


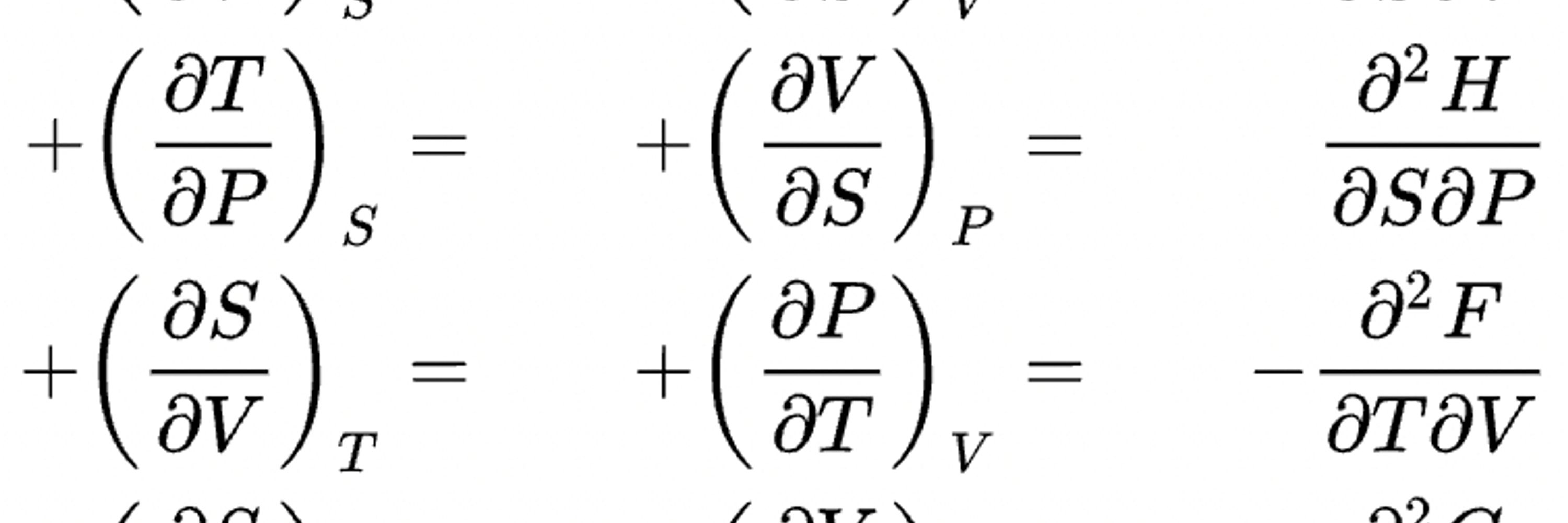

Dr Thomas Moore
@drthomasmoore.bsky.social
Proud Husband. Doting Father.
Modelling & Developing Clean Energy Technologies @ Queensland University of Technology
Modelling & Developing Clean Energy Technologies @ Queensland University of Technology
I continue to vacillate on GenAI in teaching. This is ChatGPT on the isomorphism between the Ising and Gas Lattice models. Its explanation is the worst of both worlds: it sounds authoritative & plausible, yet is nonsensical. (We do have H[n] = H[1-n]). I worry about undergrads relying on this.

November 12, 2025 at 11:52 PM
I continue to vacillate on GenAI in teaching. This is ChatGPT on the isomorphism between the Ising and Gas Lattice models. Its explanation is the worst of both worlds: it sounds authoritative & plausible, yet is nonsensical. (We do have H[n] = H[1-n]). I worry about undergrads relying on this.
Should be a fun weekend.
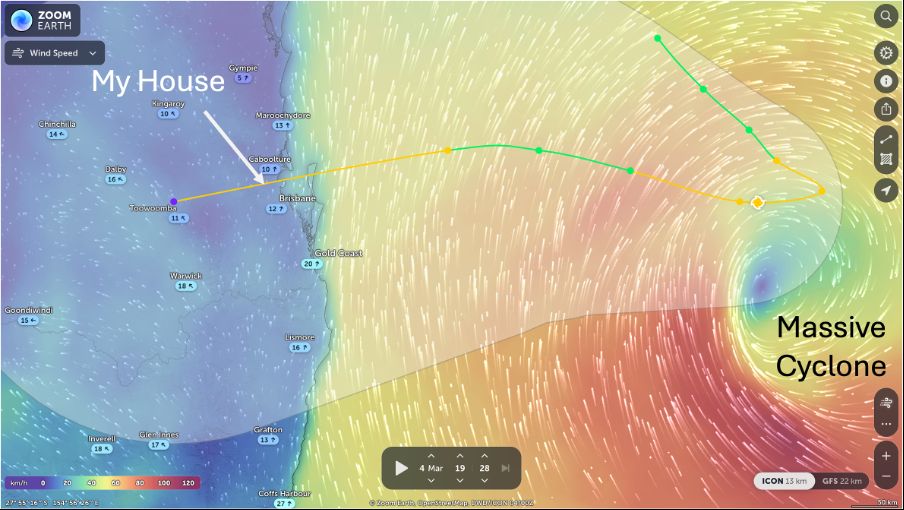
March 4, 2025 at 9:36 AM
Should be a fun weekend.
Update: there's still some strange fragility. If I tweak the problem slightly, the smooth reasoning stalls out, and we get nonsensical answers. I have not idea what o3 is doing here.


February 3, 2025 at 3:37 AM
Update: there's still some strange fragility. If I tweak the problem slightly, the smooth reasoning stalls out, and we get nonsensical answers. I have not idea what o3 is doing here.
Just threw my favourite reactor engineering problem at ChatGPT's new (free) o3-mini model and it nailed it. I came up with this problem years ago. It doesn't feel solvable at first: you need a good instinct for 1st-order reactions, and I haven't seen something similar in any textbooks. Impressive.


February 3, 2025 at 3:26 AM
Just threw my favourite reactor engineering problem at ChatGPT's new (free) o3-mini model and it nailed it. I came up with this problem years ago. It doesn't feel solvable at first: you need a good instinct for 1st-order reactions, and I haven't seen something similar in any textbooks. Impressive.

Kazuo Ishiguro's novels are perfect. 💙📚
Go - go read them all. Whatever you do, don't read a review; they spoil the effect entirely. You can trust me. Start with 'The Remains of the Day'. That is all.
Go - go read them all. Whatever you do, don't read a review; they spoil the effect entirely. You can trust me. Start with 'The Remains of the Day'. That is all.

December 21, 2024 at 10:47 AM
Kazuo Ishiguro's novels are perfect. 💙📚
Go - go read them all. Whatever you do, don't read a review; they spoil the effect entirely. You can trust me. Start with 'The Remains of the Day'. That is all.
Go - go read them all. Whatever you do, don't read a review; they spoil the effect entirely. You can trust me. Start with 'The Remains of the Day'. That is all.
But as you provide more parameters than data points, the interpolation gets once again. Here’s the polynomial case, showing how well the polynomial interpolates between the training data points. Note the initial decrease, the increase, the maxima around n = 14, then the decrease again.

December 20, 2024 at 12:47 AM
But as you provide more parameters than data points, the interpolation gets once again. Here’s the polynomial case, showing how well the polynomial interpolates between the training data points. Note the initial decrease, the increase, the maxima around n = 14, then the decrease again.
But the ML community went ahead and tried anyway. And this is what they found. When you use gradient descent to find parameters that match a 100-degree polynomial to the training data, you *don’t* get crazy polynomials; instead, they tend to interpolate quite well.

December 20, 2024 at 12:46 AM
But the ML community went ahead and tried anyway. And this is what they found. When you use gradient descent to find parameters that match a 100-degree polynomial to the training data, you *don’t* get crazy polynomials; instead, they tend to interpolate quite well.
So far so classical. But the deep learning community turned this idea on its head. They asked the question: what if we fit a 100 degree polynomial to just 14 data points. If you send this request to a classical least squares fitting algorithm, it won’t like you very much:

December 20, 2024 at 12:45 AM
So far so classical. But the deep learning community turned this idea on its head. They asked the question: what if we fit a 100 degree polynomial to just 14 data points. If you send this request to a classical least squares fitting algorithm, it won’t like you very much:
The bias-variance trade-off captures these two extremes: make your model too simple, it can’t capture the signal. Make your model too expressive, it captures the noise. Bias and variance. In this case, a degree 4 polynomial is a good compromise:

December 20, 2024 at 12:44 AM
The bias-variance trade-off captures these two extremes: make your model too simple, it can’t capture the signal. Make your model too expressive, it captures the noise. Bias and variance. In this case, a degree 4 polynomial is a good compromise:
Variance occurs when our model is too expressive: it picks up both the underlying phenomenon and the random variation in the data. We call this overfitting. Fitting a degree 13 polynomial to 14 data points is a classic example. Notice how the model fits the data perfectly, but cannot interpolate.

December 20, 2024 at 12:44 AM
Variance occurs when our model is too expressive: it picks up both the underlying phenomenon and the random variation in the data. We call this overfitting. Fitting a degree 13 polynomial to 14 data points is a classic example. Notice how the model fits the data perfectly, but cannot interpolate.
In classical statistics, we have something called the bias-variance trade-off. Bias and variance are the two ways a model can fail when we’re trying to fit it to data.
Bias occurs when our model is too simple to capture the patterns present in the system. e.g. fitting a line through wavy data.
Bias occurs when our model is too simple to capture the patterns present in the system. e.g. fitting a line through wavy data.

December 20, 2024 at 12:43 AM
In classical statistics, we have something called the bias-variance trade-off. Bias and variance are the two ways a model can fail when we’re trying to fit it to data.
Bias occurs when our model is too simple to capture the patterns present in the system. e.g. fitting a line through wavy data.
Bias occurs when our model is too simple to capture the patterns present in the system. e.g. fitting a line through wavy data.
I've spent the last little while reading the excellent (satirically titled) textbook 'Understanding Deep Learning' by Simon Prince.
The field is a joy, and full of surprises. Take Double Descent: the unintuitive behaviour which is the mathematical cornerstone allowing massive LLMs to be trained. 🧵
The field is a joy, and full of surprises. Take Double Descent: the unintuitive behaviour which is the mathematical cornerstone allowing massive LLMs to be trained. 🧵

December 20, 2024 at 12:42 AM
I've spent the last little while reading the excellent (satirically titled) textbook 'Understanding Deep Learning' by Simon Prince.
The field is a joy, and full of surprises. Take Double Descent: the unintuitive behaviour which is the mathematical cornerstone allowing massive LLMs to be trained. 🧵
The field is a joy, and full of surprises. Take Double Descent: the unintuitive behaviour which is the mathematical cornerstone allowing massive LLMs to be trained. 🧵
I love this figure from an old Bardow-group paper which (like most of their work) has aged remarkably well. Not all uses of clean electricity have equal impact in terms of reducing lifecycle CO2 emissions!
pubs.rsc.org/en/content/a...
pubs.rsc.org/en/content/a...

December 12, 2024 at 5:52 AM
I love this figure from an old Bardow-group paper which (like most of their work) has aged remarkably well. Not all uses of clean electricity have equal impact in terms of reducing lifecycle CO2 emissions!
pubs.rsc.org/en/content/a...
pubs.rsc.org/en/content/a...
With young kids, I've read The Wind in the Willows many (many) times. It's a perfect book. This scene always brings to mind the academic etiquette which forbids 'any sort of comment on the absence of one's friends from a group meeting at any time, for any reason whatsoever'.
🧪🔌💡💙📚
🧪🔌💡💙📚

December 10, 2024 at 10:42 AM
With young kids, I've read The Wind in the Willows many (many) times. It's a perfect book. This scene always brings to mind the academic etiquette which forbids 'any sort of comment on the absence of one's friends from a group meeting at any time, for any reason whatsoever'.
🧪🔌💡💙📚
🧪🔌💡💙📚
I feel seen...

December 4, 2024 at 6:26 AM
I feel seen...
And realistic costs are likely to be far larger than those used in economic forecasting models (I do think it *may* be possible to get a little lower than $600/t, but I agree with this plot in principle)

November 28, 2024 at 4:15 AM
And realistic costs are likely to be far larger than those used in economic forecasting models (I do think it *may* be possible to get a little lower than $600/t, but I agree with this plot in principle)
On a global scale, the energy requirements are flabbergasting,

November 28, 2024 at 4:15 AM
On a global scale, the energy requirements are flabbergasting,
This paper makes a number of arguments related to energy requirements, water and land use, capital cost, scale, etc., familiar to anyone in the DAC space. For example, the dilution factor is extreme:

November 28, 2024 at 4:14 AM
This paper makes a number of arguments related to energy requirements, water and land use, capital cost, scale, etc., familiar to anyone in the DAC space. For example, the dilution factor is extreme:
I'm a carbon capture guy after all. The word cloud doesn't lie.
Courtesy @scholargoggler.bsky.social via @sylvaingigan.bsky.social
Courtesy @scholargoggler.bsky.social via @sylvaingigan.bsky.social

November 25, 2024 at 6:31 AM
I'm a carbon capture guy after all. The word cloud doesn't lie.
Courtesy @scholargoggler.bsky.social via @sylvaingigan.bsky.social
Courtesy @scholargoggler.bsky.social via @sylvaingigan.bsky.social
Finally, if Delta S is really measuring the irreversible increase in energy dispersion, it had better not decrease in an isolated system. That this is impossible is easy to prove by contradiction: if it were false, we could design a process for turning heat directly into work, as shown in the fig.

November 23, 2024 at 1:45 PM
Finally, if Delta S is really measuring the irreversible increase in energy dispersion, it had better not decrease in an isolated system. That this is impossible is easy to prove by contradiction: if it were false, we could design a process for turning heat directly into work, as shown in the fig.
With our definition, the fact that S is a state function follows immediately from Kelvin’s statement of the second law: if Q could take on different values in different reversible processes, by running one forward and then the other backwards, you could turn work into heat. Here's a visual proof.

November 23, 2024 at 1:40 PM
With our definition, the fact that S is a state function follows immediately from Kelvin’s statement of the second law: if Q could take on different values in different reversible processes, by running one forward and then the other backwards, you could turn work into heat. Here's a visual proof.


Fermi takes ~40 pages, while Denbigh takes ~15, and their texts are full of scary diagrams like this:

November 23, 2024 at 1:38 PM
Fermi takes ~40 pages, while Denbigh takes ~15, and their texts are full of scary diagrams like this: