



Jered McInerney
@dmcinerney.bsky.social
PhD Candidate in ML/NLP at Northeastern University, currently working on interpretability in healthcare, broadly interested in distant supervision and bridging the gap between pretraining and applications
To train our model, we extract future targets using the LLM and validate that these are reliable, signaling that future work on creating labels with LLM-enabled data augmentation is warranted. (6/6)

February 28, 2024 at 6:56 PM
To train our model, we extract future targets using the LLM and validate that these are reliable, signaling that future work on creating labels with LLM-enabled data augmentation is warranted. (6/6)
…and achieve reasonable accuracy. In fact, we find that our use of the interpretable Neural Additive Model, which allows us to get individual evidence scores, does not decrease performance at all compared to a blackbox approach. (5/6)
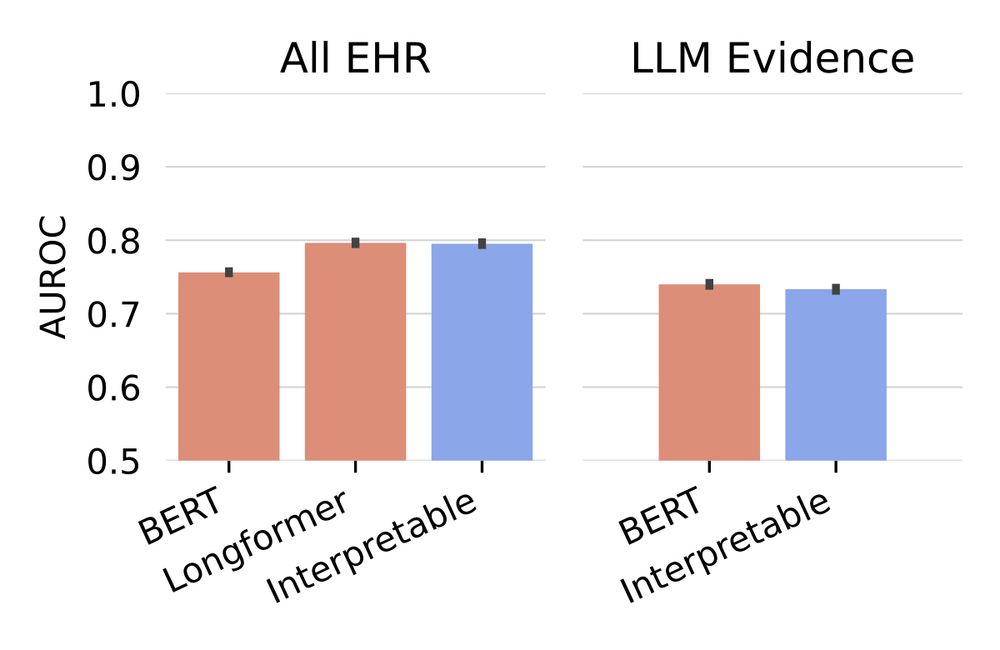
February 28, 2024 at 6:55 PM
…and achieve reasonable accuracy. In fact, we find that our use of the interpretable Neural Additive Model, which allows us to get individual evidence scores, does not decrease performance at all compared to a blackbox approach. (5/6)
We also find that the predictions (both per-evidence and aggregated) are intuitive to the clinicians… (4/6)

February 28, 2024 at 6:55 PM
We also find that the predictions (both per-evidence and aggregated) are intuitive to the clinicians… (4/6)
Our approach does retrieve useful evidence, and both extracting evidence with an LLM and sorting it via our ranking function are crucial to the model’s success. (3/6)

February 28, 2024 at 6:54 PM
Our approach does retrieve useful evidence, and both extracting evidence with an LLM and sorting it via our ranking function are crucial to the model’s success. (3/6)
Our interface allows a clinician to supplement their review of a patient’s record with our model’s risk predictions and surfaced evidence and then annotate the usefulness of that evidence for actually understanding the patient. (2/6)

February 28, 2024 at 6:53 PM
Our interface allows a clinician to supplement their review of a patient’s record with our model’s risk predictions and surfaced evidence and then annotate the usefulness of that evidence for actually understanding the patient. (2/6)
Our work on reducing diagnostic errors with interpretable risk prediction is now on arXiv!
We retrieve evidence from a patient’s record, visualize how it informs a prediction, and test it in a realistic setting. 👇 (1/6)
arxiv.org/abs/2402.10109
w/ @byron.bsky.social and @jwvdm.bsky.social
We retrieve evidence from a patient’s record, visualize how it informs a prediction, and test it in a realistic setting. 👇 (1/6)
arxiv.org/abs/2402.10109
w/ @byron.bsky.social and @jwvdm.bsky.social

February 28, 2024 at 6:52 PM
Our work on reducing diagnostic errors with interpretable risk prediction is now on arXiv!
We retrieve evidence from a patient’s record, visualize how it informs a prediction, and test it in a realistic setting. 👇 (1/6)
arxiv.org/abs/2402.10109
w/ @byron.bsky.social and @jwvdm.bsky.social
We retrieve evidence from a patient’s record, visualize how it informs a prediction, and test it in a realistic setting. 👇 (1/6)
arxiv.org/abs/2402.10109
w/ @byron.bsky.social and @jwvdm.bsky.social
we find it makes efficient use of features. (6/6)

October 25, 2023 at 2:21 PM
we find it makes efficient use of features. (6/6)
This method also shows promise in being data-efficient, and... (5/6)

October 25, 2023 at 2:21 PM
This method also shows promise in being data-efficient, and... (5/6)
Inspection of individual instances with this approach yields insights as to what went right and what went wrong. (4/6)

October 25, 2023 at 2:20 PM
Inspection of individual instances with this approach yields insights as to what went right and what went wrong. (4/6)
We find that most of the coefficients of the linear model align with clinical expectations for the corresponding feature! (3/6)

October 25, 2023 at 2:19 PM
We find that most of the coefficients of the linear model align with clinical expectations for the corresponding feature! (3/6)
Not only do we see decent accuracy at feature extraction itself, but we also see reasonable performance on the downstream tasks in comparison with using ground truth features. (2/6)

October 25, 2023 at 2:18 PM
Not only do we see decent accuracy at feature extraction itself, but we also see reasonable performance on the downstream tasks in comparison with using ground truth features. (2/6)
Very excited our “CHiLL” paper was accepted to #EMNLP2023 Findings!
Can we craft arbitrary high-level features without training?👇(1/6)
We ask a doctor to ask questions to an LLM and train an interpretable model on the answers.
arxiv.org/abs/2302.12343
w/ @jwvdm.bsky.social and @byron.bsky.social
Can we craft arbitrary high-level features without training?👇(1/6)
We ask a doctor to ask questions to an LLM and train an interpretable model on the answers.
arxiv.org/abs/2302.12343
w/ @jwvdm.bsky.social and @byron.bsky.social

October 25, 2023 at 2:18 PM
Very excited our “CHiLL” paper was accepted to #EMNLP2023 Findings!
Can we craft arbitrary high-level features without training?👇(1/6)
We ask a doctor to ask questions to an LLM and train an interpretable model on the answers.
arxiv.org/abs/2302.12343
w/ @jwvdm.bsky.social and @byron.bsky.social
Can we craft arbitrary high-level features without training?👇(1/6)
We ask a doctor to ask questions to an LLM and train an interpretable model on the answers.
arxiv.org/abs/2302.12343
w/ @jwvdm.bsky.social and @byron.bsky.social