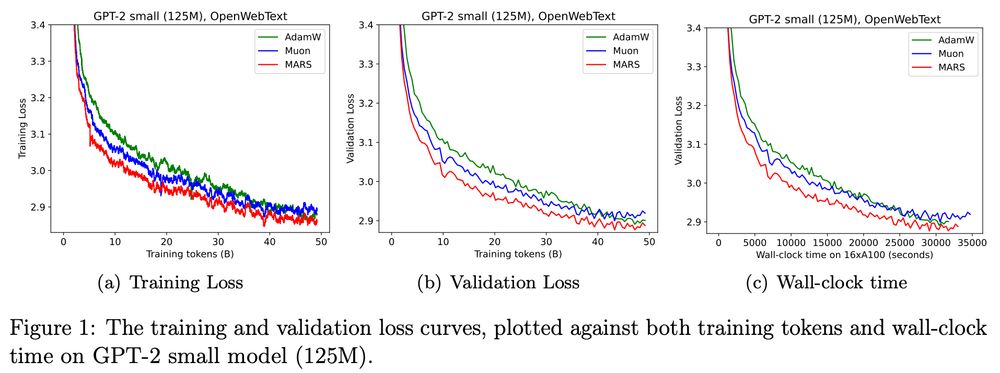
It seems that AdamW & MARS (arxiv.org/abs/2411.10438) effectively reach the same val loss for GPT-2 small with the optimal LR according to Appendix B, in contrast to Figure 1? @quanquangu.bsky.social
If MARS is less sensitive to LR that's also an advantage, but a different kind.
If MARS is less sensitive to LR that's also an advantage, but a different kind.
December 4, 2024 at 9:31 PM
It seems that AdamW & MARS (arxiv.org/abs/2411.10438) effectively reach the same val loss for GPT-2 small with the optimal LR according to Appendix B, in contrast to Figure 1? @quanquangu.bsky.social
If MARS is less sensitive to LR that's also an advantage, but a different kind.
If MARS is less sensitive to LR that's also an advantage, but a different kind.
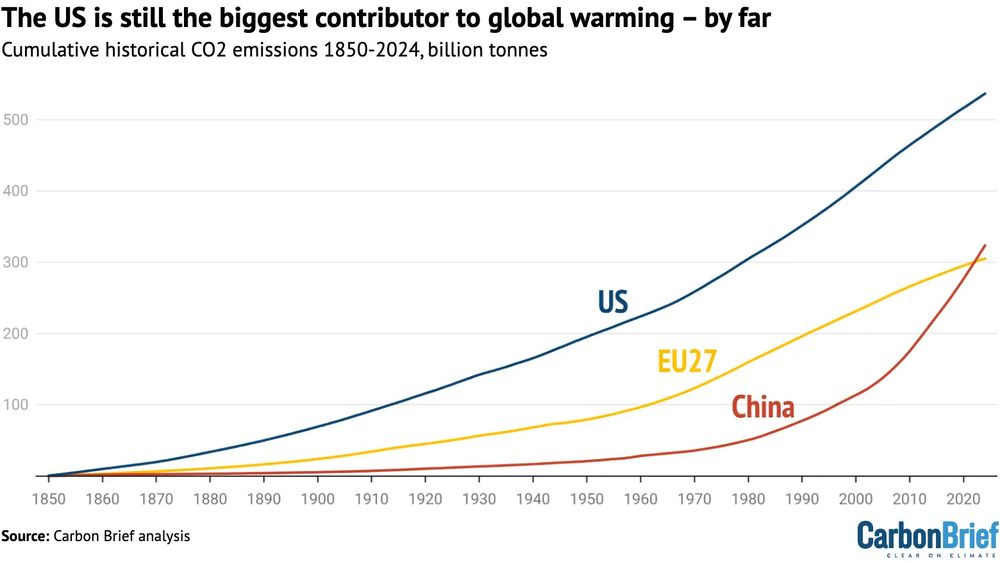
Strange takeaway from that article, I have to say...
All the US have to do to help is to cut Chinese cleantech tariff.
www.theguardian.com/business/art...
All the US have to do to help is to cut Chinese cleantech tariff.
www.theguardian.com/business/art...
November 28, 2024 at 9:42 PM
Strange takeaway from that article, I have to say...
All the US have to do to help is to cut Chinese cleantech tariff.
www.theguardian.com/business/art...
All the US have to do to help is to cut Chinese cleantech tariff.
www.theguardian.com/business/art...