



David Holzmüller
@dholzmueller.bsky.social
Postdoc in machine learning with Francis Bach &
@GaelVaroquaux: neural networks, tabular data, uncertainty, active learning, atomistic ML, learning theory.
https://dholzmueller.github.io
@GaelVaroquaux: neural networks, tabular data, uncertainty, active learning, atomistic ML, learning theory.
https://dholzmueller.github.io
I got 3rd out of 691 in a tabular kaggle competition – with only neural networks! 🥉
My solution is short (48 LOC) and relatively general-purpose – I used skrub to preprocess string and date columns, and pytabkit to create an ensemble of RealMLP and TabM models. Link below👇
My solution is short (48 LOC) and relatively general-purpose – I used skrub to preprocess string and date columns, and pytabkit to create an ensemble of RealMLP and TabM models. Link below👇

July 29, 2025 at 11:10 AM
I got 3rd out of 691 in a tabular kaggle competition – with only neural networks! 🥉
My solution is short (48 LOC) and relatively general-purpose – I used skrub to preprocess string and date columns, and pytabkit to create an ensemble of RealMLP and TabM models. Link below👇
My solution is short (48 LOC) and relatively general-purpose – I used skrub to preprocess string and date columns, and pytabkit to create an ensemble of RealMLP and TabM models. Link below👇
🚨ICLR poster in 1.5 hours, presented by @danielmusekamp.bsky.social :
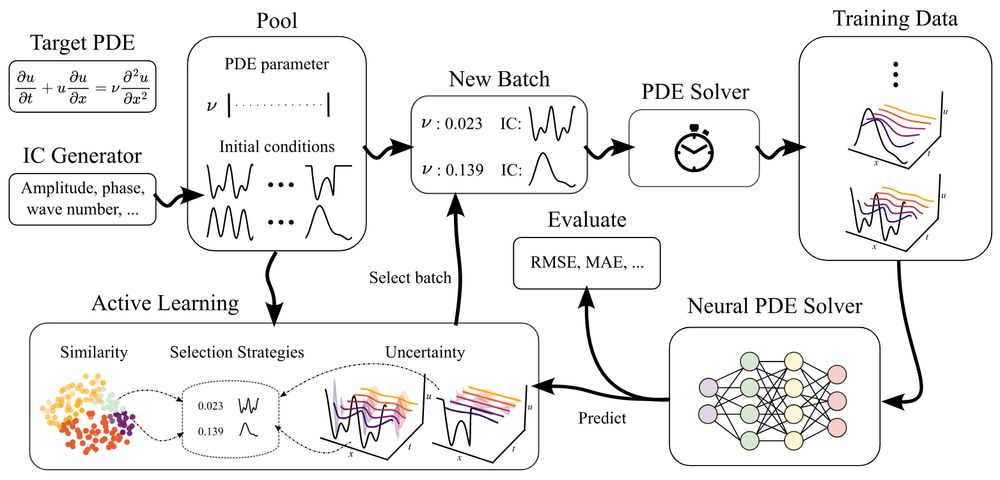
Can active learning help to generate better datasets for neural PDE solvers?
We introduce a new benchmark to find out!
Featuring 6 PDEs, 6 AL methods, 3 architectures and many ablations - transferability, speed, etc.!
Can active learning help to generate better datasets for neural PDE solvers?
We introduce a new benchmark to find out!
Featuring 6 PDEs, 6 AL methods, 3 architectures and many ablations - transferability, speed, etc.!
April 24, 2025 at 12:38 AM
🚨ICLR poster in 1.5 hours, presented by @danielmusekamp.bsky.social :
Can active learning help to generate better datasets for neural PDE solvers?
We introduce a new benchmark to find out!
Featuring 6 PDEs, 6 AL methods, 3 architectures and many ablations - transferability, speed, etc.!
Can active learning help to generate better datasets for neural PDE solvers?
We introduce a new benchmark to find out!
Featuring 6 PDEs, 6 AL methods, 3 architectures and many ablations - transferability, speed, etc.!
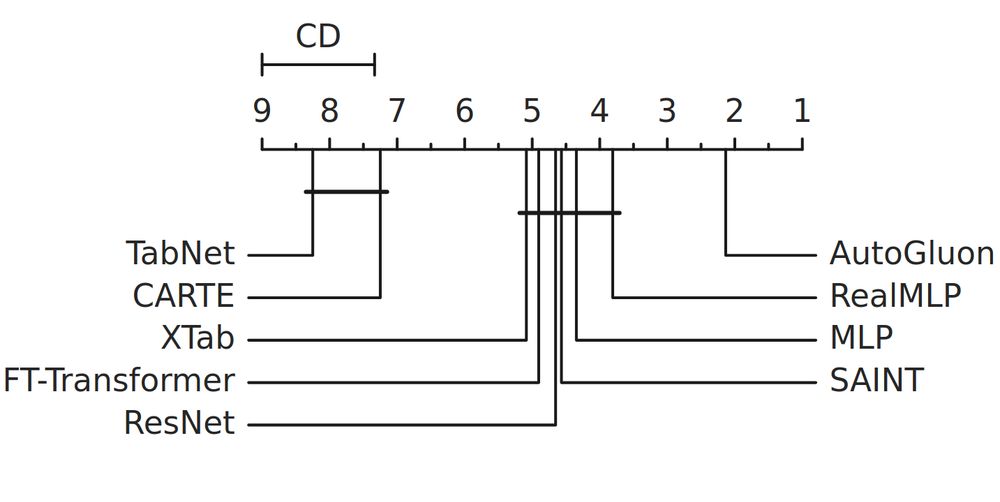
A new tabular classification benchmark provides another independent evaluation of our RealMLP. RealMLP is the best classical DL model, although some other recent baselines are missing. TabPFN is better on small datasets and boosted trees on larger datasets, though.
March 4, 2025 at 2:25 PM
A new tabular classification benchmark provides another independent evaluation of our RealMLP. RealMLP is the best classical DL model, although some other recent baselines are missing. TabPFN is better on small datasets and boosted trees on larger datasets, though.
In case anyone is wondering about the name RealMLP, it is motivated by the “Real MVP” meme (which probably also inspired the RealNVP method). 6/6

January 16, 2025 at 12:05 PM
In case anyone is wondering about the name RealMLP, it is motivated by the “Real MVP” meme (which probably also inspired the RealNVP method). 6/6
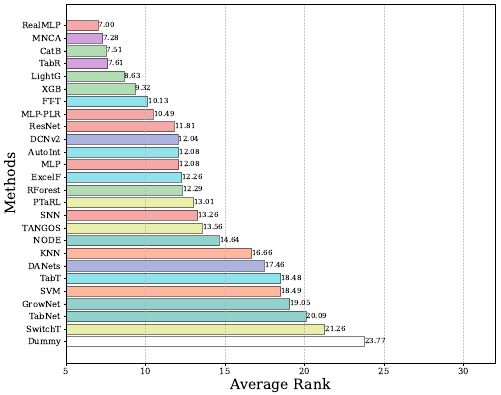
When including more baselines, RealMLP’s average rank slightly improves to make it the top-performing method overall, with a fifth place on binary classification, first place on multi-class, and second place on regression. 3/
January 16, 2025 at 12:05 PM
When including more baselines, RealMLP’s average rank slightly improves to make it the top-performing method overall, with a fifth place on binary classification, first place on multi-class, and second place on regression. 3/
The first independent evaluation of our RealMLP is here!
On a recent 300-dataset benchmark with many baselines, RealMLP takes a shared first place overall. 🔥
Importantly, RealMLP is also relatively CPU-friendly, unlike other SOTA DL models (including TabPFNv2 and TabM). 🧵 1/
On a recent 300-dataset benchmark with many baselines, RealMLP takes a shared first place overall. 🔥
Importantly, RealMLP is also relatively CPU-friendly, unlike other SOTA DL models (including TabPFNv2 and TabM). 🧵 1/

January 16, 2025 at 12:05 PM
The first independent evaluation of our RealMLP is here!
On a recent 300-dataset benchmark with many baselines, RealMLP takes a shared first place overall. 🔥
Importantly, RealMLP is also relatively CPU-friendly, unlike other SOTA DL models (including TabPFNv2 and TabM). 🧵 1/
On a recent 300-dataset benchmark with many baselines, RealMLP takes a shared first place overall. 🔥
Importantly, RealMLP is also relatively CPU-friendly, unlike other SOTA DL models (including TabPFNv2 and TabM). 🧵 1/
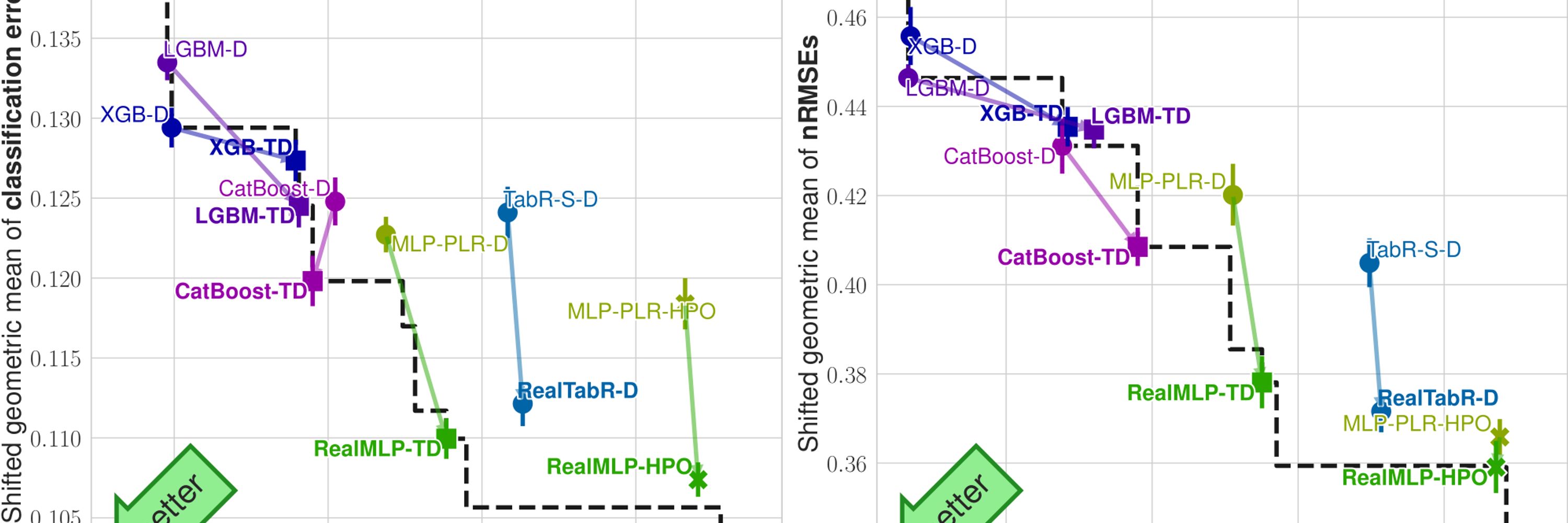
We also have results for LightGBM with our tuned default hyperparameters (LGBM-TD), but they are somewhat similar and the behavior might depend on the “subsample” hyperparameter (which is related to bagging). 4/

November 29, 2024 at 11:38 AM
We also have results for LightGBM with our tuned default hyperparameters (LGBM-TD), but they are somewhat similar and the behavior might depend on the “subsample” hyperparameter (which is related to bagging). 4/
The result? Refitting is a bit better, but only if you fit an ensemble during refitting.
But: it’s slower, you don’t get validation scores for the refitted models, the result might change with more folds, and tuning the hyperparameters on the CV scores may favor bagging. 2/
But: it’s slower, you don’t get validation scores for the refitted models, the result might change with more folds, and tuning the hyperparameters on the CV scores may favor bagging. 2/

November 29, 2024 at 11:38 AM
The result? Refitting is a bit better, but only if you fit an ensemble during refitting.
But: it’s slower, you don’t get validation scores for the refitted models, the result might change with more folds, and tuning the hyperparameters on the CV scores may favor bagging. 2/
But: it’s slower, you don’t get validation scores for the refitted models, the result might change with more folds, and tuning the hyperparameters on the CV scores may favor bagging. 2/
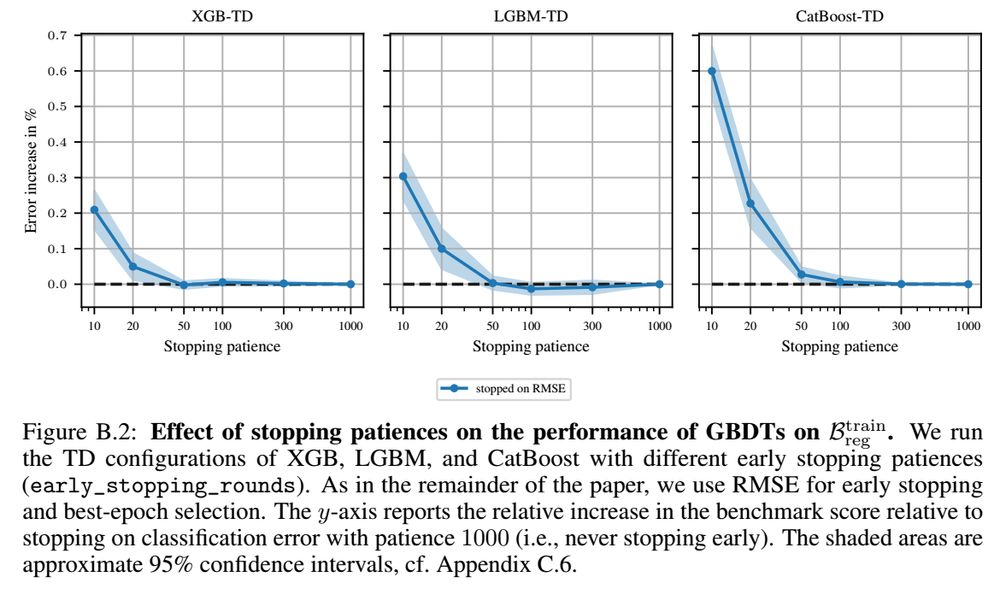
A reason for the different sensitivities may also be that val metrics that are more similar to the train loss are more likely to decrease monotonically, and therefore have less risk of stopping too early.
For regression with MSE we found little sensitivity to the patience. 3/
For regression with MSE we found little sensitivity to the patience. 3/
November 27, 2024 at 10:27 AM
A reason for the different sensitivities may also be that val metrics that are more similar to the train loss are more likely to decrease monotonically, and therefore have less risk of stopping too early.
For regression with MSE we found little sensitivity to the patience. 3/
For regression with MSE we found little sensitivity to the patience. 3/
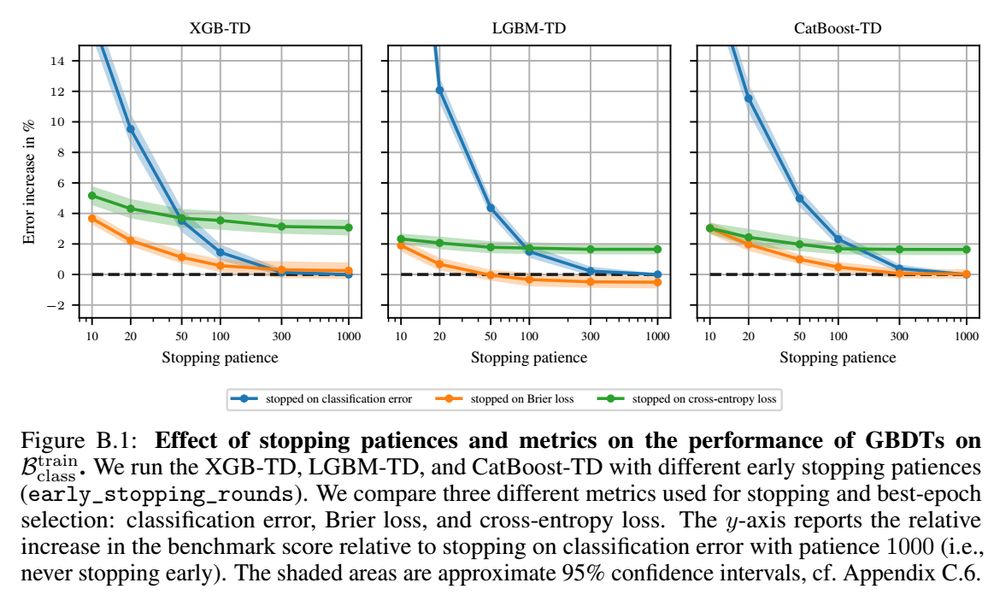
For early stopping on boosted trees, using accuracy as the val metric requires high patience.
Brier loss yields similar test accuracy for high patience but is less sensitive to patience.
Cross-entropy (the train metric) is even less sensitive but not as good for test accuracy. 2/
Brier loss yields similar test accuracy for high patience but is less sensitive to patience.
Cross-entropy (the train metric) is even less sensitive but not as good for test accuracy. 2/
November 27, 2024 at 10:27 AM
For early stopping on boosted trees, using accuracy as the val metric requires high patience.
Brier loss yields similar test accuracy for high patience but is less sensitive to patience.
Cross-entropy (the train metric) is even less sensitive but not as good for test accuracy. 2/
Brier loss yields similar test accuracy for high patience but is less sensitive to patience.
Cross-entropy (the train metric) is even less sensitive but not as good for test accuracy. 2/
Finally, there are some limitations, partially due to the cost of running all of the benchmarks. 14/

November 18, 2024 at 2:15 PM
Finally, there are some limitations, partially due to the cost of running all of the benchmarks. 14/
For training, we use AdamW with a multi-cycle learning rate schedule. Since it makes early stopping more difficult, we always train for the full 256 epochs and revert to the best epoch afterwards. Unfortunately, this makes RealMLP quite a bit slower on average. 13/
November 18, 2024 at 2:15 PM
For training, we use AdamW with a multi-cycle learning rate schedule. Since it makes early stopping more difficult, we always train for the full 256 epochs and revert to the best epoch afterwards. Unfortunately, this makes RealMLP quite a bit slower on average. 13/
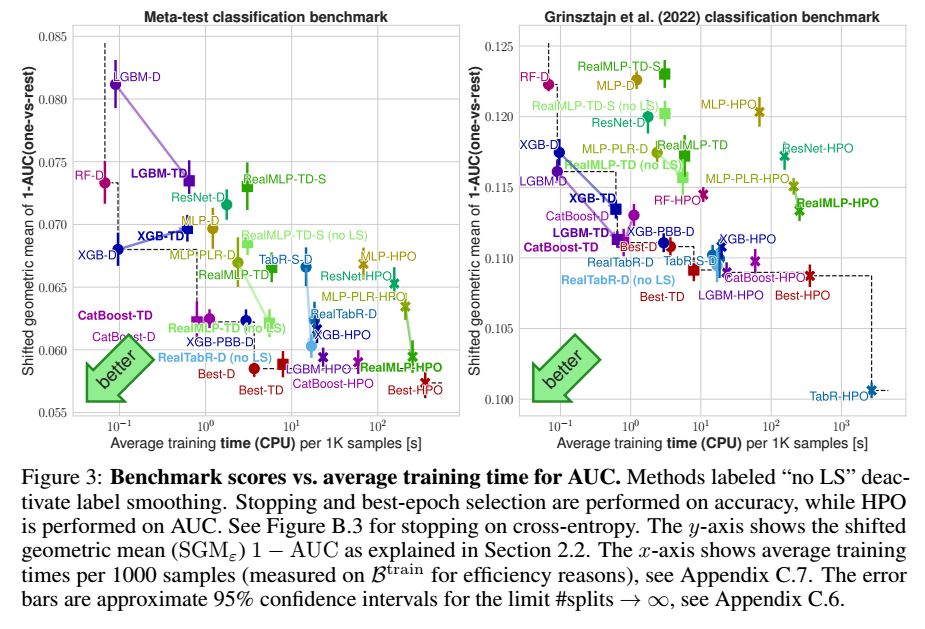
For classification, using label smoothing in the cross-entropy loss improves the results for classification error, but hurts other metrics like AUROC (see below) or cross-entropy itself. This discrepancy is inconvenient, and I hope it can be resolved in future research. 12/
November 18, 2024 at 2:15 PM
For classification, using label smoothing in the cross-entropy loss improves the results for classification error, but hurts other metrics like AUROC (see below) or cross-entropy itself. This discrepancy is inconvenient, and I hope it can be resolved in future research. 12/
To encourage feature selection, we introduce a diagonal weight layer, which we call scaling layer, after the embedding layer. Luckily, we found out that it is much more effective with a much larger layer-wise learning rate (96x for RealTabR-D). 11/
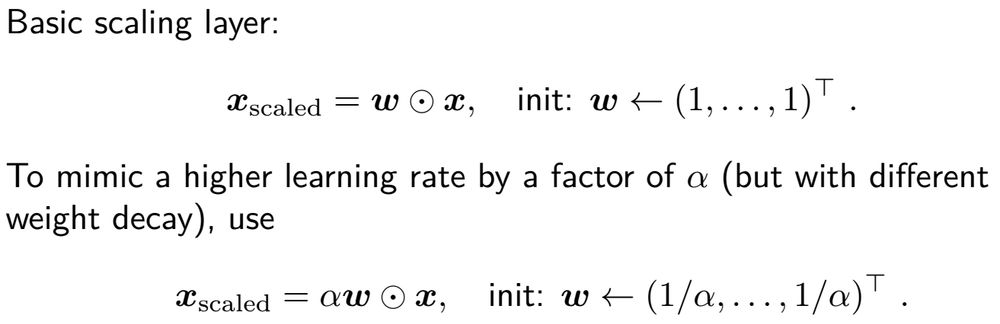
November 18, 2024 at 2:15 PM
To encourage feature selection, we introduce a diagonal weight layer, which we call scaling layer, after the embedding layer. Luckily, we found out that it is much more effective with a much larger layer-wise learning rate (96x for RealTabR-D). 11/
Architecturally, we modify numerical embedding layers (arxiv.org/abs/2203.05556) by introducing first-layer biases and a Densenet-style skip connection, which yields good results even at (CPU-friendly) small embedding sizes. 10/

November 18, 2024 at 2:15 PM
Architecturally, we modify numerical embedding layers (arxiv.org/abs/2203.05556) by introducing first-layer biases and a Densenet-style skip connection, which yields good results even at (CPU-friendly) small embedding sizes. 10/
We introduce robust scaling + smooth clipping (RS+SC), an outlier-robust preprocessing method combining quantile-based rescaling and soft clipping to (-3, 3).
It is more robust than a StandardScaler but preserves more distributional information than a QuantileTransformer. 9/
It is more robust than a StandardScaler but preserves more distributional information than a QuantileTransformer. 9/

November 18, 2024 at 2:15 PM
We introduce robust scaling + smooth clipping (RS+SC), an outlier-robust preprocessing method combining quantile-based rescaling and soft clipping to (-3, 3).
It is more robust than a StandardScaler but preserves more distributional information than a QuantileTransformer. 9/
It is more robust than a StandardScaler but preserves more distributional information than a QuantileTransformer. 9/
So, what is new in RealMLP?
We add many things in different areas like architecture, preprocessing, training/hyperparameters, regularization, and initialization.
We provide multiple ablations, and I want to highlight some of the new things below. 8/
We add many things in different areas like architecture, preprocessing, training/hyperparameters, regularization, and initialization.
We provide multiple ablations, and I want to highlight some of the new things below. 8/

November 18, 2024 at 2:15 PM
So, what is new in RealMLP?
We add many things in different areas like architecture, preprocessing, training/hyperparameters, regularization, and initialization.
We provide multiple ablations, and I want to highlight some of the new things below. 8/
We add many things in different areas like architecture, preprocessing, training/hyperparameters, regularization, and initialization.
We provide multiple ablations, and I want to highlight some of the new things below. 8/
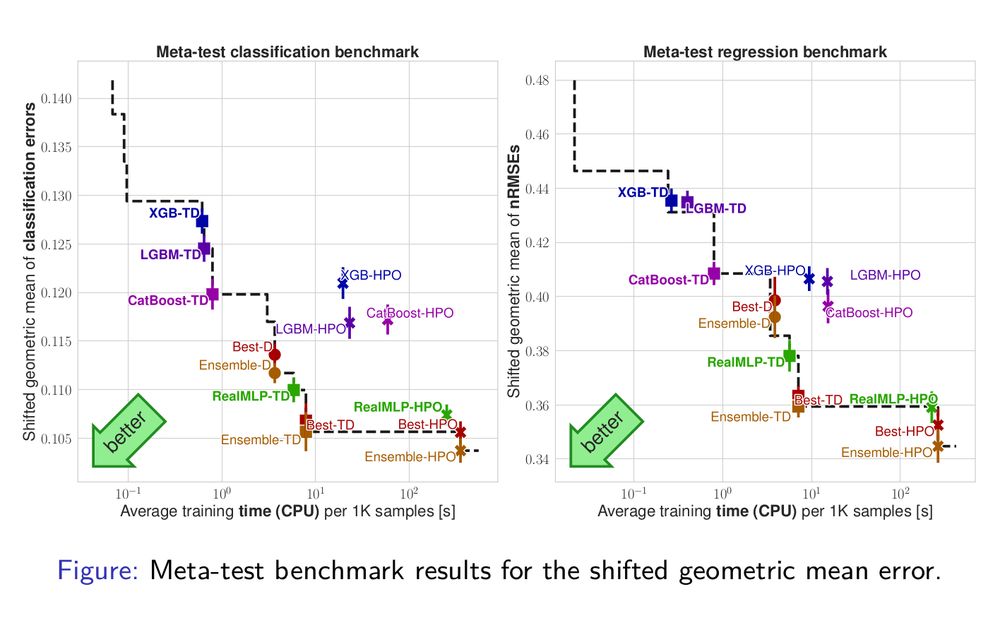
Depending on the benchmark and metrics/aggregation, RealMLP is sometimes a bit better than boosted trees and sometimes a bit worse.
Generally, taking the best TD model (Best-TD) on each dataset typically has a better time-accuracy trade-off than 50 steps of random search HPO . 7/
Generally, taking the best TD model (Best-TD) on each dataset typically has a better time-accuracy trade-off than 50 steps of random search HPO . 7/
November 18, 2024 at 2:15 PM
Depending on the benchmark and metrics/aggregation, RealMLP is sometimes a bit better than boosted trees and sometimes a bit worse.
Generally, taking the best TD model (Best-TD) on each dataset typically has a better time-accuracy trade-off than 50 steps of random search HPO . 7/
Generally, taking the best TD model (Best-TD) on each dataset typically has a better time-accuracy trade-off than 50 steps of random search HPO . 7/
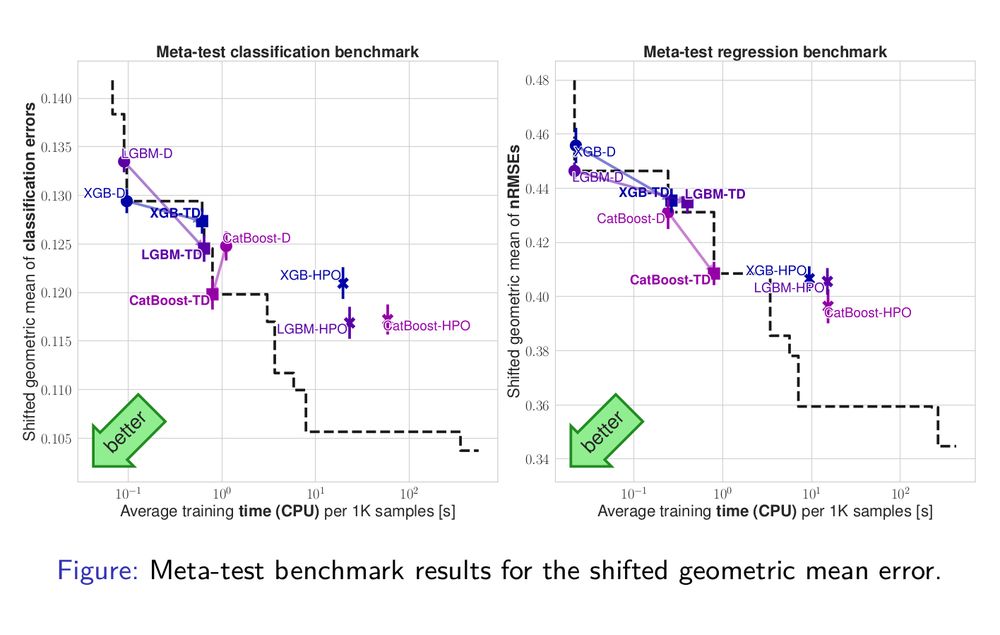
For boosted trees, our tuned defaults (TD) outperform the library defaults (D) in our standard metrics, though they do not match hyperparameter optimization (HPO) on meta-test, and the results are more mixed on other metrics/benchmarks. 6/
November 18, 2024 at 2:15 PM
For boosted trees, our tuned defaults (TD) outperform the library defaults (D) in our standard metrics, though they do not match hyperparameter optimization (HPO) on meta-test, and the results are more mixed on other metrics/benchmarks. 6/
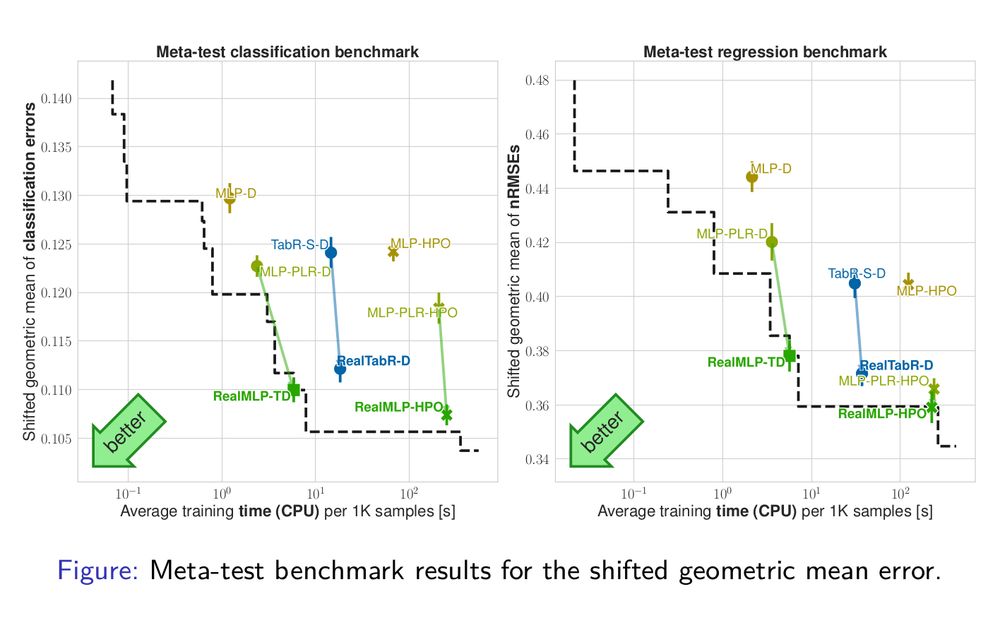
To test if our “bag of tricks” transfers to other architectures, we try some of the tricks on the retrieval-based TabR-S-D, with much less tuning than for RealMLP-TD.
The resulting RealTabR-D performs much better than the default parameters from the original paper. 5/
The resulting RealTabR-D performs much better than the default parameters from the original paper. 5/
November 18, 2024 at 2:15 PM
To test if our “bag of tricks” transfers to other architectures, we try some of the tricks on the retrieval-based TabR-S-D, with much less tuning than for RealMLP-TD.
The resulting RealTabR-D performs much better than the default parameters from the original paper. 5/
The resulting RealTabR-D performs much better than the default parameters from the original paper. 5/
RealMLP can be used with tuned defaults (TD) or hyperparameter optimization (HPO).
We tuned defaults and our “bag of tricks” only on meta-train. Still, RealMLP outperforms the MLP-PLR baseline with numerical embeddings on all benchmarks. 4/
We tuned defaults and our “bag of tricks” only on meta-train. Still, RealMLP outperforms the MLP-PLR baseline with numerical embeddings on all benchmarks. 4/
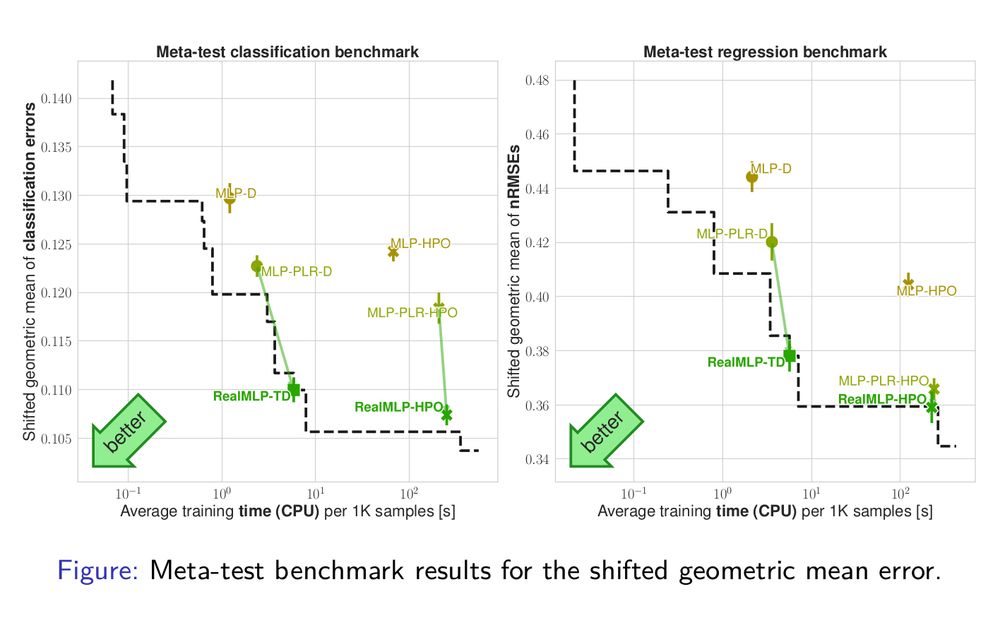
November 18, 2024 at 2:15 PM
RealMLP can be used with tuned defaults (TD) or hyperparameter optimization (HPO).
We tuned defaults and our “bag of tricks” only on meta-train. Still, RealMLP outperforms the MLP-PLR baseline with numerical embeddings on all benchmarks. 4/
We tuned defaults and our “bag of tricks” only on meta-train. Still, RealMLP outperforms the MLP-PLR baseline with numerical embeddings on all benchmarks. 4/
Our new methods and default parameters are tuned on a meta-train benchmark and then also evaluated on
- a disjoint meta-test benchmark including large and high-dimensional datasets
- the smaller Grinsztajn et al. benchmark (with more baselines). 3/
- a disjoint meta-test benchmark including large and high-dimensional datasets
- the smaller Grinsztajn et al. benchmark (with more baselines). 3/
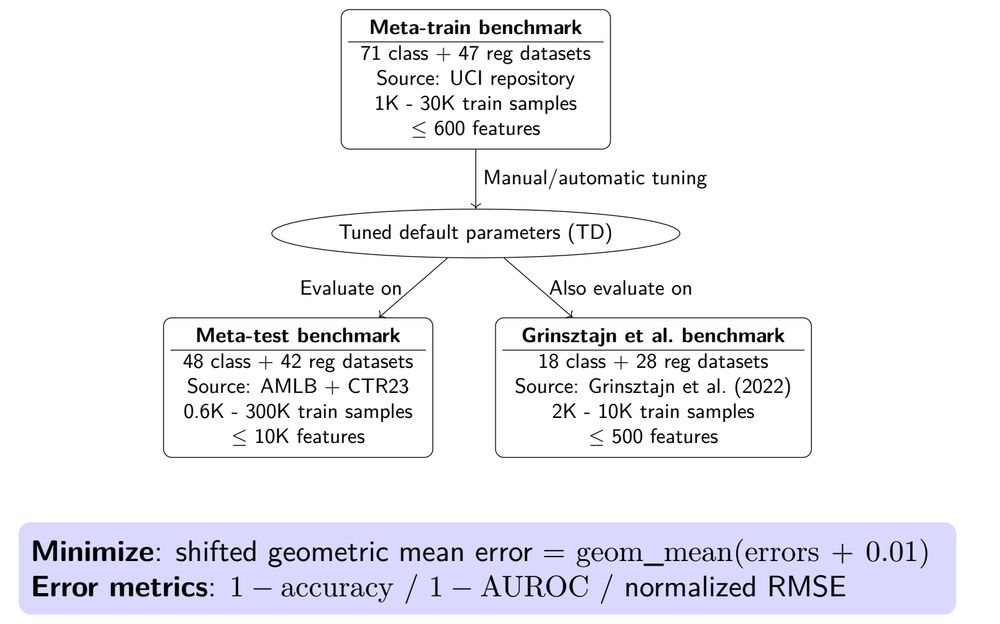
November 18, 2024 at 2:15 PM
Our new methods and default parameters are tuned on a meta-train benchmark and then also evaluated on
- a disjoint meta-test benchmark including large and high-dimensional datasets
- the smaller Grinsztajn et al. benchmark (with more baselines). 3/
- a disjoint meta-test benchmark including large and high-dimensional datasets
- the smaller Grinsztajn et al. benchmark (with more baselines). 3/
Coauthors: Léo Grinsztajn (@leogrin.bsky.social) and Ingo Steinwart
Paper: arxiv.org/abs/2407.04491
Code: github.com/dholzmueller...
Our library is pip-installable and contains easy-to-use and configurable scikit-learn interfaces (including baselines). 2/
Paper: arxiv.org/abs/2407.04491
Code: github.com/dholzmueller...
Our library is pip-installable and contains easy-to-use and configurable scikit-learn interfaces (including baselines). 2/
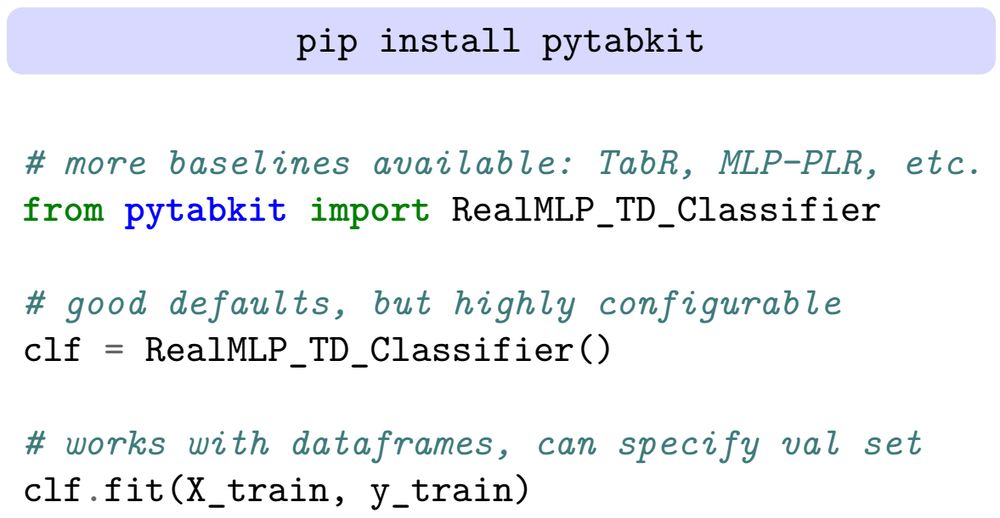
November 18, 2024 at 2:15 PM
Coauthors: Léo Grinsztajn (@leogrin.bsky.social) and Ingo Steinwart
Paper: arxiv.org/abs/2407.04491
Code: github.com/dholzmueller...
Our library is pip-installable and contains easy-to-use and configurable scikit-learn interfaces (including baselines). 2/
Paper: arxiv.org/abs/2407.04491
Code: github.com/dholzmueller...
Our library is pip-installable and contains easy-to-use and configurable scikit-learn interfaces (including baselines). 2/
Can deep learning finally compete with boosted trees on tabular data? 🌲
In our NeurIPS 2024 paper, we introduce RealMLP, a NN with improvements in all areas and meta-learned default parameters.
Some insights about RealMLP and other models on large benchmarks (>200 datasets): 🧵
In our NeurIPS 2024 paper, we introduce RealMLP, a NN with improvements in all areas and meta-learned default parameters.
Some insights about RealMLP and other models on large benchmarks (>200 datasets): 🧵

November 18, 2024 at 2:15 PM
Can deep learning finally compete with boosted trees on tabular data? 🌲
In our NeurIPS 2024 paper, we introduce RealMLP, a NN with improvements in all areas and meta-learned default parameters.
Some insights about RealMLP and other models on large benchmarks (>200 datasets): 🧵
In our NeurIPS 2024 paper, we introduce RealMLP, a NN with improvements in all areas and meta-learned default parameters.
Some insights about RealMLP and other models on large benchmarks (>200 datasets): 🧵
The video and slides of my talk are online (link is in the quoted tweet). 📽️ https://twitter.com/DHolzmueller/status/1831385303405281347

November 19, 2024 at 11:35 AM
The video and slides of my talk are online (link is in the quoted tweet). 📽️ https://twitter.com/DHolzmueller/status/1831385303405281347