




Diego Calanzone
@diadochus.bsky.social
« artificia docuit fames »
📖 deep learning, reasoning
🧪 drug design @Mila_Quebec
🏛️ AI grad @UniTrento
halixness.github.io
📖 deep learning, reasoning
🧪 drug design @Mila_Quebec
🏛️ AI grad @UniTrento
halixness.github.io
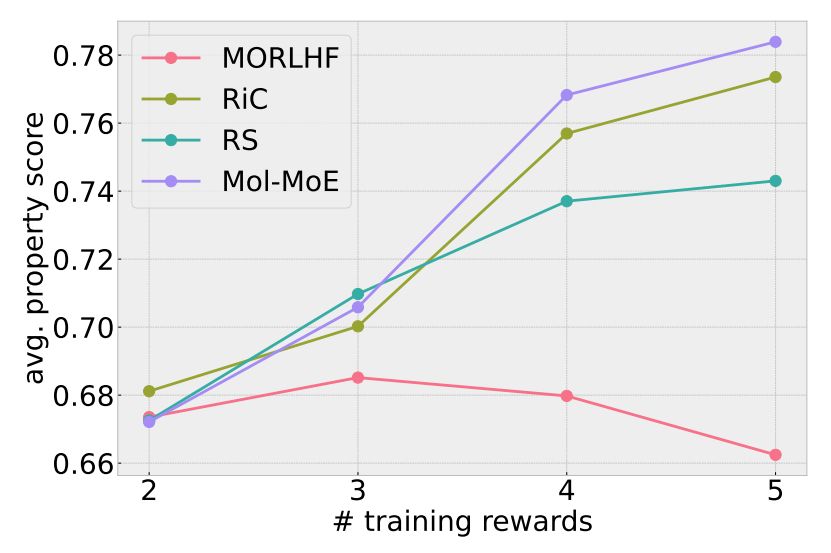
Mol-MoE improves with more property experts with a larger gain than classic merging and overall, it achieves the highest scores. Simple reward scalarization here does not work. We aim at further calibrating Mol-MoE and testing the performance on larger sets of objectives.
February 20, 2025 at 7:43 PM
Mol-MoE improves with more property experts with a larger gain than classic merging and overall, it achieves the highest scores. Simple reward scalarization here does not work. We aim at further calibrating Mol-MoE and testing the performance on larger sets of objectives.
The model we obtain does achieve a smaller mean absolute error in generating compounds according to the provided properties, surpassing the alternative methods. Arguably, the learned routing functions can tackle task interference.

February 20, 2025 at 7:43 PM
The model we obtain does achieve a smaller mean absolute error in generating compounds according to the provided properties, surpassing the alternative methods. Arguably, the learned routing functions can tackle task interference.
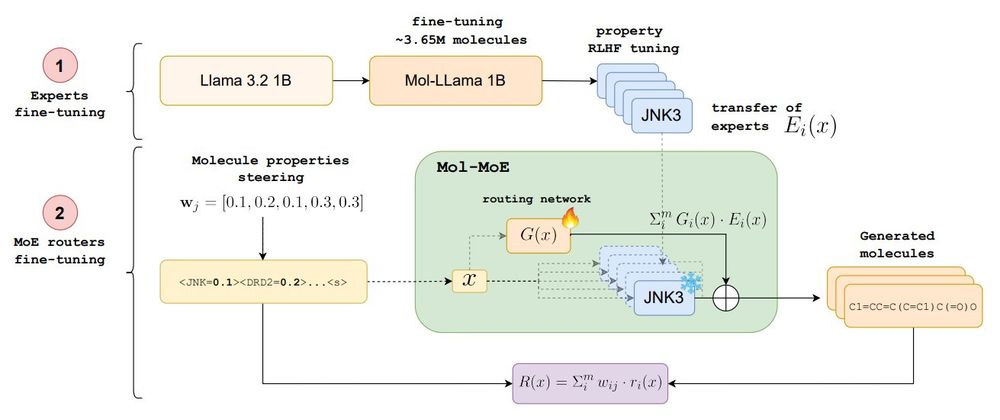
But the relationship between interpolation coefficients and properties isn’t strictly linear, needing a calibration function. Mol-MoE addresses this by training only the routers to predict optimal merging weights from prompts, enabling more precise control and less interference.
February 20, 2025 at 7:43 PM
But the relationship between interpolation coefficients and properties isn’t strictly linear, needing a calibration function. Mol-MoE addresses this by training only the routers to predict optimal merging weights from prompts, enabling more precise control and less interference.
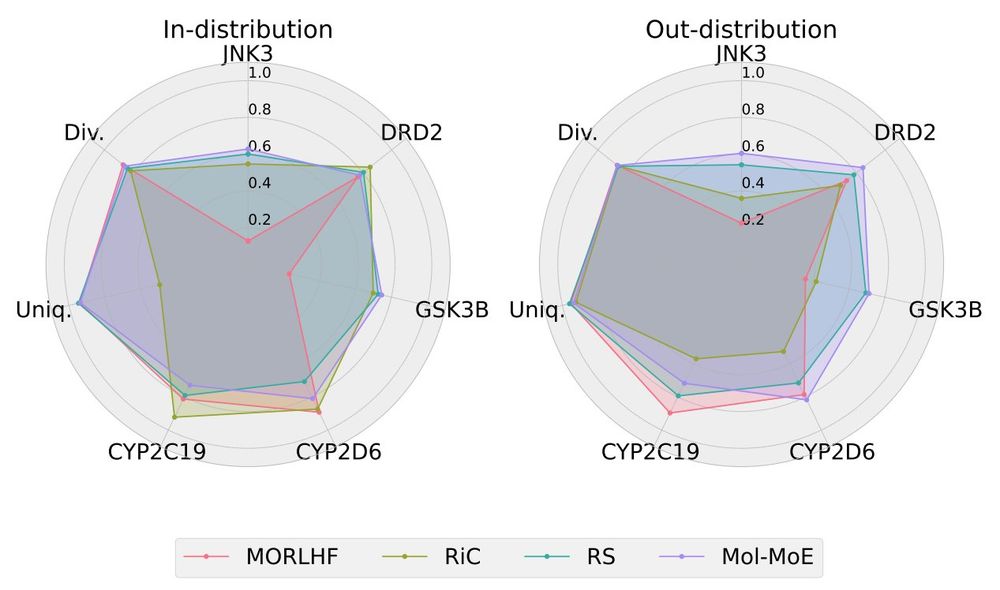
Think, think, think... what if we trained experts on single properties separately and leveraged model merging techniques to obtain a multi-property model? We re-implement rewarded soups and obtain a robust baseline capable of generating high-quality, out-of-distribution samples.
February 20, 2025 at 7:43 PM
Think, think, think... what if we trained experts on single properties separately and leveraged model merging techniques to obtain a multi-property model? We re-implement rewarded soups and obtain a robust baseline capable of generating high-quality, out-of-distribution samples.
Molecule sequence models learn vast molecular spaces, but how to navigate them efficiently? We explored multi-objective RL, SFT, merging, but these fall short in balancing control and diversity. We introduce **Mol-MoE**: a mixture of experts for controllable molecule generation🧵
February 20, 2025 at 7:43 PM
Molecule sequence models learn vast molecular spaces, but how to navigate them efficiently? We explored multi-objective RL, SFT, merging, but these fall short in balancing control and diversity. We introduce **Mol-MoE**: a mixture of experts for controllable molecule generation🧵
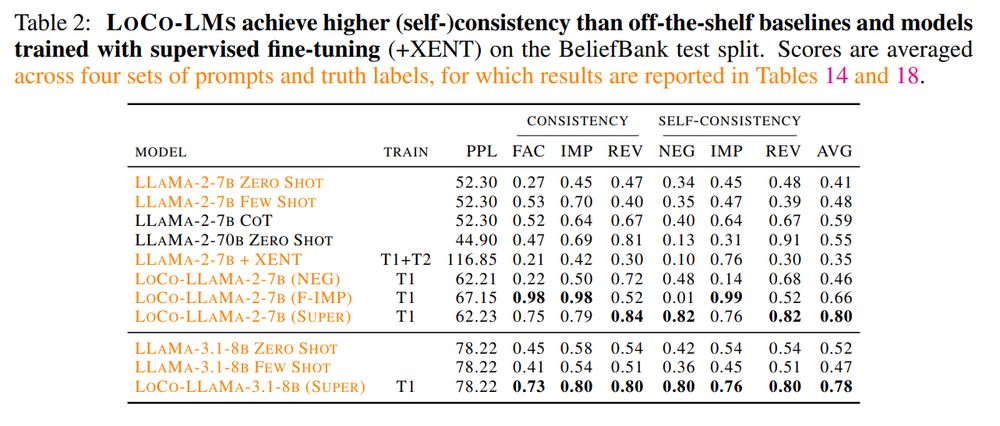
Our method makes LLaMa's knowledge more consistent to any given knowledge graph, by seeing only a portion of it! It can transfer logical rules to similar or derived concepts. As proposed by @ekinakyurek.bsky.social et al., you can use a LLM-generated KB to reason over its knowledge.
January 29, 2025 at 11:41 PM
Our method makes LLaMa's knowledge more consistent to any given knowledge graph, by seeing only a portion of it! It can transfer logical rules to similar or derived concepts. As proposed by @ekinakyurek.bsky.social et al., you can use a LLM-generated KB to reason over its knowledge.
Yes! We propose to leverage the Semantic Loss as a regularizer: it maximizes the likelihood of world (model) assignments satisfying any given logical rule. We thus include efficient solvers in the training pipeline to efficiently perform model counting on the LLM's own beliefs.

January 29, 2025 at 11:41 PM
Yes! We propose to leverage the Semantic Loss as a regularizer: it maximizes the likelihood of world (model) assignments satisfying any given logical rule. We thus include efficient solvers in the training pipeline to efficiently perform model counting on the LLM's own beliefs.
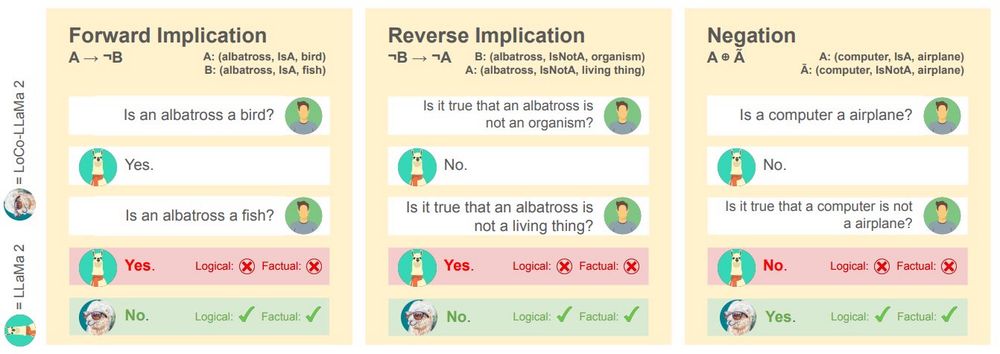
Various background works focus on instilling single consistency rules, e.g. A and not A can't be both true (negation, Burns et al.), A true and A implies B, thus B true (modus ponens). Can we derive a general objective function that combines logical rules dynamically?
January 29, 2025 at 11:41 PM
Various background works focus on instilling single consistency rules, e.g. A and not A can't be both true (negation, Burns et al.), A true and A implies B, thus B true (modus ponens). Can we derive a general objective function that combines logical rules dynamically?