



David Ritzwoller
@dritzwoller.bsky.social
Ph.D Candidate, Stanford GSB
Econometrics, Causal Inference, Machine Learning
https://davidritzwoller.github.io/
Econometrics, Causal Inference, Machine Learning
https://davidritzwoller.github.io/
The paper provides detailed guidance on selecting suitable collections of auxiliary outcomes and combining TMO with existing spatial standard errors. STATA code for implementing TMO is available here:
github.com/wjnkim/tmo
arxiv.org/abs/2504.13295
github.com/wjnkim/tmo
arxiv.org/abs/2504.13295

GitHub - wjnkim/tmo: Thresholding Multiple Outcomes (TMO) estimator for standard errors
Thresholding Multiple Outcomes (TMO) estimator for standard errors - wjnkim/tmo
github.com
May 4, 2025 at 2:04 AM
The paper provides detailed guidance on selecting suitable collections of auxiliary outcomes and combining TMO with existing spatial standard errors. STATA code for implementing TMO is available here:
github.com/wjnkim/tmo
arxiv.org/abs/2504.13295
github.com/wjnkim/tmo
arxiv.org/abs/2504.13295
Applying TMO to nine recent papers, we find significant impacts on estimated standard errors, with a median increase of 37% compared to the published estimates.
May 4, 2025 at 2:04 AM
Applying TMO to nine recent papers, we find significant impacts on estimated standard errors, with a median increase of 37% compared to the published estimates.
(2) Determine a correlation threshold from these estimates; pairs exceeding this threshold are modeled as correlated.
(3) Compute standard errors by accounting only for correlations above the threshold.
(3) Compute standard errors by accounting only for correlations above the threshold.
May 4, 2025 at 2:04 AM
(2) Determine a correlation threshold from these estimates; pairs exceeding this threshold are modeled as correlated.
(3) Compute standard errors by accounting only for correlations above the threshold.
(3) Compute standard errors by accounting only for correlations above the threshold.
Our proposed method, Thresholding Multiple Outcomes (TMO), has three steps:
(1) Estimate pairwise correlations across locations using multiple outcomes.
(1) Estimate pairwise correlations across locations using multiple outcomes.
May 4, 2025 at 2:04 AM
Our proposed method, Thresholding Multiple Outcomes (TMO), has three steps:
(1) Estimate pairwise correlations across locations using multiple outcomes.
(1) Estimate pairwise correlations across locations using multiple outcomes.
The main idea of this paper is to use collections of outcomes, of this form, to identify which location pairs should be allowed to correlate when constructing standard errors in regression problems.
May 4, 2025 at 2:04 AM
The main idea of this paper is to use collections of outcomes, of this form, to identify which location pairs should be allowed to correlate when constructing standard errors in regression problems.
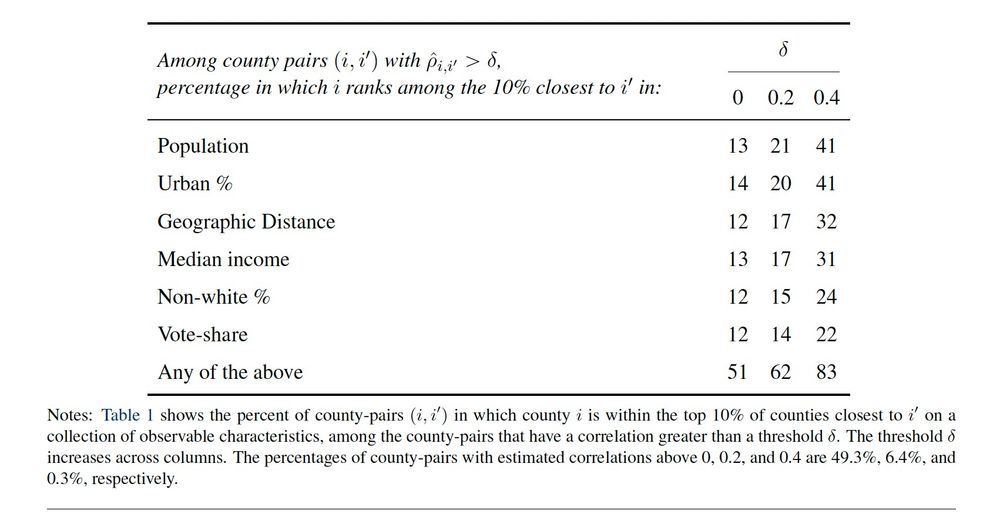
This suggests geographic proximity alone inadequately captures spatial dependence. Even adding population as a covariate doesn’t fully resolve the issue. While several covariates predict high correlations, no single factor completely captures the dependence structure.
May 4, 2025 at 2:04 AM
This suggests geographic proximity alone inadequately captures spatial dependence. Even adding population as a covariate doesn’t fully resolve the issue. While several covariates predict high correlations, no single factor completely captures the dependence structure.
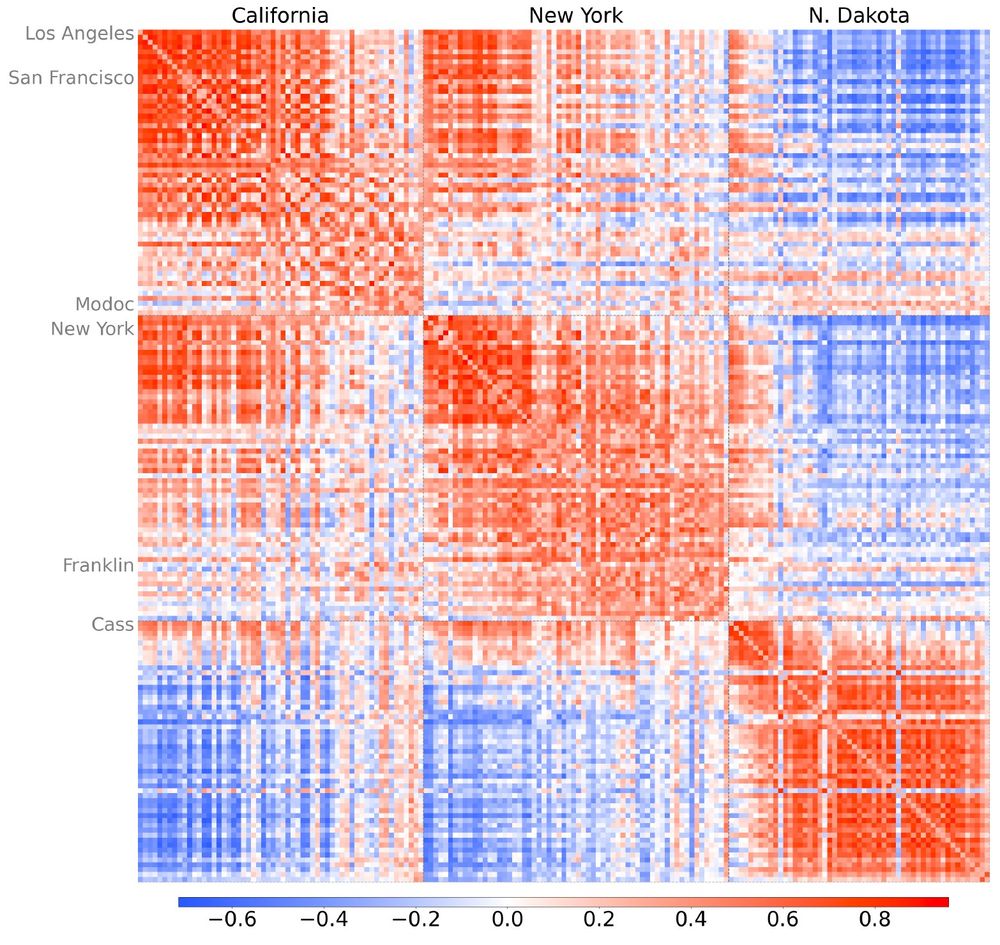
Here's a correlogram for counties in CA, NY, and ND, sorted by state and population. Urban counties in CA correlate more strongly with urban counties in NY than with rural counties in CA. Rural CA counties correlate more closely with ND counties than with urban areas within CA.
May 4, 2025 at 2:04 AM
Here's a correlogram for counties in CA, NY, and ND, sorted by state and population. Urban counties in CA correlate more strongly with urban counties in NY than with rural counties in CA. Rural CA counties correlate more closely with ND counties than with urban areas within CA.
Are these methods appropriate for the types of dependence that we might expect for economic data? We assess this by collecting 91 U.S. county-level outcomes (unemployment, income, etc) and computing the correlation, across outcomes, between each pair of counties
May 4, 2025 at 2:04 AM
Are these methods appropriate for the types of dependence that we might expect for economic data? We assess this by collecting 91 U.S. county-level outcomes (unemployment, income, etc) and computing the correlation, across outcomes, between each pair of counties
About half of the papers in top-5 economics journals in 2023 analyze data indexed by geographic locations. Typically, these papers handle spatial dependence by clustering SEs at a higher aggregation level or by modeling dependence based on geographic distance (e.g., Conley SEs).
May 4, 2025 at 2:04 AM
About half of the papers in top-5 economics journals in 2023 analyze data indexed by geographic locations. Typically, these papers handle spatial dependence by clustering SEs at a higher aggregation level or by modeling dependence based on geographic distance (e.g., Conley SEs).
Thanks Cameron!
December 31, 2024 at 8:10 PM
Thanks Cameron!